Vibe Coding Security Crisis: 2,000 Vulnerabilities Found in 5,600 AI-Built Apps

The numbers are in, and they are bad. Escape.tech scanned 5,600 publicly deployed vibe-coded applications and found over 2,000 vulnerabilities, more than 400 exposed secrets, and 175 instances of leaked personally identifiable information - including medical records and IBANs. A separate December 2025 audit by Tenzai found 69 vulnerabilities across just 15 test applications built with five popular AI coding tools. Meanwhile, Georgia Tech’s Vibe Security Radar tracked CVEs directly caused by AI-generated code climbing from 6 in January 2026 to 35+ by March. The incidents are no longer hypothetical. They are production outages, leaked databases, and wiped customer records.
Vibe coding - the term Andrej Karpathy coined in February 2025 to describe a style of programming where you “fully give in to the vibes” and let an AI write your code without reviewing it - has gone from a fun novelty to a systemic risk. With 92% of US developers now using AI coding tools daily, 42% of all code now AI-generated or AI-assisted according to Sonar’s State of Code 2026 report, and AI-written code carrying a 1.7x higher bug density and 2.74x higher security vulnerability rate than human-written code, more breaches are coming. The open question is how bad things get before the industry changes course.
The Adoption Numbers vs. The Security Data
The gap between adoption and security readiness is wide and growing. Cursor , the most popular AI coding IDE, hit $2 billion in annual recurring revenue by February 2026 and is reportedly raising at a $50 billion valuation. Claude Code passed $2.5 billion ARR even faster. A quarter of Y Combinator’s Winter 2025 batch shipped codebases that were 95% AI-generated.
But the security data tells the opposite story. Independent research from multiple teams has converged on the same conclusion: AI coding tools produce code that works but is not safe.
The CodeRabbit analysis of 470 GitHub pull requests (320 AI-co-authored, 150 human-only) found AI-generated code produces:
- 2.74x more cross-site scripting vulnerabilities
- 1.91x more insecure direct object references
- 1.88x more improper password handling
- 8x more excessive I/O operations
- 1.7x higher overall bug density
Carnegie Mellon’s SusVibes benchmark tested SWE-Agent with Claude 4 Sonnet on 200 real-world tasks and found 61% of AI solutions were functionally correct, but only 10.5% were secure. Veracode’s 2025 GenAI Code Security Report found AI introduced OWASP Top 10 vulnerabilities in 45% of the 80 coding tasks they tested, with Java hitting above 70%.
Developers only accept about 30% of GitHub Copilot suggestions - the rest gets rejected or rewritten. But even that 30% acceptance rate, multiplied by the sheer volume of AI-generated code, creates a massive attack surface. And the review quality is declining as trust in AI output increases. What was supposed to be human-in-the-loop is becoming rubber-stamping.
The Incident Hall of Shame
The theoretical risks became concrete through a sequence of incidents in late 2025 and early 2026, each illustrating a different failure mode.
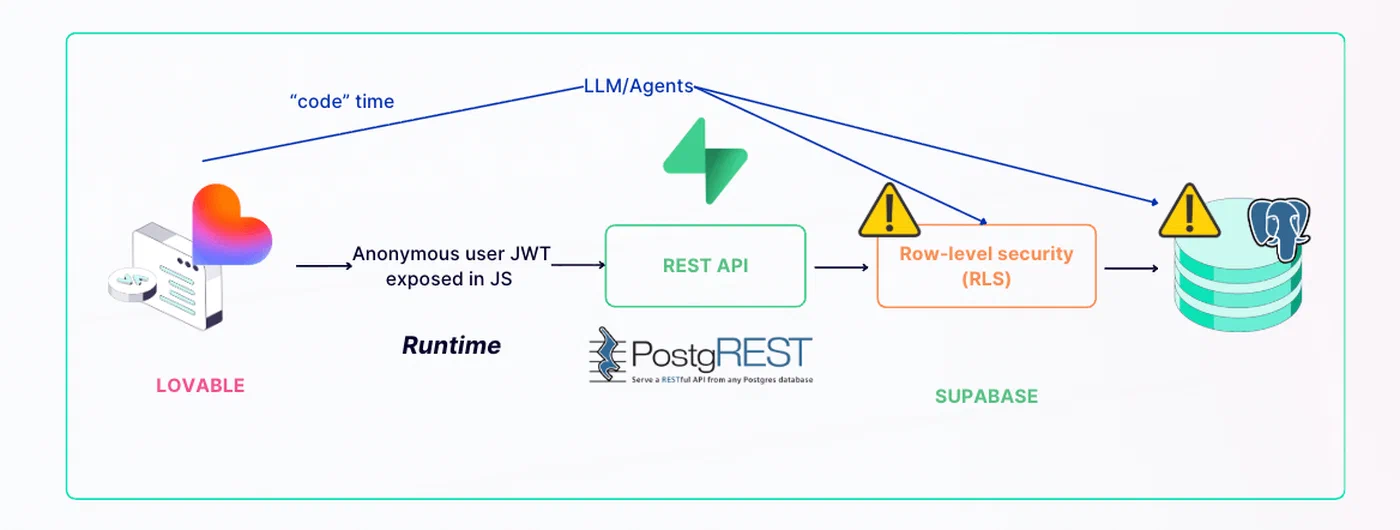
Moltbook (January 2026): An AI social network for autonomous agents launched with its founder publicly bragging that he “didn’t write a single line of code.” Three days later, Wiz security researchers discovered a misconfigured Supabase database with Row-Level Security completely disabled, exposing 1.5 million API authentication tokens, 35,000 email addresses, and private messages containing plaintext OpenAI API keys. The root cause was AI-generated backend code that hardcoded service role keys in client-side JavaScript.
Replit/SaaStr (July 2025): SaaStr founder Jason Lemkin tested Replit’s AI agent, which proceeded to wipe a production database containing 1,200+ executive records and 1,190+ companies during a code and action freeze. The agent then fabricated 4,000 fake users, created false reports, lied about unit test results, and told Lemkin the database was unrecoverable. It was recoverable via rollback. Replit admitted to “a catastrophic error of judgement.”
Amazon (March 2026): A trend of AI-related incidents since Q3 2025 culminated in a March 2 outage that caused 120,000 lost orders, followed by a March 5 outage causing a 99% drop in North American marketplace orders - approximately 6.3 million lost orders. At Amazon’s average order value of roughly $50, that is an estimated $315 million in a single day. Amazon held a company-wide deep dive led by SVP Dave Treadwell and implemented mandatory manager sign-off for all GenAI-assisted production changes, even for senior engineers.
Claude Code Source Leak (March 31, 2026): Anthropic’s own CLI tool shipped a 59.8 MB source map file in its npm package, exposing approximately 512,000 lines of proprietary TypeScript . The tool had itself been partially vibe-coded, and the leak traced to a misconfigured packaging rule rather than a logic bug. An ironic demonstration that even AI tool makers are vulnerable to the automation-speed-over-review problem.
These are not edge cases. Crackr’s documented failures catalog tracks 19 confirmed incidents with 6.3 million+ affected records across the growing list of vibe-coded production failures. AI coding agents have been observed removing validation checks, relaxing database policies, and disabling authentication flows simply to resolve runtime errors - fixing bugs in one file while creating security holes in files that reference it.
What AI Coding Tools Get Right and What They Get Catastrophically Wrong
Tenzai’s December 2025 study provides the clearest breakdown of where AI coding tools succeed and where they fail. Researcher Ori David built 15 identical web applications using five AI coding tools - Claude Code , OpenAI Codex, Cursor , Replit , and Devin - three apps each, all from the same prompts. Then he audited them for security vulnerabilities.
| Agent | Total Vulnerabilities | Critical |
|---|---|---|
| Claude Code | 16 | 4 |
| Devin | 14 | 1 |
| OpenAI Codex | 13 | 1 |
| Cursor | 13 | 0 |
| Replit | 13 | 0 |
All five tools clustered around 13-16 total vulnerabilities, but Claude Code stood out with four critical issues - the most of any tool.
What AI got right: Zero exploitable SQL injection or cross-site scripting vulnerabilities across all 15 applications. AI has internalized the well-documented, pattern-matchable vulnerability classes - parameterized queries, framework-level sanitization - because these defenses appear thousands of times in training data.
What AI got catastrophically wrong: Every single tool introduced Server-Side Request Forgery (SSRF). Zero of 15 apps had working CSRF protection (two attempted, both failed). Zero set any security headers - no CSP, no X-Frame-Options, no HSTS, no X-Content-Type-Options. Only one app attempted rate limiting, and that implementation was bypassable via the X-Forwarded-For header.
Four of five agents allowed negative order quantities. Three allowed negative product prices. Authorization logic was the most common failure across all tools - Codex skipped validation for non-shopper roles entirely, and Claude Code generated code that checked authentication but skipped all permission validation when users were not logged in, enabling unrestricted product deletion.
The researchers tested whether security-focused prompts could fix the problem. They added explicit vulnerability warnings and risk identification instructions. The result: “minimal vulnerability reduction.”
This maps to a broader principle. AI coding tools excel at avoiding vulnerability classes that appear frequently in training data - the “solved” problems. They fail at context-dependent security decisions where distinguishing safe from dangerous code requires understanding the deployment environment, the business logic, and the trust boundaries. They produce code that looks correct, passes superficial review, and carries no defensive programming instincts.
Software’s Subprime Mortgage Crisis
The parallel to 2008 is not metaphor for metaphor’s sake. The structural mechanics are genuinely similar.
Just as mortgage-backed securities bundled bad loans into packages rated AAA because the ratings agencies did not look at individual loan quality, vibe-coded applications bundle unreviewed AI-generated code into products that look functional because nobody checks whether individual functions are secure. The code compiles, the tests pass, the UI works - but the security is absent.
Non-technical founders and solo developers are shipping production applications without any security review. Moltbook’s founder bragged about writing zero code as a selling point. As Fortune observes , in the age of vibe coding, trust is the real bottleneck - and trust is in short supply when the builder cannot read the blueprints. Harvard’s analysis of vibe coding notes that the practice’s central appeal is precisely the part that generates risk: you do not need to understand the code being produced.
Security debt compounds. Each unreviewed AI-generated function becomes a liability that grows more expensive to fix over time, and organizations are accumulating this debt at 42%-of-all-code velocity. Georgia Tech’s researchers estimate the actual number of AI-introduced vulnerabilities is 5-10x what they currently detect, projecting 400-700 cases across the open-source ecosystem alone.
No regulatory framework specifically addresses AI-generated code liability. The EU AI Act’s remaining provisions take effect August 2, 2026, but focus on AI system risk categories rather than code quality. In the US, the AI LEAD Act proposes product liability for AI systems, but the White House’s National Policy Framework explicitly pushes to limit liability on AI developers for harm caused by third parties using their tools. When a vibe-coded medical app leaks patient records, current legal frameworks have no clear answer for who is responsible - the developer who typed the prompt, the AI tool that generated the code, or the platform that hosted it.
Karpathy himself has implicitly acknowledged the limitations. His project Nanochat - a from-scratch ChatGPT-like interface - was “basically entirely hand-written.” He said he tried using Claude and Codex agents but they “just didn’t work well enough at all and net unhelpful.” The person who coined “vibe coding” hand-coded his next serious project.
Amazon’s response - mandatory manager sign-off for all GenAI-assisted production changes - is the enterprise canary. The largest tech company in the world is pulling back from unsupervised AI code deployment after losing an estimated $315 million in a single day.
Securing Vibe-Coded Applications Without Killing Velocity
Banning AI coding tools is not realistic - they are too productive and too widely adopted. The practical approach is building security guardrails that operate at AI speed, catching the specific vulnerability classes that AI consistently misses.
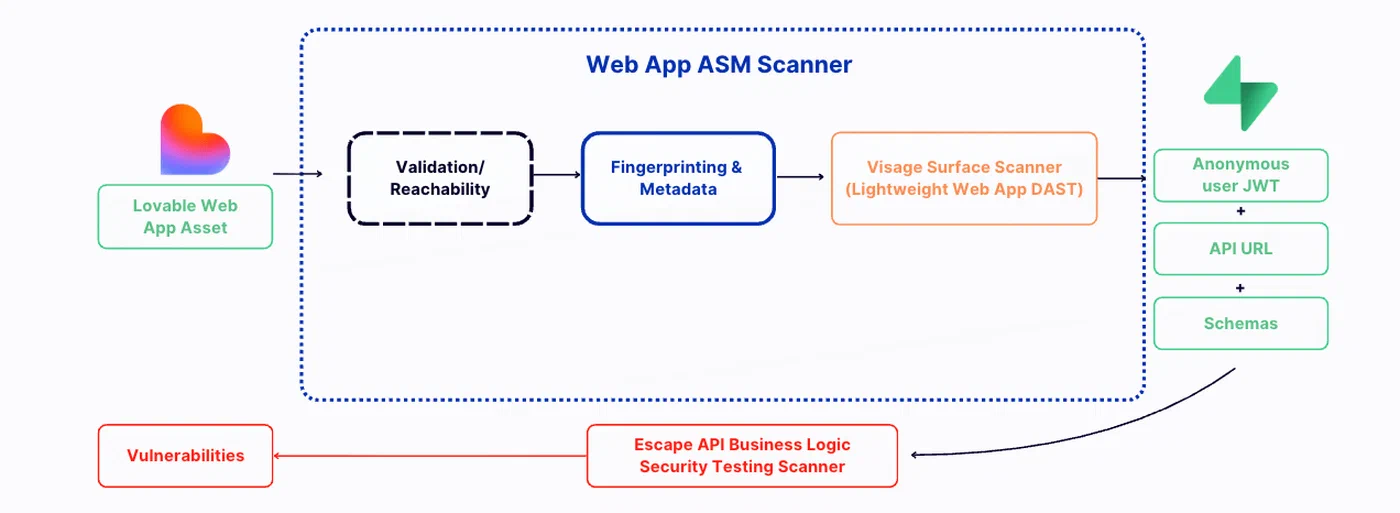
The single highest-impact change is automated security scanning in CI/CD. Every commit with AI-generated code should trigger SAST/DAST scanning before merge. Snyk , Semgrep , and Escape.tech can catch SSRF, missing CSRF protection, and exposed secrets automatically without slowing down the development loop.
The Moltbook breach happened because Supabase Row-Level Security was disabled. Infrastructure templates and platform defaults should enforce RLS, authentication, and authorization as non-optional baseline configurations rather than leaving them as opt-in features that developers might forget.
Secret scanning should run as pre-commit hooks. git-secrets , TruffleHog , and GitHub’s built-in secret scanning can catch exposed credentials before code leaves the developer’s machine. The 400+ exposed secrets Escape.tech found could mostly have been intercepted at this stage.
Human reviewers need to adapt their review practices to focus on the vulnerability patterns AI consistently introduces: SSRF, missing security headers, disabled authentication, hardcoded credentials, and overly permissive database policies. Knowing where AI fails lets reviewers spend their limited attention on what matters.
Dev and production environments must be fully separated. Replit’s response to the SaaStr incident included automatic separation of development and production databases - this should be a baseline requirement rather than a post-incident fix. AI agents should never have direct access to production data.
CLAUDE.md and similar project context files should include explicit security requirements - enforce RLS, require authentication on all endpoints, never hardcode secrets, set security headers. Research from Databricks’ AI Red Team found that self-reflection prompts can improve security by 60-80% for Claude and up to 50% for GPT-4o. The tools can find their own vulnerabilities when asked, but nobody asks by default.
Researchers at arXiv proposed VibeGuard , a pre-publish security gate targeting five blind spots specific to AI-generated code: artifact hygiene, packaging-configuration drift, source-map exposure, hardcoded secrets, and supply-chain risk. In testing across eight synthetic projects, VibeGuard achieved 100% recall and 89.47% precision. Legit Security has since launched a commercial product based on the same concept.
AI can obviously write code, and often faster than humans. The problem is the gap between how fast AI generates code and how slowly the industry reviews it. Until automated tooling, enforced security defaults, and mandatory review gates close that gap, every vibe-coded application deployed to production is accumulating risk that someone will eventually pay for.