AI Code Review in 2026: Why Human Review Skills Matter More Than Ever

AI writes about 41% of all committed code in 2026, and some teams report well above 50%. AI review tools have cut PR cycle times by as much as 59%. Yet when Sonar asked 1,149 developers for their 2026 State of Code report , 47% ranked “reviewing and validating AI-generated code for quality and security” the top skill in the AI era, above prompting at 42%. The paradox: the more code AI writes, the more vital human review becomes.
Why? AI-written PRs ship 1.7x more issues than human ones (10.83 vs 6.45 per PR). They also carry 1.4x more critical issues and 1.75x more logic and correctness bugs. AI code hides subtle false guesses that compile and pass basic tests. It causes drift that only seasoned reviewers can spot. It leaves blind spots in auth and crypto code that look fine but miss key edge cases. The volume of AI code has turned review from a chore into the work that decides if your product stays reliable. The same pressure hits testing: AI-generated test suites can hit 90% line coverage while hiding the same logic flaws that make AI code risky.
A $400-600M Market That Barely Existed Two Years Ago
AI code review went from a side project in GitHub Actions to a real market in under two years. The narrow space, tools like CodeRabbit , Greptile , Sourcery , Qodo (formerly CodiumAI), and PR-Agent , now runs at roughly $400 to 600M in ARR in early 2026. The broader market with code quality and security tools sits at $2 to 3B. Year-over-year growth runs 30% to 40% for the narrow group.
AI code review startups raised over $1.2B in combined funding from January 2024 to December 2025. More than 1.3 million repos now use some form of AI review. GitHub ’s 2025 Octoverse report found that repos with AI review had 32% faster merge times and 28% fewer post-merge defects vs human-only review.
The growth runs on a simple math: senior engineer time is the priciest bottleneck in shipping software. AI review handles the cheap work (style, formatting, basic bug patterns). That frees humans to focus on design and business logic.
The Tool Landscape: Who’s Winning and Why
The AI code review space has settled around a few major players, each with its own angle.
CodeRabbit leads on market share with over 2 million linked repos and 13 million-plus PRs reviewed. It offers auto review comments, PR summaries, and multi-pass analysis. Pricing starts free for open source (rate-limited). Pro is $24/user/month on annual or $30 on monthly. Enterprise starts near $15,000/month for 500+ users.

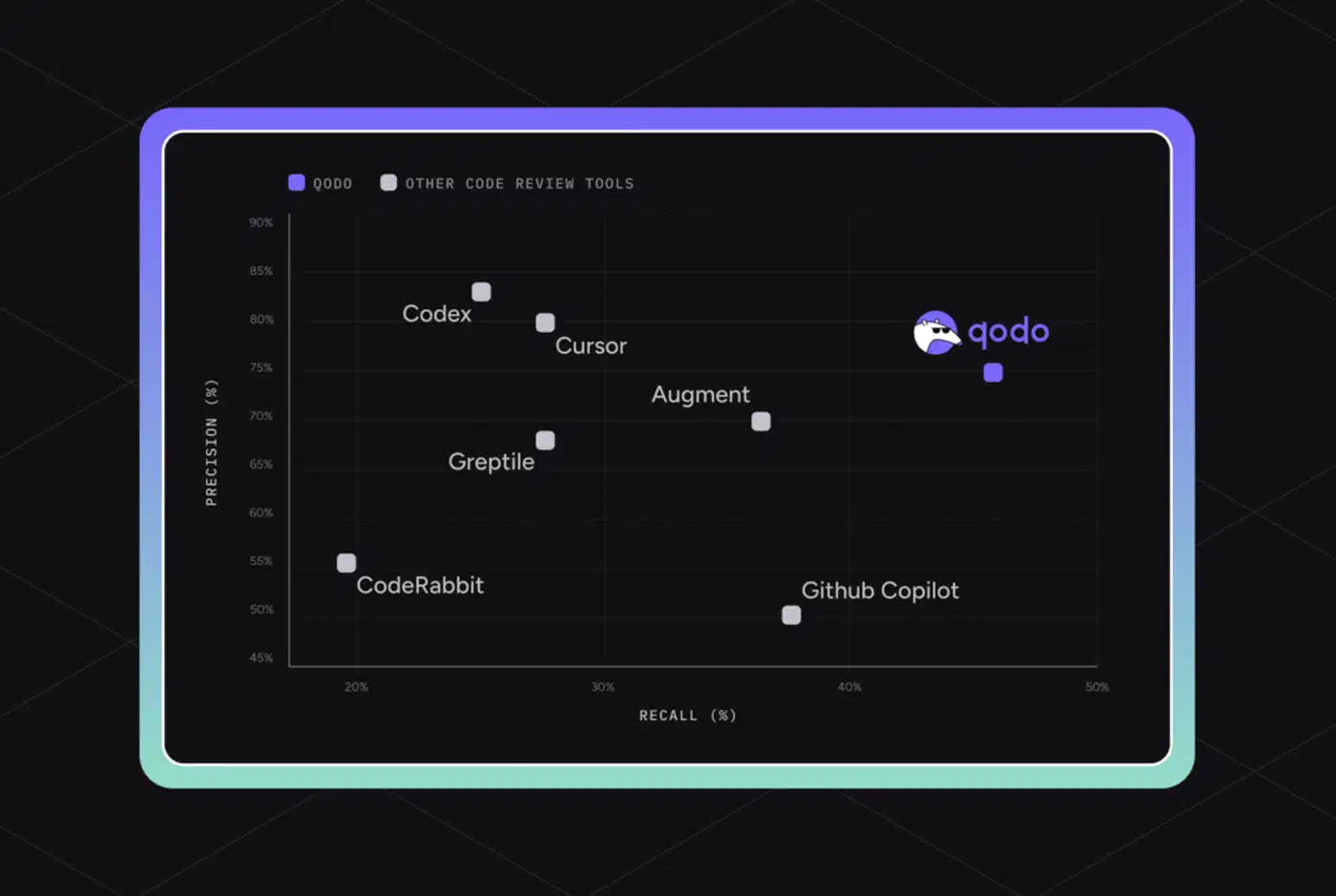
Greptile sets itself apart by indexing the whole codebase before it reviews PRs. That catches cross-file issues and enforces project rules. In Greptile’s own test of 50 real bugs across 5 open-source repos, it caught 82% vs Cursor at 58%, Copilot in the mid-50s, and CodeRabbit at 44%. But when Augment Code ran the same repos, Greptile scored 45%, not 82%. So vendor-run benchmarks deserve skepticism. Greptile’s Cloud Plan starts at $30/month plus $1 per review after 50 reviews per seat.
Qodo shipped Qodo 2.0 in February 2026 with a multi-agent review setup and a wider context engine. It pairs review with test generation, so it suggests tests for changed code next to review notes. Pricing sits at $30/user/month. The free Developer plan covers 30 PR reviews per month per org.
Sourcery offers the deepest language-specific analysis at $10/user/month, and it’s aimed at Python-heavy teams.
Anthropic Code Review, launched March 9, 2026 for Claude Teams and Enterprise users, runs a multi-agent setup. It sends per-PR agents that each chase a different bug class: logic errors, edge cases, API misuse, auth flaws, and style rules. For large reviews of 1,000+ lines, agents found issues 84% of the time, averaging 7.5 per PR, with under 1% of comments flagged as wrong. Typical cost: $15 to 25 per review, with about 20 minutes per run.
Graphite, in contrast, scored just 6% in third-party bug catch tests. That shows how wide the quality gap runs across this category.
| Tool | Pricing | Bug Catch Rate | Best For |
|---|---|---|---|
| CodeRabbit | Free / $24-30/user/mo | 44% (Greptile benchmark) | Mid-market teams, high PR volume |
| Greptile | $30/mo + $1/review overage | 82% (own benchmark) / 45% (independent) | Large monorepos, codebase-aware review |
| Qodo | Free (30 reviews) / $30/user/mo | N/A | Teams wanting review + test generation |
| Sourcery | $10/user/mo | N/A | Python-focused teams |
| Anthropic | $15-25/review | <1% rejection rate | Enterprise, large PRs |
| Graphite | Varies | 6% (independent) | Stacking workflows (not review) |
The Paradox: More AI Code Means Human Review Is the Top Skill
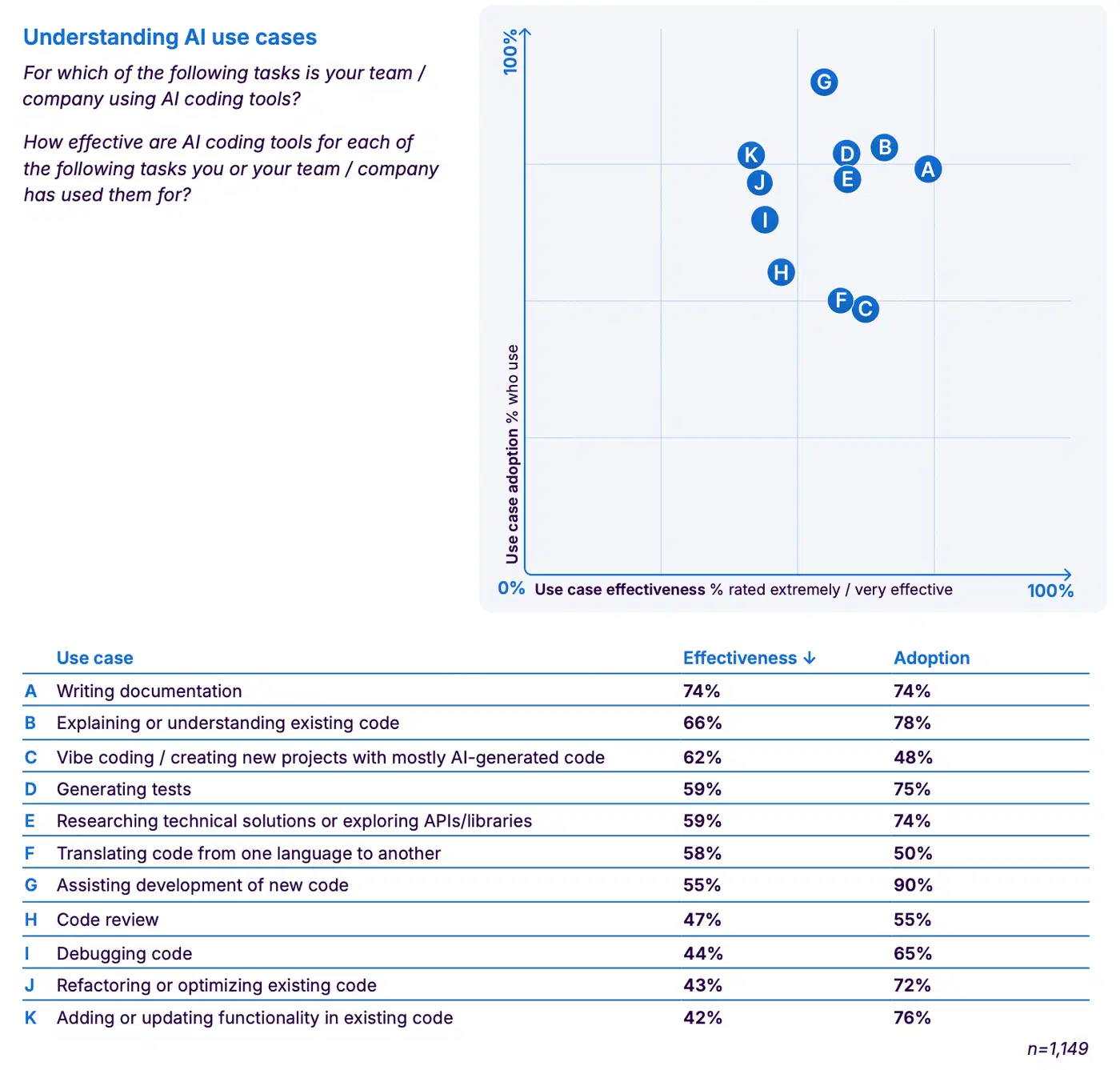
The Sonar survey isn’t a fluke. 38% of those polled said review of AI code takes more effort than review of human code. Only 27% said the opposite, a net 11-point jump in pain. 72% of devs who’ve tried AI tools use them daily. Yet 96% don’t fully trust the output, and only 48% always check it before they commit. This gap between use and check is what Sonar calls the “verification bottleneck.”
AI code is harder to review for three reasons:
- Subtle hallucinations: code that compiles and passes basic unit tests but breaks on edge cases, in concurrent runs, or in integration. These aren’t syntax slips a linter catches. They’re logic bugs, and you need system context to spot them.
- Drift in design: AI models tune for the local view. A single PR might look fine, but across dozens of AI PRs over weeks, the codebase piles up clashes, duplicate logic, and style breaks that no single diff shows.
- Security blind spots : AI writes auth, crypto, and data-handling code that looks fine but misses key edge cases. Static analysis catches some of these. Many need the kind of threat modeling only a human with system context can do.
What used to be routine “code review” is now AI-aware code validation at scale. It needs deep system context, security smarts, and an eye for drift patterns across many AI PRs that each look fine on their own. Devs who can review AI output well now earn a talent premium. The reason is simple: AI made the writing itself cheap. The same caution runs through the Claude Opus 4.7 launch reception : a confident tone is not a reliability signal.
The Optimal Workflow: AI First, Human Second, AI Never Last
Teams that get the best results in 2026 follow a clear three-phase pattern:

Phase 1, AI triage (seconds). The AI review tool scans the PR seconds after it opens. It flags format issues, basic bug patterns, dep problems, and style breaks. The dev fixes these before asking for human review.
Phase 2, human review (focused). The reviewer sees a clean PR with the cheap issues gone. They focus on design, business logic, security, and system-wide impact. That’s where the 32% merge time win comes from. Humans don’t waste time on semicolons and naming.
Phase 3, human approval (required). The human is always the final gate. AI can flag, suggest, and comment. But merge rights stay with a person who grasps the system-level fallout.
The anti-pattern to dodge: “auto-merge if AI approves.” That’s the fastest way to rack up design debt. AI review tools are strong on local fixes and weak on global fit. A mid-size SaaS case study showed AI review cut average PR cycle time from 27 hours to 11 hours, a 59% gain. But only when humans kept final say.
The gains are real, but you need to measure at the code level, not just PR throughput. Teams that hit an 18% lift with 58% AI commits found one truth: track what actually changed in the code, not just merged PRs. That’s the line between real wins and metric theater.
What Comes Next: Agentic Reviewers and the Enterprise Trust Problem
AI code review is heading toward system-aware agent reviewers. They will grasp API contracts, dep graphs, and prod impact across microservices. Not just the diff in isolation. Terminal coding agents already ship this: Codex CLI’s automated PR reviewer posts inline review comments on every pull request through a separate agent instance.
Anthropic’s multi-agent setup is the template. Agents for security, speed, style rules, and logic correctness run in parallel on the same PR. Future tools will fan out domain-specific agents with training tuned to each bug class. A security agent that knows OWASP patterns. A speed agent that knows database query costs. An accessibility agent that checks frontend changes.
Codebase-aware review, Greptile’s core trick of indexing the full repo before it reads diffs, will become the norm. Diff-only review misses too many cross-file issues. Teams that run large monorepos can’t afford reviewers (human or AI) that lack the wider view.
But enterprise rollout still hits real blockers. Who’s on the hook when an AI-approved PR causes an outage? Current tools waive liability. Most compliance frameworks (SOC 2, ISO 27001) require a named human approver. AI review doesn’t meet that bar today. Token cost is the other open problem. Anthropic’s $15 to 25 per review works fine for large PRs. It gets pricey at scale for fast teams shipping dozens of PRs a day. Token costs need to drop 5 to 10x before broad enterprise rollout makes sense.
AI code writing and AI code review now form a loop. AI writes code, AI reviews code, and the human role shrinks to judgment calls. Those calls need business context, user empathy, and clear ownership. They’re the skills that can’t be automated. They’re also the skills the market now prizes most.