Gemma 4 vs Qwen 3.5 vs Llama 4: Which Open Model Should You Actually Use? (2026)

For most developers in 2026, Gemma 4 31B is the best all-around open model. It ranks #3 on the LMArena leaderboard, scores 85.2% on MMLU Pro, and ships under Apache 2.0 with zero usage restrictions. Qwen 3.5 27B edges it on coding benchmarks - 72.4% on SWE-bench Verified versus Gemma 4’s strength in math reasoning - and its Omni variant offers real-time speech output that no other open model matches. Llama 4 Maverick (400B MoE) wins on raw scale but requires datacenter hardware and carries Meta’s restrictive 700M MAU license. Pick Gemma 4 for the best quality-to-size ratio under a true open-source license, Qwen 3.5 for coding-heavy workflows, and Llama 4 only when you need the largest available open model and can absorb the legal overhead.
The Contenders - Model Specs at a Glance
Before comparing output quality, it helps to understand what each family actually looks like under the hood. These three model families differ in architecture, parameter counts, and release philosophy, and those differences shape everything from hardware requirements to deployment options.
Gemma 4 (released April 2, 2026) comes in four sizes: E2B (2.3B effective), E4B (4.5B effective), a 26B MoE model that activates only 3.8B parameters per token, and a 31B dense model. All variants ship under Apache 2.0 with 128K-256K context windows. The edge models (E2B and E4B) support text, image, and audio input. The larger models handle text, image, and video (up to 60 seconds at 1fps) but oddly lack audio input.

Qwen 3.5 (released February 16, 2026) centers on a 27B dense flagship model, with the family spanning from 0.8B to 397B parameters. The Qwen 3.5-Omni variant (released March 30) adds multimodal input across text, image, audio, and video - and is the only model in this comparison that can produce real-time streaming speech output. Licensed under Apache 2.0 with 128K context.
Llama 4 (initial release April 5, 2025, with LlamaCon updates) offers Scout (17B active / 109B MoE) and Maverick (17B active / 400B MoE). Scout claims a 10M+ token context window - the largest of any open model. Both variants support text and image input only. Licensed under the Llama 4 Community License, which is free for companies under 700M monthly active users but comes with compliance requirements.
A key architectural difference: Gemma 4’s 26B MoE model activates 3.8B parameters per token while Llama 4’s Maverick activates 17B per token. Both are labeled “MoE” but the compute profiles are wildly different.
| Feature | Gemma 4 | Qwen 3.5 | Llama 4 |
|---|---|---|---|
| Release | April 2, 2026 | Feb 16, 2026 | April 5, 2025 |
| Flagship Size | 31B dense | 27B dense | Maverick 400B MoE |
| Smallest Model | E2B (2.3B) | 0.8B | Scout (109B total) |
| License | Apache 2.0 | Apache 2.0 | Llama Community (700M MAU) |
| Max Context | 256K | 256K | 10M+ (Scout) |
| Modalities | Text, image, video, audio* | Text, image, video, audio | Text, image only |
*Audio input limited to E2B/E4B edge models.
Benchmark Showdown - Numbers That Matter
Benchmarks are flawed and everyone knows it, but they remain the most consistent way to compare models across labs. Here is how the flagships stack up on the evaluations that get cited most often.
| Benchmark | Gemma 4 31B | Qwen 3.5 27B | Llama 4 Maverick 400B |
|---|---|---|---|
| MMLU Pro | 85.2% | 86.1% | 80.5% |
| GPQA Diamond | 84.3% | 85.5% | 69.8% |
| AIME 2026 | 89.2% | ~85% | - |
| LiveCodeBench v6 | 80.0% | 80.7% | 43.4% |
| SWE-bench Verified | - | 72.4% | - |
| Codeforces ELO | 2150 | ~1900 | ~1400 |
| LMArena ELO | ~1452 (#3) | ~1450 (#2 est.) | - |
| MMMU Pro (Vision) | 76.9% | ~72% | ~65% |
Gemma 4 and Qwen 3.5 trade blows at the ~27-31B scale. They are within 1-2% on most reasoning benchmarks, with Qwen 3.5 taking a slight edge on MMLU Pro and GPQA Diamond while Gemma 4 pulls ahead on math reasoning (AIME 2026 at 89.2%) and competitive programming (Codeforces ELO at 2150).
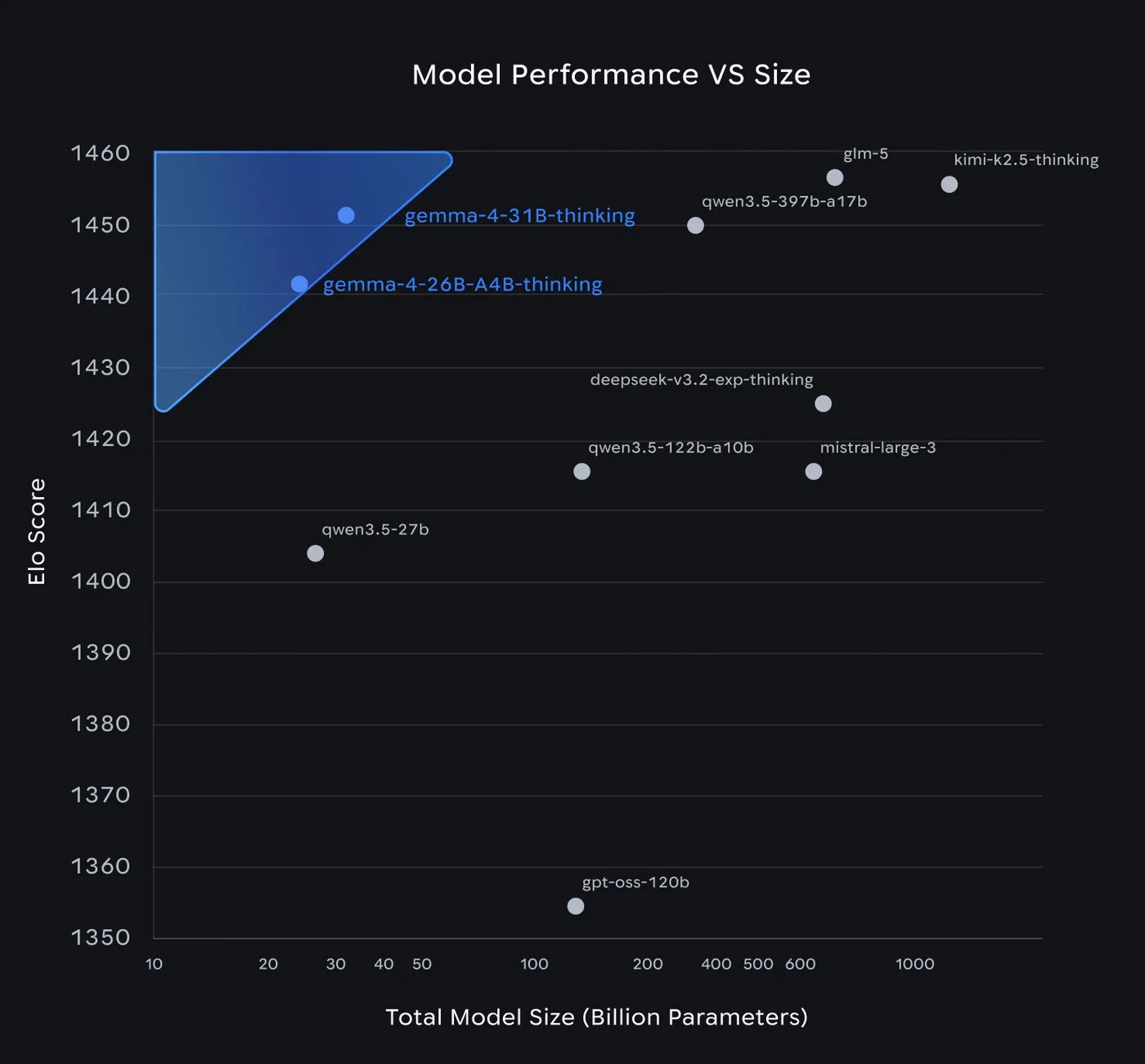
Llama 4 Maverick underperforms on coding despite being roughly 13x larger than either competitor. The 43.4% on LiveCodeBench v6 is particularly striking - MoE routing does not guarantee better code generation, and Maverick’s 17B active parameters per token appear to be spread too thin across the massive expert pool for structured coding tasks.
Qwen 3.5 leads on SWE-bench Verified at 72.4%, which is arguably the most practical coding benchmark because it evaluates real GitHub issue resolution rather than synthetic coding puzzles. If your primary use case involves writing patches, fixing bugs, and working with existing codebases, Qwen 3.5 has a measurable advantage.
The LMArena leaderboard , which relies on crowdsourced human preference votes rather than automated metrics, places Gemma 4 31B at #3 globally among open models. This is the closest proxy for “how good does it actually feel to use,” and it tracks with community sentiment that Gemma 4 produces more natural, less robotic output than its benchmark scores alone might suggest.
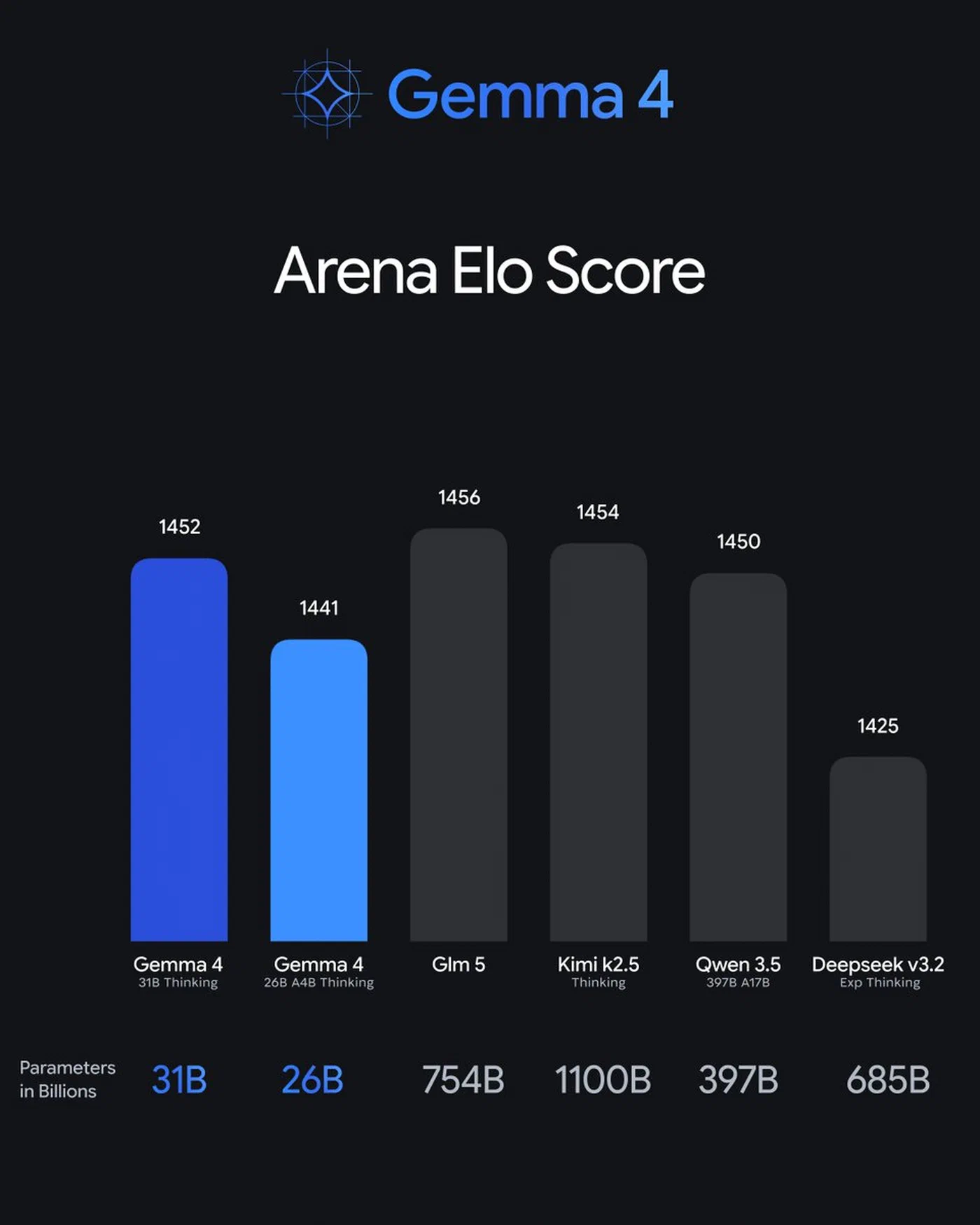
On the MoE efficiency front, Gemma 4’s 26B-A4B model (activating just 3.8B parameters) ranks 6th on the same leaderboard with a score of 1441 - within striking distance of the dense 31B model. Per active parameter, it is the most efficient reasoning engine among current open models.
The License Question - Apache 2.0 vs Llama Community License
Licensing is often the deciding factor for production deployments, and the landscape shifted meaningfully in April 2026.
Gemma 4 and Qwen 3.5 both ship under Apache 2.0. No usage restrictions, no monthly active user limits, no acceptable use policies to comply with. Commercial use, modification, and redistribution are fully permitted. This is the same license used by Linux, Kubernetes, and TensorFlow. For Gemma, this represents a major change - every previous Gemma release (versions 1 through 3) shipped under a custom Google license that deterred enterprise adoption. Hugging Face CEO Clement Delangue called the switch “a huge milestone” that removes legal friction previously pushing teams toward Qwen.
Llama 4 ships under the Llama 4 Community License. It is free for companies under 700 million monthly active users. Beyond that threshold, you need a separate agreement with Meta. The license also requires compliance with Meta’s Acceptable Use Policy, prohibits using the model to train competing foundation models, and requires including the license when redistributing weights.
The practical impact: a startup can ship Gemma 4 or Qwen 3.5 into production without a legal review cycle. Llama 4 requires a license audit, even at modest scale, because the acceptable use policy and redistribution terms need someone to verify compliance. For side projects and experiments this does not matter. For anything touching revenue, it matters a lot.
Multimodal Capabilities - Vision, Audio, and Video
All three families process images natively (not through bolted-on vision adapters), but they diverge sharply on audio and video support.
Gemma 4 E2B/E4B handles text, image, and audio (speech recognition, not music). These edge models use a USM conformer encoder for audio, and Google provides day-zero MediaPipe and LiteRT support for mobile deployment. The larger Gemma 4 models (26B and 31B) handle text, image, and video input up to 60 seconds but cannot process audio - a gap that seems like an oversight given the edge models already have that capability.
Qwen 3.5-Omni handles every modality. It processes text, image, audio, and video input and produces real-time streaming speech output. No other model in this comparison can talk back to you. If you are building a voice assistant, interactive tutor, or any application requiring spoken responses, Qwen 3.5-Omni is currently the only open-weight option.
Llama 4 Scout and Maverick support text and image input only. No audio, no video. This is the most limited multimodal support of the three families.
Gemma 4 also lets you configure the vision token budget between 70 and 1120 tokens per image, trading understanding quality for speed. On MMMU Pro (a vision benchmark), Gemma 4 31B leads at 76.9%.
| Capability | Gemma 4 | Qwen 3.5 | Llama 4 |
|---|---|---|---|
| Image Input | All models | All models | All models |
| Video Input | 26B/31B (up to 60s) | Native | No |
| Audio Input | E2B/E4B only | Omni variant | No |
| Speech Output | No | Omni (real-time streaming) | No |
| Vision Score (MMMU Pro) | 76.9% | ~72% | ~65% |
Inference Speed and Hardware Requirements
A model you cannot run is a model you cannot use. This is where theory meets the reality of your GPU budget.
| Model | Active Params | VRAM (Q4_K_M) | ~tok/s (RTX 4090) |
|---|---|---|---|
| Gemma 4 31B Dense | 30.7B | ~20 GB | ~25 |
| Gemma 4 26B MoE | 3.8B active | ~16 GB | ~11 |
| Qwen 3.5 27B Dense | 27B | ~17 GB | ~35 |
| Llama 4 Scout | 17B active / 109B total | ~70 GB | ~15 |
| Llama 4 Maverick | 17B active / 400B total | 200+ GB | Multi-GPU only |
Qwen 3.5 27B is the speed champion at this parameter class, pushing roughly 35 tokens per second on an RTX 4090 with Q4 quantization. Gemma 4 31B Dense is competitive at around 25 tok/s. Community testing from the first 72 hours after Gemma 4’s release found the 26B MoE model generating only about 11 tokens per second on the same hardware - the MoE routing overhead and the need to load all 25.2B parameters into VRAM explain the disappointing throughput despite the low active parameter count.
Llama 4 Scout at 109B total parameters requires roughly 70 GB of VRAM even with quantization. That effectively makes it a multi-GPU or cloud-only model. Maverick at 400B is firmly in the datacenter tier - you are not running this on consumer hardware.
All three families had day-one support from Ollama , vLLM , llama.cpp , and Hugging Face Transformers, though Gemma 4’s initial fine-tuning tooling (QLoRA via PEFT) had compatibility issues that were patched within hours of release.
One practical note on context window versus VRAM: Gemma 4 31B at Q4 quantization fills about 20 GB of VRAM for the model weights alone. Running the full 256K context window on top of that requires substantially more memory. Community reports indicate fitting only about 20K context tokens on a single RTX 5090 with Gemma 4, whereas Qwen 3.5 27B can reach 190K tokens on the same card. If long context is important to your workflow, Qwen 3.5 is more memory-efficient in practice.
Fine-Tuning and Customization
Fine-tuning support varies across the three families, and this matters if you need to adapt a base model to a domain-specific task.
Gemma 4 launched with some rough edges. Within hours of release, the community discovered that HuggingFace Transformers did not recognize the gemma4 architecture, PEFT could not handle Gemma4ClippableLinear layers, and a new mm_token_type_ids field was required during training. Patches landed quickly in both huggingface/peft and huggingface/transformers, but if you are reading this shortly after release, verify you have the latest library versions before attempting fine-tuning.
Qwen 3.5 benefits from Alibaba’s consistent tooling across Qwen releases. LoRA and QLoRA work out of the box with standard HuggingFace pipelines. The 27B model is the sweet spot for fine-tuning on a single consumer GPU with QLoRA.
Llama 4’s MoE architecture adds complexity to fine-tuning. Training only the active expert parameters is possible but requires careful configuration. Axolotl v0.16.x claims 15x faster and 40x less memory for MoE + LoRA training, which helps, but Scout at 109B total parameters still demands significantly more resources than either Gemma 4 31B or Qwen 3.5 27B.
Cloud API Pricing
If you prefer hosted inference over local deployment, all three model families are available through major cloud providers. Pricing as of April 2026 varies by provider.
Vertex AI offers Gemma 4 models with flexible pricing for inference. Together AI and Fireworks AI host all three families with serverless inference starting at $0.10 per million tokens for smaller models. Together AI tends to be cheaper on roughly half of shared models versus Fireworks. For production workloads requiring dedicated endpoints, expect to pay significantly more, but still far less than equivalent proprietary API calls to GPT-4o or Claude.
The Apache 2.0 license on Gemma 4 and Qwen 3.5 means you can also self-host through any provider without additional licensing overhead. Llama 4 self-hosting still requires compliance with Meta’s license terms regardless of where you deploy.
Decision Framework - Picking the Right Model
Here is which model to pick based on what you actually need.
For a local coding assistant, go with Qwen 3.5 27B. It has the best SWE-bench score, the fastest inference at this size, and good integration with Continue.dev and similar tools.
For general reasoning and chat, Gemma 4 31B is the stronger pick - highest LMArena ELO among open models in this weight class, strongest math reasoning at 89.2% on AIME 2026.
On budget hardware or a laptop, consider Gemma 4 26B MoE or E4B. The MoE model gives near-flagship quality at reduced compute, while E4B fits devices with very limited VRAM.
If you are building a production API or startup product, stick with Gemma 4 or Qwen 3.5 - both Apache 2.0. Llama 4’s license adds legal overhead you probably do not need.
For voice and real-time interaction, Qwen 3.5-Omni is the only option with streaming speech output.
For video understanding, Gemma 4 26B/31B has native video input support with configurable quality.
If you want maximum raw capability and cost is not a factor, Llama 4 Maverick’s 400B MoE gives you the most parameters - but you need datacenter hardware to run it.
For edge, mobile, or IoT deployment, Gemma 4 E2B runs on smartphones and Raspberry Pi while still supporting multimodal input including audio. Google provides official MediaPipe and NVIDIA Jetson support.
If long context (100K+ tokens) matters most, choose Qwen 3.5 27B. While Gemma 4 supports 256K on paper, Qwen 3.5 is substantially more VRAM-efficient at long context lengths in practice.
The bottom line: Gemma 4 31B and Qwen 3.5 27B are very close in overall capability, and the choice between them comes down to your specific priorities. Gemma 4 wins on math, vision, and edge deployment. Qwen 3.5 wins on coding, inference speed, and practical long-context handling. Both leave Llama 4 behind on license freedom and hardware accessibility. The days of Meta’s Llama being the automatic default choice for open models are over.