The 80% Coverage Trap: Why AI-Generated Tests Create a False Sense of Security

AI test generators make it easy to hit 80% or even 90%+ line coverage. Point GitHub Copilot
at a codebase, use the @Test directive, and watch it write hundreds of test methods by itself. The number looks great on a dashboard. But line coverage only measures execution, not detection. A test suite can run every line of your code while checking nothing about whether that code is correct. In one 2026 experiment, an AI-built suite scored 93.1% line coverage but only 58.6% on mutation testing. Over a third of realistic bugs slipped through undetected, with CI green across the board.
This is important because AI test generation is spreading fast. In the Automation Guild 2026 pre-event survey , 72.8% of testing professionals picked “AI-powered testing and autonomous test generation” as their top priority. Tools like Copilot Testing for .NET (GA in Visual Studio 2026 v18.3), Qodo Gen , and BlinqIO now build whole test suites from source code. Most teams will use AI for testing within a year or two. The real question: will they see that the coverage number these tools produce says almost nothing about test quality?
The Coverage Number Everyone Celebrates (and Why It Lies)
Line coverage became the default stand-in for test quality decades ago, and for good reason at the time. It was the easiest metric to collect. It tracked loosely with fewer production bugs. And it gave managers a number to put on a slide. AI tools have turned it into a vanity metric by making it too easy to hit.
Line coverage measures whether a line ran during a test. It does not measure whether the test checked that line’s behavior. A test that calls a function without checking its return value counts as “covered.” A test that asserts assertNotNull(result) on a method that should return a specific value counts as “covered.” A test that catches an exception and asserts assertTrue(true) counts as “covered.”
AI-generated tests tend to produce exactly these patterns. They reverse-engineer assertions from current behavior, not from a spec. The AI reads the code, sees what it does, and writes tests that confirm the code does what it does. That is circular validation. If the code has a bug, the AI-generated test will mark the buggy behavior as correct.
The CodeRabbit State of AI vs Human Code Generation report looked at 470 real pull requests. It found that AI-generated PRs hold 1.7x more issues than human-written ones (10.83 vs 6.45 per PR), with 1.4x more critical defects and 75% more logic errors. These defects survive because the test suites that ship with them don’t catch them. The tests run the code, the coverage number goes up, and the bugs ship.
A 60% coverage suite with careful boundary assertions, null checks, and error path tests catches more real bugs than a 90% suite full of assertNotNull and assertTrue(result != null) boilerplate. The first suite was written by someone who knew what the code should do. The second was written by an AI that only knew what the code does today.
The 93% to 58% Gap: What Mutation Testing Reveals
Mutation testing is the lie detector for test suites. It injects small, realistic faults, called “mutants,” into source code: flipped booleans, swapped comparison operators, removed return values, changed arithmetic signs. Then it runs the existing test suite against each mutant. If a test fails, the mutant is “killed”: the test caught the fake bug. If all tests pass, the mutant “survives,” and a real bug with that same shape could ship undetected.
In a 2026 multi-agent adversarial experiment, the gap between coverage theater and real detection was wide:
| Metric | Score |
|---|---|
| Line coverage (AI-generated suite) | 93.1% |
| Mutation score (same suite, Stryker) | 58.6% MSI |
| Gap | 34.5 percentage points |
| Surviving mutants (services layer) | ~48 of 116 |
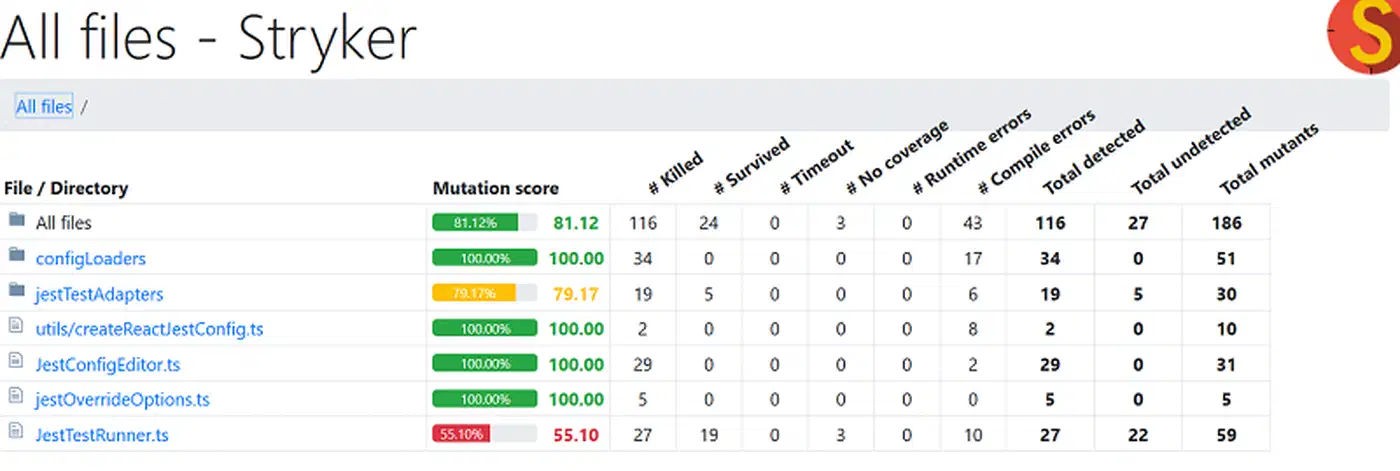
That 34-point gap is the slice of the codebase where a developer (or an AI) can add a bug, all tests pass, and CI goes green with zero warning. Nearly half the injected faults in the services layer went undetected.
The fix in that experiment took three rounds of targeted assertion work, each guided by surviving mutant reports:
- Replacing presence checks (
assertNotNull) with correctness checks (assertEquals(expected, actual)) - Adding boundary tests for off-by-one errors and edge values
- Checking error paths: confirming the right exception type is thrown with the right message, not just that “some exception” was thrown
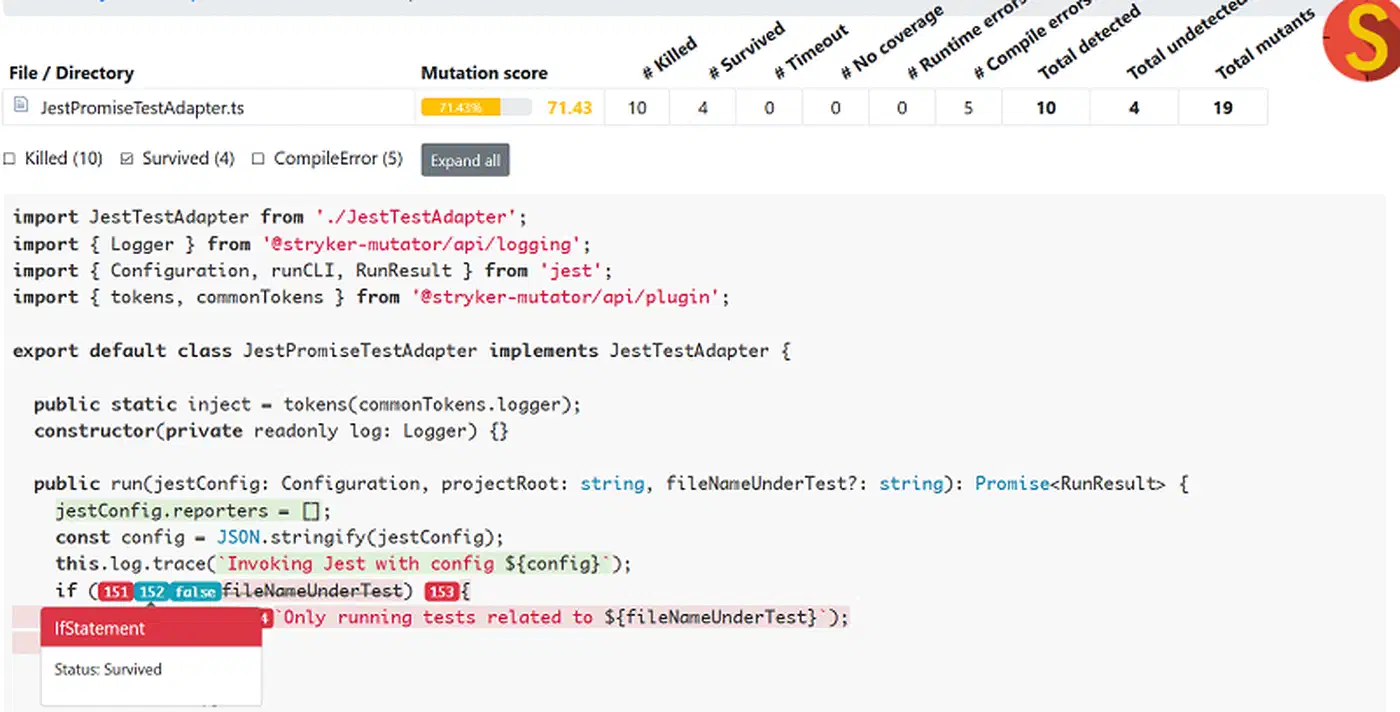
After three rounds, the mutation score climbed from 58.6% to 93.1% MSI, matching the line coverage number. The same AI that wrote the weak tests wrote strong ones once it had the mutation report. The surviving mutant report told the AI where its tests were blind, and the AI fixed those blind spots.
The key tools for mutation testing are Stryker for .NET and JavaScript/TypeScript, PIT for Java, and Cosmic Ray for Python. None of these are AI-specific, but they pair well with any AI test generation workflow. A new 2026 industry bar aims for 80%+ mutation score on critical business logic. Most teams treat anything below 70% as a red flag, no matter how high the line coverage number is.
The 2026 AI Testing Tool Landscape
The AI testing market has split into four groups, each solving a different part of the quality problem. Knowing which group you need stops you from buying a coverage tool when you need a validation tool.
Autonomous test generation tools write test code from source analysis. GitHub Copilot Testing for .NET
(GA in Visual Studio 2026 v18.3) uses the @Test directive in Copilot Chat. It reads code, creates test projects, and runs tests across xUnit, NUnit, and MSTest. BlinqIO
’s AI Test Engineer takes test descriptions, navigates the app on its own, and writes real Playwright
code into your Git repo. Qodo Gen
takes a behavior-driven approach. It reads function signatures, type annotations, and logic to write tests that cover distinct behavior, not just lines.
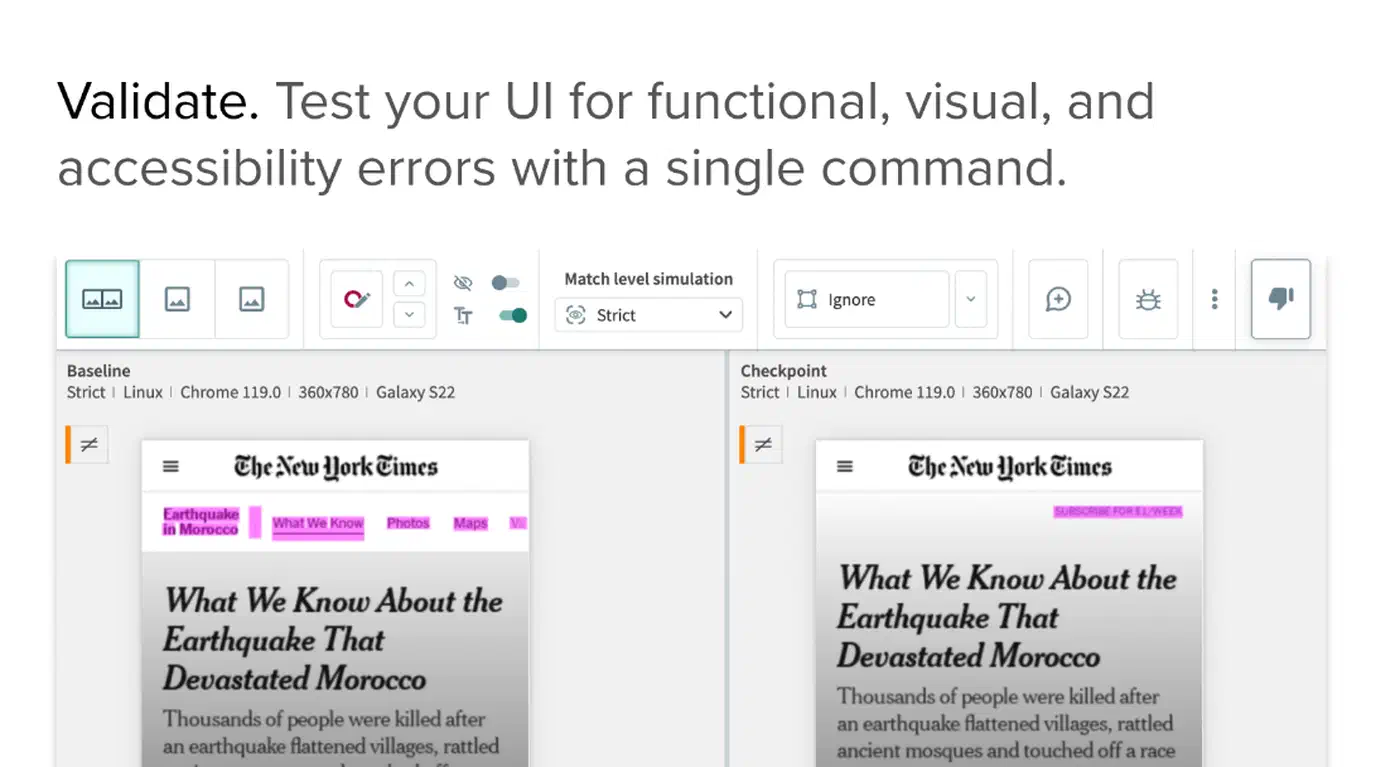
Visual validation tools catch what unit tests by design cannot. Applitools leads this group with AI trained on millions of screenshots. It spots layout shifts, cross-browser quirks, and visual regressions. It was named a Strong Performer in the Forrester Wave: Autonomous Testing Platforms, Q4 2025.
Self-healing execution tools cut upkeep costs when UIs change. Perfecto (Perforce) and Virtuoso QA auto-fix broken locators. Virtuoso reports roughly 95% auto-fix accuracy, cutting test upkeep costs by up to 85%.
Codeless/NLP-driven tools make test creation easier. Testsigma turns plain English test descriptions into runnable tests across web, mobile, and API surfaces. Mabl shipped Auto TFA (Autonomous Test Failure Analysis) in early 2026. It triages test failures and pushes root-cause insights into Jira or the IDE.
The key split: autonomous generation tools aim for coverage breadth. Visual validation and mutation testing tools aim for detection depth. Most teams need both.
| Category | Example Tools | Optimizes For | Catches |
|---|---|---|---|
| Autonomous generation | Copilot Testing, BlinqIO, Qodo | Coverage breadth | Missing test cases |
| Visual validation | Applitools | UI correctness | Layout/rendering bugs |
| Self-healing | Virtuoso, Perfecto | Maintenance reduction | Broken selectors |
| Mutation testing | Stryker, PIT, Cosmic Ray | Detection depth | Weak assertions |
For a wider look at each tool with pricing and language support, the Best AI Test Generation Tools in 2026 guide on Dev.to covers nine tools in detail.
Building a Test Strategy That Survives the Coverage Trap
The teams that catch bugs in production treat coverage as a floor, not a ceiling. They stack other quality signals on top of it.
Layer 1 - AI-generated baseline. Let AI tools build the first test suite, aiming for 80%+ line coverage. This is commodity work. There is no reason to hand-write boilerplate setUp, tearDown, and happy-path tests anymore. Use Copilot, Qodo, or your tool of choice, then move on to the work that counts.
Layer 2 - Mutation testing gate. Run Stryker , Cosmic Ray, or PIT on critical modules. Set a CI gate at 80% mutation score minimum. If the AI suite scores below that, feed the surviving mutant report back to the AI and let it sharpen its assertions. This feedback loop is where AI test generation gets powerful: each round writes better tests because the mutation report shows the AI where its coverage is hollow.
Stryker is tuned for CI pipelines. It compiles all mutants at once with conditional switches rather than one build per mutation. It also groups non-overlapping mutants into the same test session to cut overhead. Incremental mode tests only changed files, dropping CI time from 45 minutes to about 18 minutes in reported benchmarks. The practical setup: run incremental mutation analysis on every PR and full analysis as a nightly job.
Layer 3 - Human-authored edge cases. Humans write tests for business logic rules, security boundaries, concurrency cases, and integration contracts that AI keeps missing. The 2026 survey shows 67% of testing professionals trust AI-generated tests only with human review, and they are right to. AI doesn’t know what your business rules should be. It only knows what your code does today.
Layer 4 - Visual and behavioral validation. Add Applitools or an equal for UI-facing code. It catches the kind of regressions that unit tests cannot reach. A function can return the right data while the CSS renders it in white text on a white background.
The feedback loop between layers is what makes this strategy work. Mutation reports from Layer 2 become prompts for Layer 1. Each AI-generated test round comes out better than the last. Surviving mutant reports are, in effect, the perfect prompt for an AI test generator: they say exactly what behavior needs to be asserted and where.
The anti-pattern to avoid: using coverage percentage as a team performance metric. When coverage becomes a KPI, developers and AI tools game it with trivial tests that pump the number without raising quality. Track mutation score on critical modules instead. It is harder to game, because a test that doesn’t assert real behavior will not kill mutants.
There is also a security angle here. Research from Veracode found that AI-generated Java code showed a 72% security failure rate across tasks. AI-generated code that passes unit tests can still hold injection flaws, insecure deserialization, or broken authentication. Security testing (SAST, DAST, penetration testing) has to stay separate from coverage, because functional correctness and security correctness are different things. The agent that writes those tests is itself an attack surface, since AI coding agents face prompt injection and MCP exploits that can poison the code it generates.
Coverage Theater vs. Real Quality
The coverage number on your dashboard is an execution metric, not a quality metric. It tells you what ran, not what was checked. AI test generation has made this split more urgent than ever, because teams can now hit 90% coverage overnight and call it a win without seeing that a third of their realistic bugs would still ship.
Mutation testing closes the gap. The experiment that went from 93.1% line coverage / 58.6% mutation score to 93.1% line coverage / 93.1% mutation score did it by feeding surviving mutant reports back to the AI for three rounds of assertion fixes. The tools exist. The workflow is simple. The only barrier is seeing that the coverage number you’re celebrating might be lying to you.
The strongest test suites in 2026 come from teams that use AI for the first suite and the happy paths, then layer human judgment on top for business rules, security boundaries, and integration contracts. Mutation score, not line coverage, is the metric that tells you whether this combination works.