AI Coding Benchmarks in 2026: Why the Leaderboard You Pick Decides the Winner

The SWE-bench Verified leaderboard in June 2026 is led by OpenAI’s GPT-5.5 at 88.7%, with Claude Opus 4.7 a step behind at 87.6% and GPT-5.3-Codex at 85.0%. Anthropic’s June flagships, Opus 4.8 and the new Fable 5, ship as the current top Claude models but have not landed on the public board yet. Pick a different benchmark and the order flips. On SWE-bench Pro, Claude Opus 4.7 leads at 64.3%. On Terminal-Bench 2.0 , Codex CLI paired with GPT-5.5 tops the chart at 82.0%, while the cheaper, faster Flash tier from Google hit 76.2% on the newer 2.1 set with output about 4x faster. LiveCodeBench favors Google. There is no single best AI coding model. There is only a best model for the kind of task you care about, and the agent scaffold around that model can shift scores by several points.
The SWE-bench Verified Leaderboard - GPT-5.5 Edges Ahead
SWE-bench Verified remains the most-cited AI coding benchmark. It tests models against 500 real GitHub pull requests. Each one needs a bug fix or a new feature inside a production Python codebase. The task is specific: given an issue and a repo snapshot, write a patch that passes the existing test suite. So it measures how well a model reasons about code that already exists, not greenfield work or puzzle-solving.
The June 2026 top 10 looks like this:
| Rank | Model | Provider | Score |
|---|---|---|---|
| 1 | GPT-5.5 | OpenAI | 88.7% |
| 2 | Claude Opus 4.7 | Anthropic | 87.6% |
| 3 | GPT-5.3-Codex | OpenAI | 85.0% |
| 4 | Claude Opus 4.5 | Anthropic | 80.9% |
| 5 | Claude Opus 4.6 | Anthropic | 80.8% |
| 6 | DeepSeek V4 Pro Max | DeepSeek | 80.6% |
| 7 | Gemini 3.1 Pro | 80.6% | |
| 8 | Kimi K2.6 | Moonshot AI | 80.2% |
| 9 | MiniMax M2.5 | MiniMax | 80.2% |
| 10 | GPT-5.2 | OpenAI | 80.0% |
The top score climbed from roughly 65% in early 2025 to 88.7% by mid-2026. For the first time in months the leader is not from Anthropic: OpenAI’s GPT-5.5, released April 23, sits 1.1 points ahead of Claude Opus 4.7, with OpenAI’s own GPT-5.3-Codex third. Anthropic’s June releases, Opus 4.8 and Fable 5, are the current flagship Claude models, but neither has been scored on the public board yet, so Opus 4.7 still stands in as Anthropic’s top entry here. Either way the lead is benchmark-specific. It changes the moment you switch to SWE-bench Pro, Terminal-Bench, or LiveCodeBench, which is the whole point of this post.
Claude Sonnet 4.6 at 79.6% is the value story on this board. It trails its Opus 4.6 sibling by only 1.2 points while costing about a fifth as much, and it sits within a point of much larger models like MiniMax M2.5. The newer Opus 4.7 opens an 8-point gap, but for teams weighing the Opus API premium, Sonnet stays the obvious default for high-volume coding.
SWE-bench Pro is the harder variant, and it tells the opposite story. Here Anthropic still leads: Claude Opus 4.7 tops the board at 64.3% (Anthropic-reported), while OpenAI’s GPT-5 line clusters in the high 50s (GPT-5.4 at 59.1% on Scale’s SEAL harness, GPT-5.5 around 58.6% on its own system card) and Gemini 3.1 Pro sits at 46.1%. No public model has cleared 65%. The Opus 4.7 reception threads on X and Reddit treated that Pro lead as the main reason power users tolerated the upgrade’s 1.5-3x token-burn cost. When Opus 4.8 and then Fable 5 followed, Reddit users who ran both Fable 5 and Opus 4.8 saw the same pattern: real gains, spread unevenly across tasks.
The Contamination Problem
SWE-bench Verified uses a fixed set of 500 GitHub issues, most created before late 2023. Since these problems predate most model training cutoffs, labs can - and likely do - train specifically on these tasks. SWE-Rebench was created to address this directly. It continuously mines fresh GitHub tasks and tracks each problem’s creation date against model release dates, producing over 21,000 tasks for evaluation.
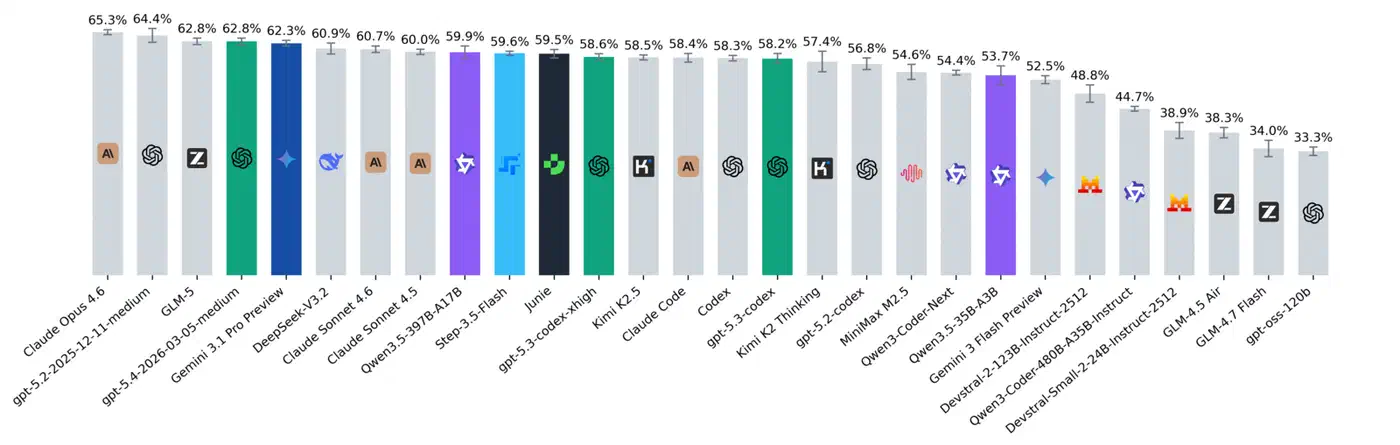
The gap between benchmarks shows up immediately. MiniMax M2.5 scores 80.2% on SWE-bench Verified but drops to 39.6% on SWE-Rebench. Claude Opus 4.6 goes from 80.8% to 51.7%. A 12-point gap between two models that looked nearly identical on the original benchmark. SWE-Rebench scores are lower across the board because the tasks are automatically collected rather than manually curated for solvability, but the relative ordering changes meaningfully.
HumanEval Is Saturated - LiveCodeBench Takes Over
HumanEval was the original AI coding benchmark. OpenAI’s Codex scored 13% on it in 2021. By June 2026, Kimi K2.5 (Reasoning) hits 99% on the BenchLM HumanEval tracker . Frontier models cluster between 91-95% with only a 7-point gap separating the top 10. A score below 80% means “not competitive”; above 90% means nothing differentiating. HumanEval is functionally dead as a discriminator.
The problems have been public since 2021, and data contamination is a real concern. Every model launch blog post still cites HumanEval scores because the numbers look impressive, but the benchmark no longer separates frontier models from each other.
EvalPlus extends HumanEval with roughly 80x more test cases per problem - averaging 764 tests per problem, totaling around 125,000 tests for the full suite. Top models drop 20+ points on EvalPlus compared to vanilla HumanEval. A model scoring 95% on HumanEval might score 75% on EvalPlus, revealing that high HumanEval scores often reflect pattern matching on familiar test structures rather than robust code generation. HumanEval Pro tests self-invoking code generation where functions must call other generated functions, and frontier models lose another 20+ points there, exposing weaknesses in compositional reasoning.
LiveCodeBench is the replacement that matters. It continuously sources fresh competitive programming problems from contests that occur after model training cutoffs, making contamination structurally impossible. The current top scores tell a different story from SWE-bench:
| Model | LiveCodeBench Score |
|---|---|
| Gemini 3.5 Pro | 91.7% |
| Gemini 3.5 Flash | 90.8% |
| DeepSeek V3.2 Speciale | 89.6% |
| Kimi K2.6 | 85.0% |
| GPT-5.5 | 84.0% |
| Claude Opus 4.7 | ~78% |
Google’s models dominate LiveCodeBench while sitting outside the top five on SWE-bench Verified. Claude, which leads SWE-bench Pro, falls to the back of the frontier pack on competitive programming. This is the clearest illustration that “best at coding” depends entirely on what kind of coding you mean.
Terminal-Bench 2.0 and the Agent Framework Variable
Terminal-Bench 2.0 measures a different kind of coding ability than SWE-bench or LiveCodeBench. Its 89 high-quality tasks span software engineering, machine learning, security, data science, and system administration. The test is whether a model can inspect files, run shell commands, debug failures, and complete multi-step tasks autonomously inside a terminal. This is agentic execution, not isolated code generation.
![]()
The June 2026 leaderboard reshuffles rankings yet again. Codex CLI wrapped around GPT-5.5 is the new outright #1 at 82.0%, with ForgeCode plus GPT-5.4 at 81.8% and TongAgents plus Gemini 3.1 Pro at 80.2%. Claude shows up further down the public board: ForgeCode plus Opus 4.6 was revised to 79.8% on the latest run, and Anthropic self-reports Opus 4.7 at 69.4%, still pending a tbench.ai submission. On the newer 2.1 set, Gemini 3.5 Flash posts 76.2% while generating output about 4x faster. The ordering bears little resemblance to SWE-bench Verified.
The agent framework story is where Terminal-Bench gets interesting from an engineering perspective. The same underlying model can score very differently depending on the scaffolding around it - how it is prompted, how tools are provided, retry logic, and context management. Claude Opus 4.6 scores 74.7% inside KRAFTON AI’s Terminus-KIRA agent but climbs to 79.8% in the ForgeCode harness. That 5-point swing from scaffolding alone, on a single fixed model, is larger than the gap between several adjacent models on SWE-bench Verified.
This makes model-to-model comparisons on agentic benchmarks inherently noisy. When someone says “GPT-5.5 beats Claude on Terminal-Bench,” the accurate statement is “Codex CLI wrapped around GPT-5.5 beats a specific Claude scaffold on Terminal-Bench.” Swap the scaffolds and the ranking might reverse.
BenchLM’s Weighted Scores - A Different Ranking Entirely
What happens when you stop cherry-picking a single leaderboard and weight multiple benchmarks together? BenchLM.ai attempts this, and as of its June 18 update the answer flips the SWE-bench Verified board on its head.
BenchLM weighted coding scores, June 2026:
| Model | Weighted Coding Score |
|---|---|
| Claude Mythos 5 | 100.0% |
| Claude Fable 5 | 100.0% |
| Claude Opus 4.8 | 97.6% |
| Claude Opus 4.7 (Adaptive) | 93.5% |
| Gemini 3.1 Pro | 93.3% |
| GPT-5.4 | 87.2% |
Anthropic sweeps the top four. Its new June models, Mythos 5 and Fable 5, top out the scale, with Opus 4.8 right behind at 97.6% and Opus 4.7 at 93.5%. The reversal is the point: GPT-5.5, which leads the raw SWE-bench Verified board, does not crack BenchLM’s verified top 10, and GPT-5.4 sits tenth at 87.2%. BenchLM’s coding score equally weights SWE-bench Pro and LiveCodeBench, with SWE-Rebench also factored in, so it rewards models that are strong on every axis rather than the one that tops a single saturated board. Anthropic’s June lineup is broad enough to run the table; OpenAI’s strength is concentrated where BenchLM weights least.
Coding carries 20% weight in BenchLM’s overall model ranking, the second-most influential category after agentic execution. BenchLM currently tracks 101 provisionally-ranked models and 21 verified-ranked ones, and it flags that a 5-point gap is meaningful: it typically separates a model that can solve a complex multi-file bug from one that gets stuck. When weighted benchmarks lack data for a model, the system falls back to remaining trustworthy scores rather than filling gaps with synthetic values.
The methodology page explains that display benchmarks like SWE-bench Verified, FLTEval, and React Native Evals are tracked but not weighted - they are shown for reference but do not influence the composite score. That single design choice explains the divergence: GPT-5.5 can own SWE-bench Verified and still sit off BenchLM’s weighted podium, because the board it tops is the one BenchLM treats as display-only.
Open-Weight Models Are Closing the Gap
Open-weight models have caught up to the proprietary frontier in 2026, and the numbers speak for themselves.
MiniMax M2.5 is a 230-billion parameter Mixture-of-Experts model with only 10 billion active parameters, released on February 12, 2026 under a license allowing both commercial and non-commercial use. It scores 80.2% on SWE-bench Verified, still inside the top 10 and tied with Moonshot’s new Kimi K2.6, though the spring frontier releases opened roughly an 8-point gap above it. A year ago, open-weight models trailed the frontier by 10+ points.
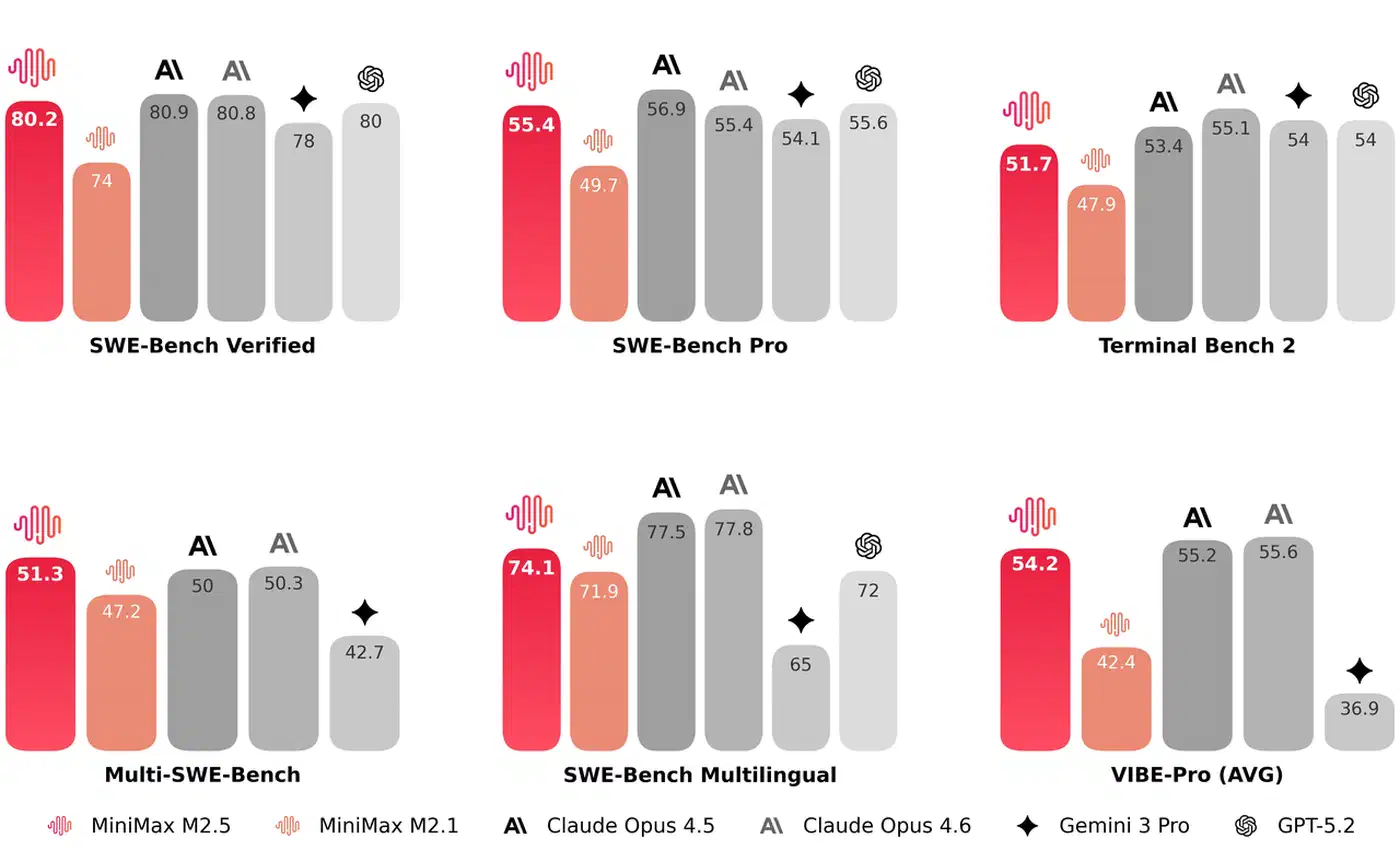
The cost difference is stark. MiniMax estimates roughly $1 for one hour of continuous inference at 100 tokens per second. M2.5 completes the SWE-bench Verified evaluation 37% faster than its predecessor M2.1 (which scored 74%), matching Claude Opus 4.6’s inference speed. The generational improvement from 74% to 80.2% happened in a single model update. MiniMax M2.7 shipped in April 2026 with 78.0% on SWE-bench Verified: same 230B MoE layout, with a self-evolving training harness.
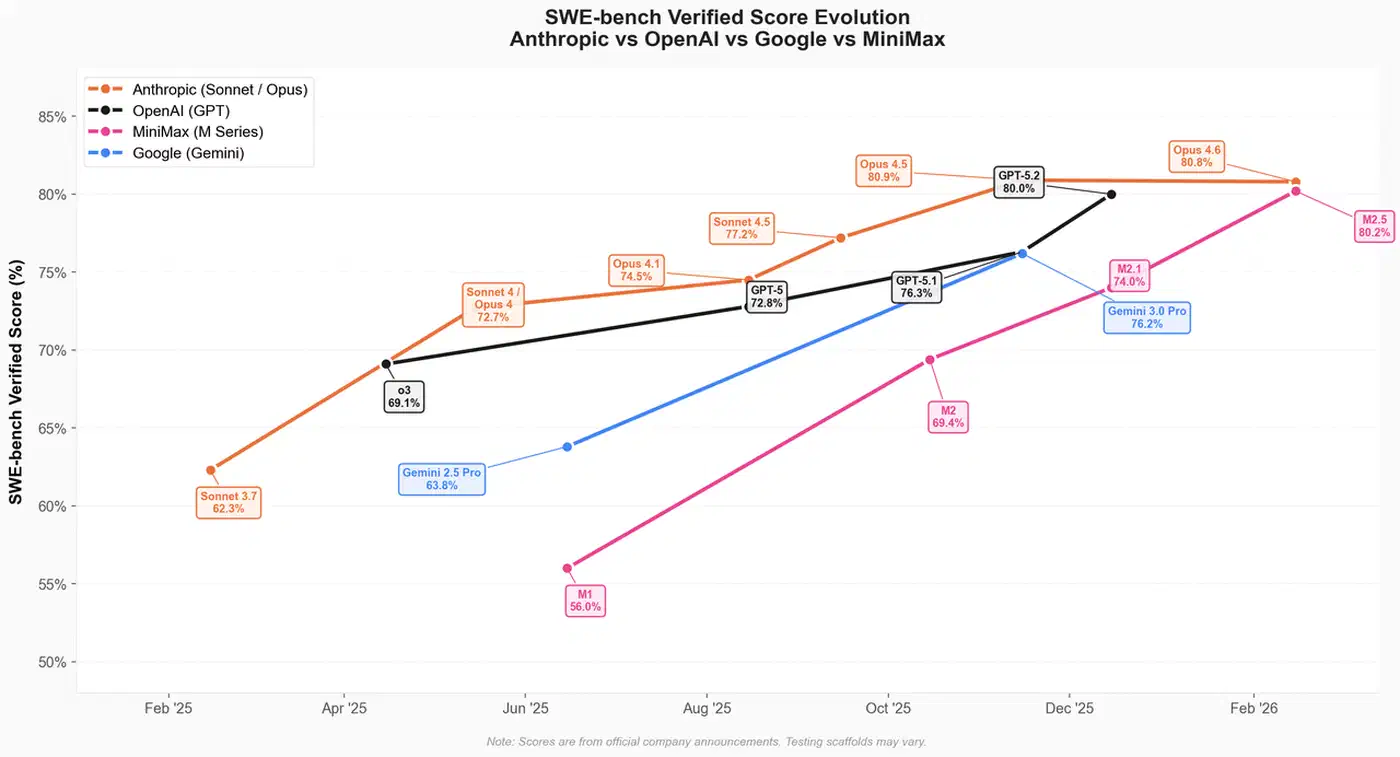
DeepSeek V4 Pro Max , a 1.6-trillion-parameter MoE, has since cleared that bar: it posts 80.6% on SWE-bench Verified, tying Gemini 3.1 Pro and leading every open-weight model on the board, at roughly $0.30 per million tokens. It is one piece of the broader Chinese open-weight coding stack , where Kimi, GLM, and Qwen all jockey for the lead depending on the benchmark.
But open-weight parity on SWE-bench Verified does not mean open-weight parity everywhere. On SWE-Rebench, MiniMax M2.5 drops to 39.6% while Claude Opus 4.6 holds at 51.7%. On Multi-SWE-Bench (multi-language evaluation), MiniMax leads at 51.3% versus Claude’s 50.3%. The picture is complicated, and which benchmark you check determines whether open-weight models look competitive or still trailing by double digits.
For enterprise teams evaluating whether to switch from proprietary APIs to self-hosted open-weight models, the decision no longer comes down to raw capability alone. Alibaba’s Qwen3.6-35B-A3B as an enterprise self-host option pushes this further, posting 73.4 on SWE-bench Verified with only 3B active parameters. When models score within a point of each other , the differentiators become ecosystem factors: tooling maturity, compliance certifications, support SLAs, the inference engine you serve the weights on, and the quality of the agent framework your team can build or buy.
What This Means for Choosing a Coding Model
A few things stand out from surveying these benchmarks together.
No single benchmark tells the full story. SWE-bench Verified, Terminal-Bench, LiveCodeBench, and BenchLM weighted scores rarely agree on a winner: OpenAI tops raw Verified, Google owns LiveCodeBench, and Anthropic sweeps the weighted board and SWE-bench Pro. A model that excels at diagnosing bugs in existing Python repos may underperform on competitive programming or autonomous terminal operations.
Agent scaffolding matters as much as model choice. The same model can swing several points depending on the framework wrapping it. Before switching models based on benchmark scores, check whether your current model with a better scaffold would outperform a new model with your existing setup.
HumanEval is a checkbox now, not a differentiator. Any score above 90% means the model can write basic functions. The benchmark that actually matters for your team is the one most similar to your actual workload.
Contamination is undermining fixed benchmarks. SWE-Rebench’s fresh-task methodology reveals performance gaps invisible on SWE-bench Verified. Models scoring within a point on Verified can differ by 12+ points on uncontaminated tasks.
Open-weight models are viable competitors, even if the very top of the board pulled a few points clear this spring. MiniMax M2.5 at 80.2% and DeepSeek V4 Pro Max at 80.6%, both self-hostable at a fraction of frontier inference cost, change the economics for teams running high-volume coding tasks. For most workloads the decision now comes down to infrastructure preferences and ecosystem needs rather than raw model quality.
The race to the top of any single leaderboard will continue. The more useful question for practitioners remains: which benchmark most closely reflects the coding tasks my team actually does, and which model performs best there?