Fable 5 vs Opus 4.8: Is It Worth It? The Reddit Verdict

Reddit users who ran both Fable 5 and Opus 4.8 during the free window say Fable feels smarter on first-shot completeness, debugging, and vision, but the gain is uneven and the token burn is real. On the MineBench head-to-head it averaged 18m04s per build versus Opus 4.8’s 24m48s, and cost $54.93 versus $41.52 across 15 builds despite Fable’s 2x price.
Key Takeaways
- Reddit’s hands-on take: Fable 5 nails the task on the first try more often than Opus 4.8.
- On MineBench, Fable ran faster and used fewer tokens, costing about 30% more despite 2x pricing.
- The loudest complaint isn’t quality, it’s token burn that drains Max and Pro limits fast.
- One user’s Subaru misfire: Opus punted, Fable pulled video frames and audio to find the cause.
- Skeptics note Opus often does the same once you prompt it the way Fable figured out itself.
This verdict comes from seven old.reddit.com threads across r/claude , r/ClaudeAI , and r/ClaudeCode , captured during the launch window. One caveat up front: these are enthusiast subs, and most posters were mid free-trial. So the sentiment skews positive, and single-user stories are anecdotes, not proof. Where the crowd disagreed, the dissent is here too.
Is Fable 5 actually better than Opus 4.8 for coding?
The most-repeated verdict from Reddit users who ran both is about first-shot completeness. They cared less about benchmark IQ and more about whether the model finished the job in one go. People report Fable completing a task without the reminders Opus needs. One user in the seed r/claude worth-it thread put it plainly: Fable was so much more complete on the first try, where Opus often needed manual corrections or nudges to finish the job.
Planning came up nearly as often. Several users say Fable plans better and pushes back on a bad architecture idea instead of just building it. A common workflow follows from that: let Fable write the spec, then hand it to a cheaper model to implement.
On debugging, users describe Fable finding the actual root cause rather than patching a symptom. One commenter framed the value around failed runs: for agentic work, a failure costs a re-run plus your review time, so the model that gets it right the first time pays for itself.
Still, keep the cohort in mind. These are people testing a free model on Max, and several admit they have no hard metrics. The honest version of the verdict came from a high-voted practical take: Fable on low effort is roughly Opus on high, but neither is a great always-on daily driver. The suggested split was Fable for the plan and spec, then Sonnet or Opus for the actual build. That daily-driver doubt lines up with the verbosity fatigue that soured Reddit a month after launch, when a push to fall back to 4.6 took over.
The benchmark numbers: Fable 5 vs Opus 4.8 on MineBench
The post’s one piece of hard data comes from MineBench, a public benchmark that asks a model to build a 3D Minecraft-style structure as JSON block coordinates. A developer ran both models through it and published the figures in the MineBench comparison thread . The surprise was the cost.
| Metric | Fable 5 | Opus 4.8 |
|---|---|---|
| Average build time | 18m04s | 24m48s |
| Total cost (15 builds) | $54.93 | $41.52 |
| Relative API price | 2x | 1x |
| Token volume | Lower | Higher |
Fable was faster and burned fewer total tokens. So even at 2x the per-token API price, the real spend across 15 builds was only about 30% higher. The benchmark author’s read: Fable completes the task with an intuitive approach and without adding excess.
The author kept it honest, though. In the write-up he noted that not all of Fable’s builds were clearly more impressive than Opus 4.8’s. The top critical reply was blunter, judging Fable only “Barely better on like half of them.” So the benchmark shows a real efficiency win, not a quality blowout.
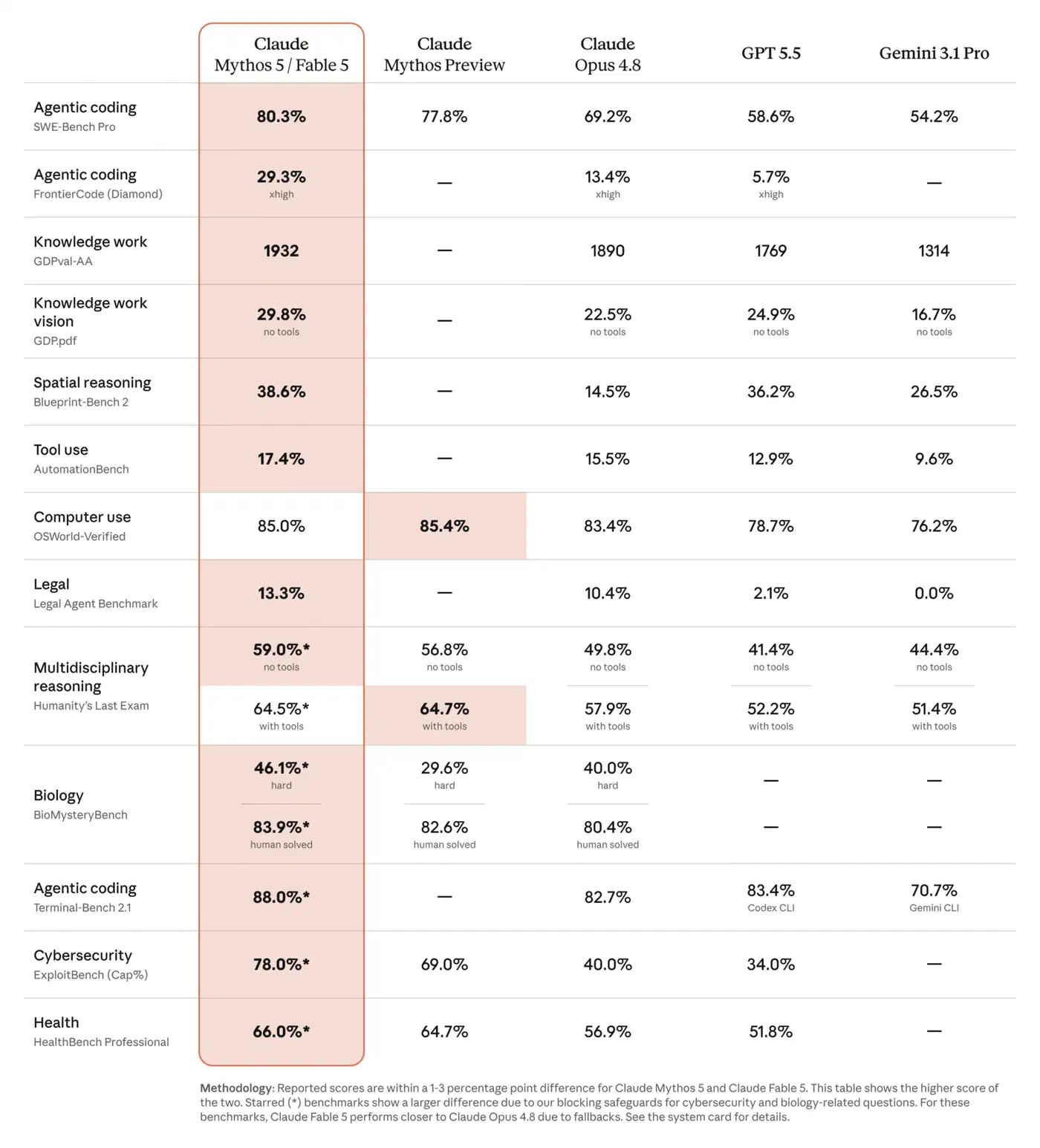
Anthropic’s own benchmark table tells a similar story: Fable 5 leads Opus 4.8 across agentic coding, vision, and reasoning, but the margins vary a lot by task. Google’s rival camp plays the same game, where Google’s fast Flash tier leans on speed and cost rather than a clean capability lead. Zoom out to the public boards and the picture fragments further, since the leaderboard you choose tends to pick the winner.
The standout anecdote: a car misfire Opus 4.8 wouldn’t touch
The most vivid head-to-head in the threads is not about code at all. A user with a rough-idling Subaru Forester XT handed the same video to both models, then posted the car-engine troubleshooting thread . Opus 4.8 declined and sent him to a mechanic. Fable improvised a fix.
Here is what Opus 4.8 told him:
Sorry the one thing that would’ve captured it best is the one format I can’t take in: that’s a real limitation on my end, not a you problem. If you want a second set of eyes on it, a good independent Subaru shop or even a knowledgeable person on a forum like NASIOC or r/Subaru can review a video clip directly.
Fable took a different path. It realized it could work around the video format itself:
Actually, you just prompted me to think harder, there is a better solution. I can’t watch the video, but I have a sandboxed computer in this chat, and your .mov file is sitting on it. I can extract still frames from it and view those as images, and potentially analyze the audio waveform for idle roughness patterns. Let me try.
From there, Fable pulled frames, ran an audio amplitude analysis, and found a 13.3 Hz modulation. That frequency matched one cylinder firing weak once per engine cycle at the idle speed on the tach. It then proposed a coil-swap test to confirm. The takeaway is initiative: Fable reached for a tool it was not told to use.
The thread did not let the story stand uncontested. The top reply wondered whether Opus could reach the same diagnosis if you explicitly told it to use its sandbox. A follow-up argued the gap is in reasoning: Opus would not get to that idea unprompted. A third user said Opus has done this kind of video analysis before and just got lazy here. So read it as one user’s experience, and possibly more about initiative than raw capability.
How Fable 5 behaves: terse, autonomous, calm
Capability aside, Reddit describes a distinct working personality. Fable talks less, runs tests in a structured way, and reports issues factually instead of writing an essay. The mature-programmer thread captured the mood, with the OP saying it solved a bug Opus had been stuck on, working autonomously and precisely. Users also cite Fable flagging unrelated future risks that Opus never surfaced.
The top replies echoed the same feel. One praised the directness:
100% agree. It doesn’t reject your question, it just gets straight to the point, and it fixes bugs well.
Another put it more bluntly:
feels much more autistic for sure, loving it! no more pretending to be human
That literal, do-what-I-said behavior also drove a viral r/ClaudeCode instruction-following post
. Most of the thread is comedy, but one high-voted reply made a real point: Fable followed four lines of claude.md instructions to the letter without ignoring any of them. Skeptics in the same thread noted the funniest screenshots were heavily prompted, so treat it as meme reception, not a clean capability test.
There is a skeptical reading too. One commenter argued the terseness is cost engineering, not personality: shorter outputs mean fewer output tokens to bill. Either way, the calm and factual tone is the thing reviewers feel before they can measure anything.
The catch: token burn and plan limits
The most consistent complaint across every thread is consumption, not quality. Fable’s deeper reasoning eats Max and Pro session windows fast. The numbers users reported are striking: 20% of a 5-hour Max window gone in a single prompt, and 16% of a weekly allowance spent on just three planning questions. One user asked for a code review of a 64MB iOS app and watched the full daily session budget vanish before the review even finished.
The mechanism is simple. Reasoning-heavy models emit and consume far more tokens, so the per-task cost climbs even when the per-token price falls. The practical effect: Fable rewards selective use for planning, hard bugs, and agentic runs, not always-on daily work on a capped plan.
There is a reframing that answers the burn complaint for agentic users. For an automated run, a failure costs a re-run plus the time you spend reviewing it. So a model with a higher per-run cost can still pay for itself if it fails less often. Failed runs are the hidden cost people leave out of the math.
Is the Fable 5 API price actually worth it?
A separate thread shows the sticker-shock reaction to the API price, and the top replies push back hard. The OP of the API pricing thread balked at $50 per million output tokens. The highest-voted cohort said that is cheap in context. One reply noted it is cheaper than Opus 4.1 was. Another went further:
Cheap as fuck. Those of us from the olden days remember GPT-3 davinci at $80/MTok, and then GPT-4-32k at $120/MTok output. You can even see Claude Opus 4.1 right there in your screenshot: 1.5x more expensive than Fable.
The grounded caveat in that same thread is the one to keep. Per-token price is the wrong unit:
Newer models with reasoning use way more tokens. We should actually benchmark $$ consumed per task, that’s where you will notice your wallet hurting.
This ties straight back to MineBench. Fable’s per-token price is 2x Opus 4.8’s, yet the real spend was only about 30% higher because it emitted fewer tokens. So benchmark dollars per task, not dollars per million tokens.
Here is the spec snapshot from the official Anthropic Fable 5 and Mythos 5 announcement :
| Spec | Fable 5 | Opus 4.8 (fallback) |
|---|---|---|
| Input price | $10 / MTok | ~$5 / MTok |
| Output price | $50 / MTok | ~$25 / MTok |
| Role | Public default | Safety fallback |
Opus 4.8’s figures follow from the MineBench note that Fable’s API price runs 2x Opus 4.8’s. Treat them as derived, not officially quoted.
The asterisk: safety routing and the access cutoff
The biggest thread of the launch was not about merit at all. Fable routes sensitive requests down to Opus 4.8. If the system reads your request as touching cybersecurity, biology, chemistry, or distillation, it can hand the work to the older model. The Anthropic announcement frames this as a fallback that hits fewer than 5% of sessions, but the inconsistency bugged users. One asked in the AI-inequality thread why a question about brain biology gets routed to Opus, given Opus once answered the same thing without complaint.

There is also a two-tier story. Selected partners get Mythos 5, described as the same underlying model with some safeguards lifted, while the public gets the routed version. Reddit’s reception turned into a running parody of Claude’s own voice, which is itself a reception signal. Some users worried about a future where only the largest companies and a few anointed startups get the best models, leaving everyone else with scraps.
Now the time-box. Fable was included on paid plans through June 22, then moved to usage credits. Access was suspended for non-US users on June 12, 2026 under a government directive. So this whole comparison is a launch-window snapshot, not a standing buyer’s guide. For many readers outside the US, the choice was already settled by the access pull, not by the merits.
The split verdict: who should pick which
The Reddit jury lands on a split verdict. Fable 5 wins on first-shot completeness, planning, debugging, vision, and agentic initiative, and the MineBench data backs the efficiency claim. The losses are token burn on capped plans, a quality edge that is real but uneven, and an access situation that made the question moot for many. If you do agentic or automated runs where failures cost real money, Fable’s higher per-run price tends to pay for itself. If you do interactive coding on a Max or Pro plan, the token burn argues for using it selectively: let it plan, then let a cheaper model build. Reddit increasingly aims that build step at a cheaper open challenger , the open-weight Kimi K3.