Running Multiple AI Coding Agents in Parallel: Patterns That Actually Work

Three focused AI coding agents beat one broad agent working three times as long. Addy Osmani showed this at O’Reilly AI CodeCon , and the finding captures both the upside and the catch of multi-agent work. The speed gains are real. They only show up when you solve the coordination problem. Without file isolation, iteration caps, and review gates, parallel agents make a mess of merge conflicts and duplicated work.
In practice, the tooling breaks into three tiers. In-process subagents handle focused delegation in a single terminal. Local orchestrators run 3-10 agents with dashboard control. Cloud-async tools handle unattended overnight runs. Most developers use all three tiers daily, switching based on task size and whether they plan to stay at the keyboard.
The Three-Tier Framework
Before picking a pattern, you need to know which tier you are working in. Each tier has its own coordination overhead, tooling needs, and failure modes.
Tier 1, In-Process (Interactive). Claude Code
subagents and Agent Teams run inside one terminal session with no extra tooling. You stay in the loop and get fast feedback. Subagents use the Task tool to spawn focused child agents from a parent orchestrator. Agent Teams
turn on with CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1. They add a shared task list with dependency tracking, peer-to-peer messaging, and file locking. 3-5 teammates works best. Token costs scale with team size. Three teammates cost about three times what one agent costs, but they finish the work far faster.
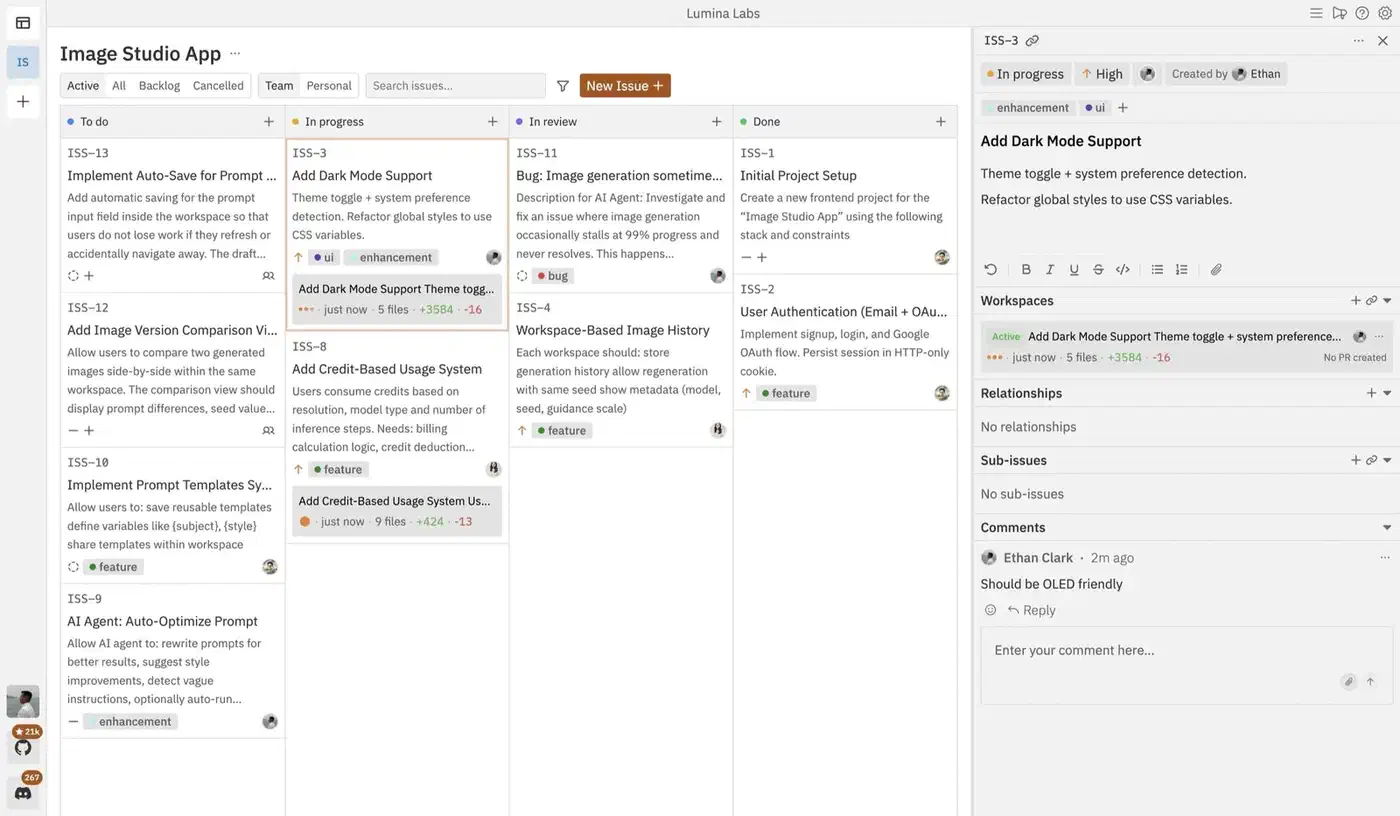
Tier 2, Local Orchestrators. Many agents spawn in isolated git worktrees with visual dashboards, diff review, and merge control. This works best with 3-10 agents on known codebases, where you want oversight without staying glued to each terminal. The major tools here:
| Tool | Platform | Key Feature | Agent Support |
|---|---|---|---|
| Conductor (Melty Labs) | macOS | Visual dashboard with diff review, checkpoints, spotlight testing | Claude Code, Codex |
| Vibe Kanban | Mac, Windows, Linux | Kanban board with in-board diff review, drag-to-start workflow | Claude Code, Codex, Gemini CLI, Amp, Cursor |
| Claude Squad | Mac, Linux | tmux-based session management, background completion | Claude Code, Codex, Aider |
| OpenClaw + Antfarm | Any OS | Messaging-app interface (Telegram, Slack, Discord), Ralph Loop built-in | OpenClaw agents |
| Antigravity | Mac, Linux | Skills library with 1,340+ agentic skills | Claude Code, Cursor, Codex CLI, Gemini CLI |

Conductor offers checkpoints (automatic snapshots for rollback), spotlight testing (sync changes back to your main repo for testing), and multi-model mode (run Claude and Codex on the same prompt in different tabs to compare). Vibe Kanban takes a different approach. It fills the “doomscrolling gap” during those 2-5 minutes when an agent is working and you have nothing to do. In those Claude-versus-Codex comparisons, Reddit’s Sol reaction leans cheaper coder, weaker designer.
Tier 3, Cloud Async. Fire-and-forget task assignment, where agents run in cloud VMs. You assign a task, close your laptop, and come back to a pull request. Claude Code Web
runs in Anthropic-managed VMs and opens the PR for you. GitHub Copilot Coding Agent
lets you assign any issue to @copilot and get a draft PR from a GitHub Actions runner. Jules
by Google writes a plan you approve before coding starts, then returns a PR with full reasoning logs. These harnesses increasingly default to fast tiers like Google’s Terminal-Bench champion
. Codex Web
by OpenAI runs each task in a sandboxed container and shows its work: terminal logs and test outputs for every step. Community tools cover overnight autonomy too. A few open-source projects built on Claude Code
run loops on their own while you sleep.
Pattern Deep-Dive: Subagents, Agent Teams, and the Ralph Loop
The three core patterns each solve a different coordination problem. The right pick depends on whether you need focused delegation, true parallel work, or overnight shipping with no one watching.
Subagents (Focused Delegation)
This is the simplest multi-agent pattern. A parent orchestrator splits work into specialized child agents, each with its own files. In Osmani’s Link Shelf demo, the parent spawned three subagents: Data Layer, Business Logic, and API Routes. Together they used roughly 220k tokens. The first two ran in parallel as independent tasks. The third waited for their output before starting.
Subagents solve context isolation, specialization, and parallel execution for independent tasks. They do not solve peer messaging or shared task lists. They also will not stop two agents from touching the same file if you scope the work loosely.
Agent Teams (True Parallel in tmux)
Agent Teams add the coordination primitives that subagents lack. The architecture has three layers. A Team Lead at the top splits the work and creates the task list. A Shared Task List in the middle holds statuses (pending, in_progress, completed, blocked) and tracks dependencies. Teammates sit at the bottom, each running as an independent Claude Code instance in its own tmux split pane.
To enable Agent Teams, you need Claude Code v2.1.32 or later:
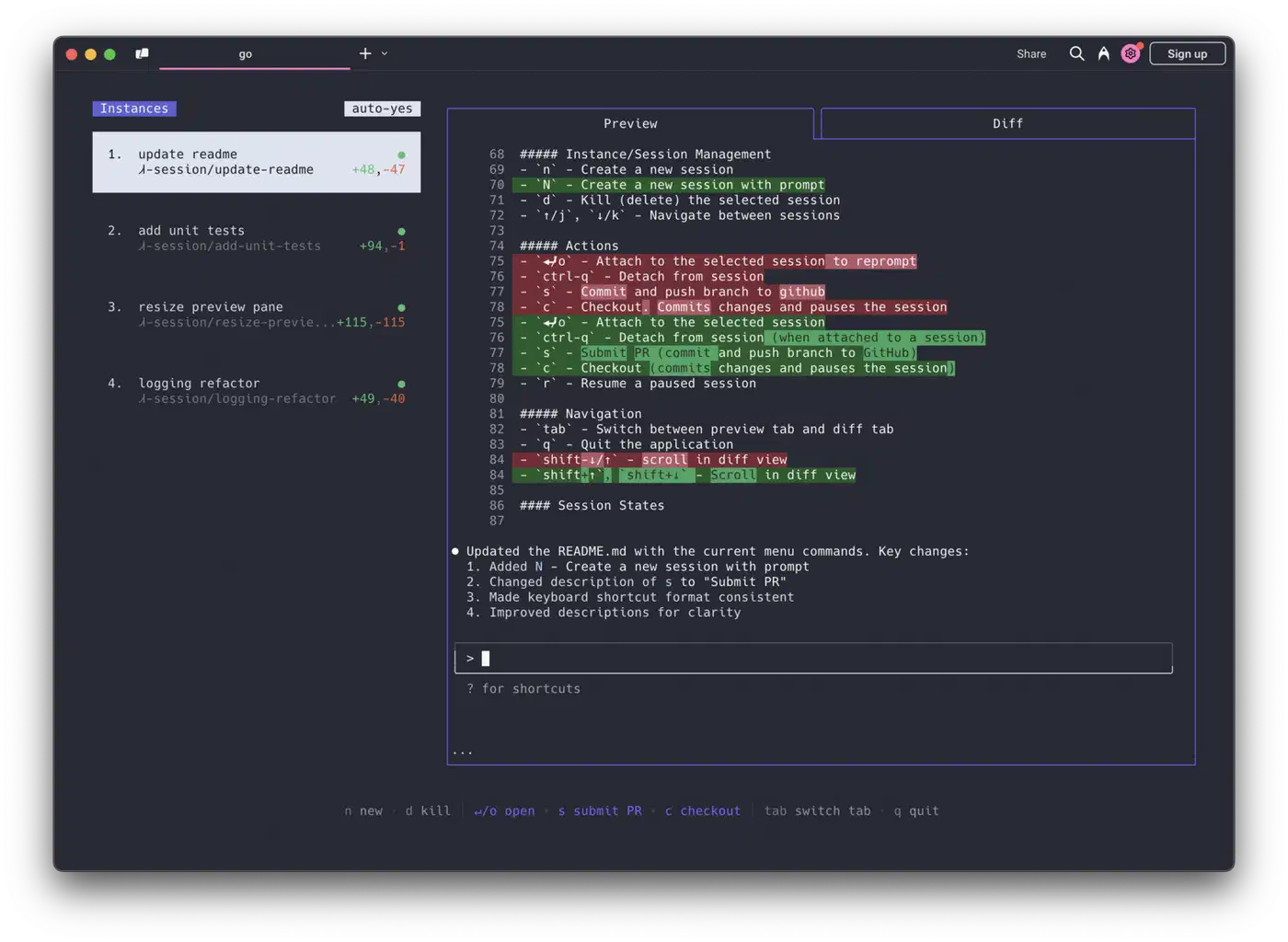
export CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1Teammates self-claim tasks from the shared list. They message each other directly, peer-to-peer, not through the lead. When a teammate finishes a task, any blocked tasks that depended on it unblock on their own. Press Ctrl+T to toggle a visual overlay of the task list. You can also cycle through teammates with Shift+Down in in-process mode, or use tmux/iTerm2 split panes to see everyone’s output at once.
3-5 teammates is the practical ceiling. Going past that drops review quality faster than it lifts throughput.
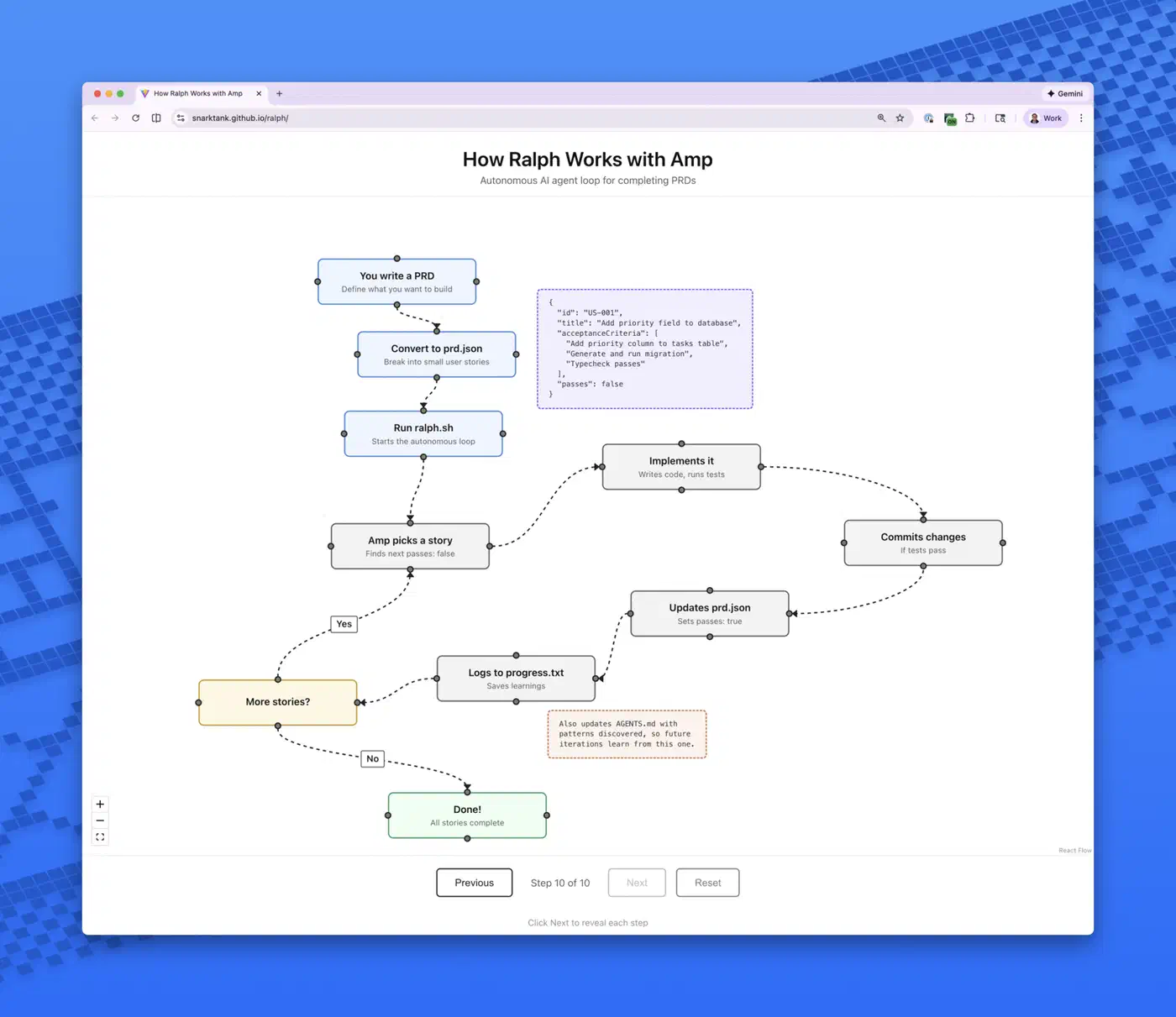
The Ralph Loop (Stateless Iteration)
Named after a pattern of naive persistence, the Ralph Loop runs a five-step cycle:
- Pick the next task from
tasks.json - Implement the change
- Validate with tests, type checks, and linting
- Commit if checks pass, update task status
- Reset - clear context and begin a fresh iteration
State lives on disk, not in the model’s context window. Four persistent memory channels bridge iterations: git commit history, a progress log file, the task state file, and an AGENTS.md file that serves as long-term memory. Context accumulation is the problem where failed attempts pile up in conversation history and confuse the model. The Ralph Loop solves it by design, since each iteration starts fresh.
A typical tasks.json entry looks like this:
{
"id": "task-003",
"title": "Add search endpoint",
"status": "pending",
"dependencies": ["task-001", "task-002"],
"files": ["src/routes/search.ts", "src/services/search.ts"],
"validation": "npm test -- --grep search"
}
Kill criteria are important. If an agent gets stuck on the same error for 3 or more iterations, reassign the task. The Ralph Loop works best for bugfixes with reproducible test cases, framework migrations with clear target states, and test coverage work where progress is easy to measure. It struggles with tasks that need architectural coherence, since the code reflects the agent’s path to a solution rather than a deliberate design.
Hierarchical Subagents
For large projects, you can go deeper. Spawn feature leads that each spawn their own 2-3 specialists. The parent orchestrator talks only to lead agents, which keeps its context clean. Feature Lead A gets a brief like “Build the search feature” and splits it into Data, Logic, and API subagents on its own. This mirrors a real engineering team with tech leads in the middle, and it keeps context from fragmenting across three levels.
Quality Gates That Keep the Orchestra in Tune
Without guardrails, parallel agents produce merge-conflict chaos. These five quality gates separate teams that ship from teams that spend all day resolving conflicts.
Plan Approval. Teammates write a plan before coding. The lead reviews it and approves or rejects before any code lands. This catches architectural problems early and stops agents from making clashing assumptions about shared interfaces.
Lifecycle Hooks. TeammateIdle hooks check that tests pass before an agent stops working. TaskCompleted hooks run lint and tests before a task is marked done. If a hook fails, the agent keeps working rather than ship unfinished work.
MAX_ITERATIONS=8 Hard Limit. This stops runaway token spend on stuck tasks. Combine it with a forced reflection step before each retry: “What failed? What specific change would fix it? Am I repeating the same approach?” That reflection prompt alone cuts stuck-agent loops by a lot. Pair it with per-agent token budgets (for example, Frontend 180k tokens, Backend 280k tokens) and an auto-pause trigger at 85% budget use.
1 Reviewer per 3-4 Builders. A dedicated @reviewer teammate with read-only access, running Claude Opus 4.6, checks every finished task. Only green-reviewed code reaches the lead. Too few reviewers creates a quality bottleneck. Too many wastes tokens without better output.
One-File-One-Owner Rule. Each file goes to exactly one agent. No two running tasks touch the same file. This rules out merge conflicts by design rather than fixing them after the fact. When merging, do it one branch at a time: pick one agent’s work first, then rebase the rest.
When Multi-Agent Setups Fail
The tooling is maturing fast, but multi-agent coding still has sharp edges. Knowing the failure modes is worth more than memorizing the happy path.
Context accumulation kills long-running agents. Standard agent loops keep every failed attempt in conversation history, which confuses the model into repeating mistakes. The Ralph Loop solves this by design. Subagent and team patterns still suffer when tasks are too large for a single context window.
LLM-generated AGENTS.md files make things worse. Research from ETH Zurich (Gloaguen et al.) found that LLM-generated rules files
cut success rates by roughly 3% while raising costs by 20%. Human-curated AGENTS.md files, by contrast, give a modest 4% lift. The lesson: let humans write the project conventions file. Keep it short, with clear sections for style, gotchas, architecture decisions, and test strategy.
WIP limits beat raw parallelism. 3-5 agents is the practical ceiling for real review capacity. Beyond that, the reviewer becomes the bottleneck and code quality drops without anyone noticing. This applies to both Agent Teams and Tier 2 orchestrators.
Use cheap models to plan, costly models to build. Route task splitting and plan writing to Sonnet-tier models. Save Opus-tier for the real code. Multi-model routing usually cuts costs by 30-50% without hurting output quality. Some teams report API bills of $500-2,000 a month for steady multi-agent use. Model routing is the single biggest lever for cutting that.
The “three focused agents” rule is conditional. Three agents beat one only when tasks are truly independent and file ownership is clean. Tightly coupled code with shared state files wipes out the parallelism benefit. If your codebase has high coupling between modules, fix the boundaries before you throw agents at it.
Practical Cost Reality
Multi-agent setups burn tokens linearly with agent count. Three agents cost roughly three times one agent. For Claude Code API use, individual developers report $500-2,000 a month depending on intensity. The Link Shelf demo used roughly 220k tokens across three subagents. A single autonomous agent on a long multi-step task can burn through $5-15 in API calls in minutes.
The main cost levers:
- Prompt caching cuts repeated-context costs by up to 90%
- Multi-model routing (cheap models for planning, expensive for implementation) saves 30-50%
- Token budgets per agent with auto-pause at 85% prevent runaway spend
- The Ralph Loop’s context reset avoids the snowballing token costs of long conversations
For teams on Claude Max plans ($100-200 a month), Agent Teams running in-process skip API billing entirely. That makes Tier 1 the cheapest place to start. Tier 2 and Tier 3 tools that use API keys add separate API costs on top of any subscription.
Where to Start
If you have never tried multi-agent coding, the path is clear:
- Start with subagents. Give Claude Code a task that splits into 2-3 independent pieces. Watch how the parent orchestrator handles the dependency graph and how each subagent stays inside its file scope.
- Graduate to Agent Teams when you need peer messaging and shared task lists. Set
CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1, start with 3 teammates, and use plan approval for every task. - Add a Tier 2 orchestrator when you want visual oversight across many features. Conductor if you are on macOS, Vibe Kanban if you need cross-platform.
- Use Tier 3 cloud agents to drain the backlog. Assign issues to
@copilotor fire off tasks in Claude Code Web before you leave for the day.
The pattern that works is the one where you solve coordination before you add parallelism. File ownership, iteration caps, review ratios, and plan approval are not bureaucratic overhead. They are the difference between three agents that ship and three agents that produce a mess.