Fine-Tuning Gemma 4 with Unsloth on a Single GPU: A Practical Guide

Google’s Gemma 4 family - spanning the 2.3B E2B, 4.5B E4B, 26B MoE, and 31B dense variants - delivers frontier-level open-weight performance across text, vision, and audio. But general-purpose models still struggle with narrow, domain-specific tasks where you need consistent output formats, specialized terminology, or knowledge that wasn’t in the pretraining data. Fine-tuning fixes this, and Unsloth (version 2026.4.2 as of this writing) makes it possible on a single consumer GPU through custom CUDA kernels that cut VRAM by up to 60% and double training speed compared to standard Hugging Face + PEFT.
The short version: install Unsloth, load a Gemma 4 model with 4-bit QLoRA quantization, prepare your dataset in Alpaca or ChatML format, and train with SFTTrainer from Hugging Face TRL
. The E4B fits on a free Colab T4 (16 GB), and the 31B fits on an RTX 4090 (24 GB). Training 1,000 examples takes 15-40 minutes depending on model size. Export to GGUF when done and serve through Ollama
or llama.cpp
.

Why Fine-Tune Instead of Prompt Engineering
Prompt engineering and RAG work well for many tasks, but they hit limits. Every few-shot example eats into your context window, and retrieval adds latency and complexity. Fine-tuning bakes domain knowledge into the model weights themselves, which means:
- No token budget wasted on context: The model already knows your domain, so prompts stay short and inference stays fast.
- More consistent outputs: A fine-tuned model produces reliable formatting and terminology without fragile system prompts.
- Lower inference cost: A fine-tuned E4B (4.5B parameters) can match a prompted 31B model on your specific task at a fraction of the compute cost.
Typical fine-tuning use cases include customer support bots trained on company documentation, medical assistants grounded in clinical guidelines, code assistants that understand internal APIs, and content generators that match a specific editorial voice.
That said, try prompting and RAG first. Fine-tuning makes sense when you need the model to internalize patterns, not just retrieve information.
Hardware Requirements and VRAM Budget
Fine-tuning requires more memory than inference because you need to store optimizer states, gradients, and activations alongside the model weights. QLoRA - which quantizes the base model to 4-bit NormalFloat (NF4) and trains LoRA adapters in 16-bit - is the practical approach for single-GPU setups.
| Model | QLoRA VRAM | LoRA VRAM | Full Fine-Tune |
|---|---|---|---|
| E2B (2.3B) | ~6 GB | ~10 GB | ~16 GB |
| E4B (4.5B) | ~10 GB | ~18 GB | ~32 GB |
| 26B MoE (A4B) | ~18 GB | ~48 GB | Impractical |
| 31B Dense | ~22 GB | ~60 GB | ~80 GB+ |
The biggest factor here is Unsloth’s use_gradient_checkpointing="unsloth" flag. Standard gradient checkpointing trades compute for memory by recomputing activations during the backward pass. Unsloth’s version uses optimized recomputation patterns that cut VRAM by roughly 60% compared to naive gradient checkpointing.
Practical GPU recommendations:
- Free Colab T4 (16 GB): E4B with QLoRA fits comfortably. E2B runs with room to spare.
- RTX 4090 (24 GB): 31B with QLoRA at batch size 1-2 and gradient checkpointing. The 26B MoE at ~18 GB leaves headroom for batch size 2.
- Cloud options: RunPod offers RTX 4090 instances at $0.59/hr. Vast.ai marketplace prices start around $0.29/hr. A full fine-tuning run on 1,000 examples costs under $1.
Start with E4B to prototype your pipeline and validate your dataset. Scale to 31B once your hyperparameters are dialed in.
Dataset Preparation
Your dataset is the most important variable. 500 carefully curated examples will produce better results than 10,000 sloppy ones.
Format Options
Unsloth supports several dataset formats through the Hugging Face ecosystem:
- Alpaca format:
{"instruction": "...", "input": "...", "output": "..."}- good for single-turn instruction following. - ChatML / Messages format:
{"messages": [{"role": "user", "content": "..."}, {"role": "model", "content": "..."}]}- the native format for Gemma 4’s conversational template. - ShareGPT format: Multi-turn conversations with alternating human/assistant turns.
For Gemma 4, the messages format is recommended since it matches the model’s chat template directly.
Dataset Size Guidelines
| Task Type | Minimum Examples | Typical Range |
|---|---|---|
| Style/tone adaptation | 100-500 | 200-1,000 |
| Classification or extraction | 500-2,000 | 1,000-5,000 |
| Domain knowledge injection | 1,000-5,000 | 5,000-50,000 |
| Complex reasoning | 5,000+ | 10,000-50,000 |
Common Pitfalls
- Too few examples: The model memorizes instead of generalizing. If you have under 200 examples, consider data augmentation or synthetic data generation.
- Inconsistent formatting: Mixed instruction styles within the same dataset confuse the model. Standardize your templates.
- Label noise: A single contradictory example can undo the benefit of dozens of good ones. Deduplicate and verify.
- Missing holdout set: Always reserve 10-20% of your data for validation. Without it, you can’t detect overfitting.
Multimodal Datasets
Unsloth supports vision fine-tuning for the E2B and E4B models. Include image paths in your dataset entries alongside text for image-understanding tasks like document classification or visual QA.
Training Configuration
Bad hyperparameters can degrade a model rather than improve it. These defaults have been tested across various Gemma 4 fine-tuning runs and serve as reasonable starting points.
LoRA Settings
model = FastModel.get_peft_model(
model,
r=16, # LoRA rank: controls trainable parameters. Range: 8-64
lora_alpha=16, # Scaling factor. Common rule: alpha = rank
lora_dropout=0, # Unsloth recommends 0 for most fine-tunes
target_modules=[
"q_proj", "k_proj", "v_proj", "o_proj", # Attention projections
"gate_proj", "up_proj", "down_proj", # Feed-forward layers
],
)Higher rank means more trainable parameters and more capacity for adaptation, but also more VRAM. Rank 16 is a solid default. Increase to 32 or 64 if your domain is very different from the pretraining data. If lora_alpha is set equal to r, the effective learning rate is preserved. Setting alpha = 2 * r strengthens the adapter’s influence.
Training Hyperparameters
from trl import SFTTrainer, SFTConfig
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
args=SFTConfig(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
warmup_ratio=0.05,
num_train_epochs=1,
learning_rate=2e-4,
fp16=not torch.cuda.is_bf16_supported(),
bf16=torch.cuda.is_bf16_supported(),
output_dir="outputs",
gradient_checkpointing="unsloth",
),
)Key choices:
- Learning rate:
2e-4for QLoRA is the standard starting point. Drop to1e-4for the 31B model. - Batch size: 2 for 31B on 24 GB VRAM, 4-8 for E4B on 16 GB. Use
gradient_accumulation_stepsto simulate larger effective batches (batch_size * accumulation = effective batch). - Epochs: 1-3. More epochs risk overfitting, especially on small datasets. Monitor validation loss.
- Max sequence length: Start at 2048. Increase if your training examples are longer, but longer sequences consume proportionally more VRAM.
- Scheduler: Cosine with warmup is standard and works well. The warmup ratio of 0.03-0.1 prevents early instability.
MoE-Specific Considerations
For the 26B MoE model, target the attention projections and the shared expert FFN layers. Avoid fine-tuning the routing network unless you have 50,000+ examples - incorrect router weight updates can degrade the model’s ability to select the right experts.
Running the Training Loop
Below is the full workflow you’d follow in a Jupyter notebook or Python script.
Installation
pip install unslothThis pulls in the required dependencies including bitsandbytes , PEFT , and TRL. Make sure your CUDA toolkit version matches your PyTorch installation.
Loading the Model
from unsloth import FastModel
model, tokenizer = FastModel.from_pretrained(
"unsloth/gemma-4-31B-it-bnb-4bit", # Pre-quantized 4-bit model
max_seq_length=2048,
load_in_4bit=True,
)Unsloth provides pre-quantized model variants on Hugging Face (unsloth/gemma-4-E4B-it-bnb-4bit, unsloth/gemma-4-31B-it-bnb-4bit, etc.) which skip the quantization step and load faster.
Training
trainer.train()Monitor the loss curve during training.
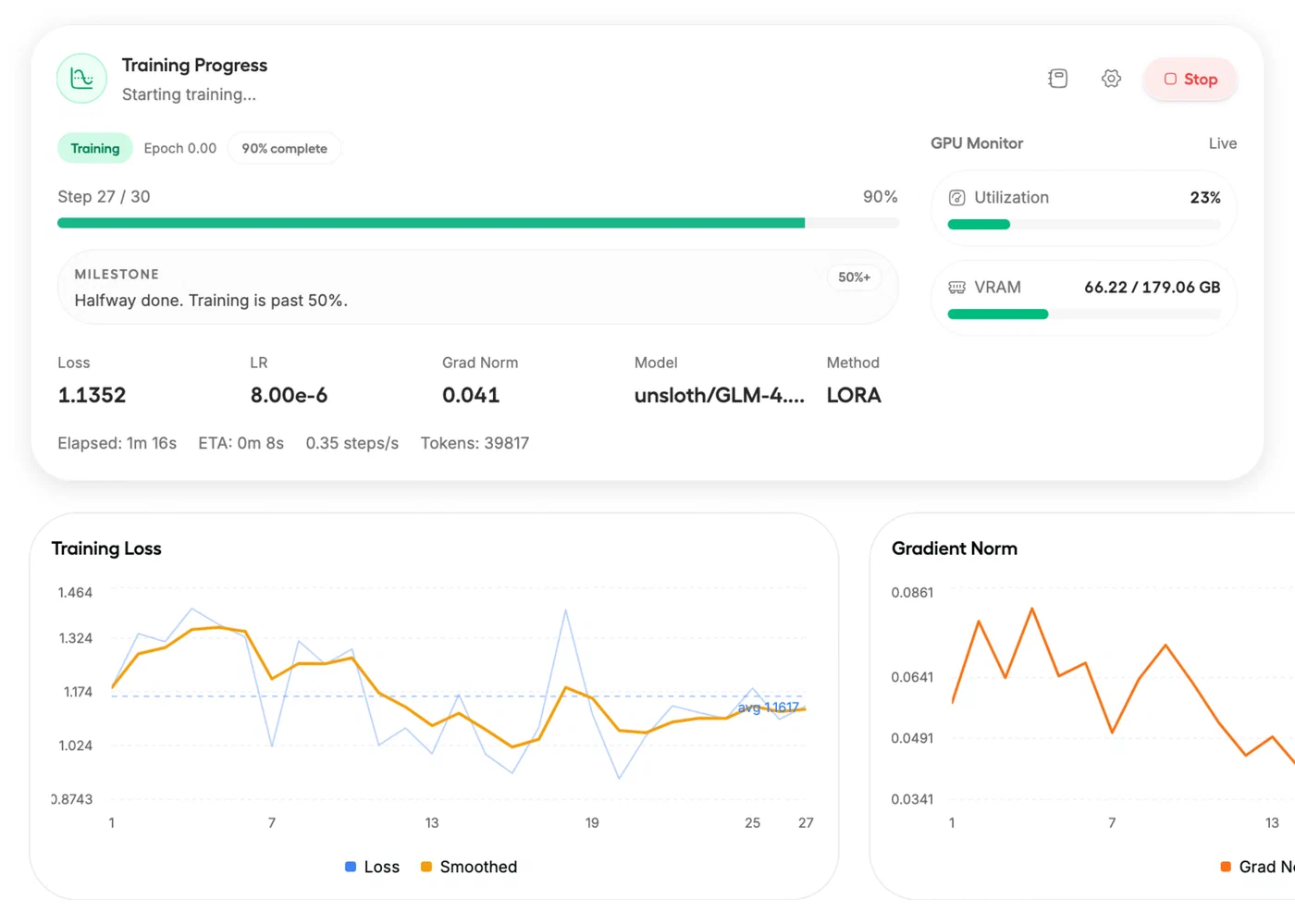
For small datasets (under 2,000 examples), expect the training loss to converge within 100-500 steps. If the loss plateaus early, your learning rate may be too low. If it spikes, it’s too high.
Typical training times:
- E4B QLoRA on T4 with 1,000 examples: 15-20 minutes
- 31B QLoRA on RTX 4090 with 1,000 examples: 25-40 minutes
Early Launch Caveats (Now Resolved)
When Gemma 4 first launched, older versions of Hugging Face Transformers didn’t recognize the gemma4 architecture, and PEFT couldn’t handle Gemma4ClippableLinear layers. These issues are fixed in current releases. If you hit them, update your packages: pip install -U transformers peft trl unsloth.
Evaluation and Export
Testing Your Fine-Tuned Model
Before deploying, check three things:
- Validation loss: Compare train loss vs. validation loss. If validation loss increases while training loss decreases, you’re overfitting. Reduce epochs or add more training data.
- Held-out examples: Run inference on examples the model hasn’t seen. Compare against ground truth for your specific metrics (accuracy, F1, BLEU, or whatever fits your task).
- Edge cases: Test adversarial inputs, boundary conditions, and the specific domain questions that the base model got wrong. This is where fine-tuning should show the biggest improvement.
Preventing Catastrophic Forgetting
A common concern with fine-tuning is that the model loses general capabilities while gaining domain-specific ones. LoRA naturally mitigates this since the base weights stay frozen, but it doesn’t eliminate the risk entirely. Practical defenses:
- Keep epochs low (1-3).
- Use a moderate learning rate (don’t go above
5e-4). - Include a small percentage of general-purpose examples in your training data to maintain broad capabilities.
- Test general knowledge and reasoning after fine-tuning, not just domain performance.
Exporting to GGUF
Once satisfied with evaluation results, export to GGUF format for deployment with Ollama or llama.cpp:
model.save_pretrained_gguf(
"gemma4-finetuned",
tokenizer,
quantization_method="q4_k_m", # Good balance of quality and size
)Available quantization options:
| Method | Quality | File Size | Use Case |
|---|---|---|---|
q4_k_m | Good | Smallest | Recommended default |
q8_0 | Higher | Medium | When quality matters more |
f16 | Full | Largest | Reference/debugging |
Deployment Options
For local serving, the quickest route is Ollama: create a Modelfile pointing to your GGUF and run ollama create my-model -f Modelfile. Alternatively, llama.cpp gives you a direct HTTP API with ./llama-server -m gemma4-finetuned-q4_k_m.gguf --port 8080. For production serving at scale, vLLM
can load the LoRA adapter on top of the base model without merging weights, which keeps your deployment flexible. You can also share your work on Hugging Face Hub
with model.push_to_hub("your-org/gemma4-finetuned").
If you want a single self-contained model file rather than a base + adapter pair, merge first with model.merge_and_unload() before exporting to GGUF.
Alternatives to Unsloth
Unsloth is the fastest option for single-GPU fine-tuning, but other tools have their own strengths.
The standard Hugging Face TRL + PEFT stack uses more VRAM but has broader community support and documentation. Google Vertex AI offers managed cloud fine-tuning where you don’t manage GPUs, at the cost of less control and higher prices. Axolotl uses YAML-driven configuration and supports more complex training setups, though the learning curve is steeper.
Worth mentioning: Unsloth Studio , released in March 2026, adds a no-code web UI for local fine-tuning.
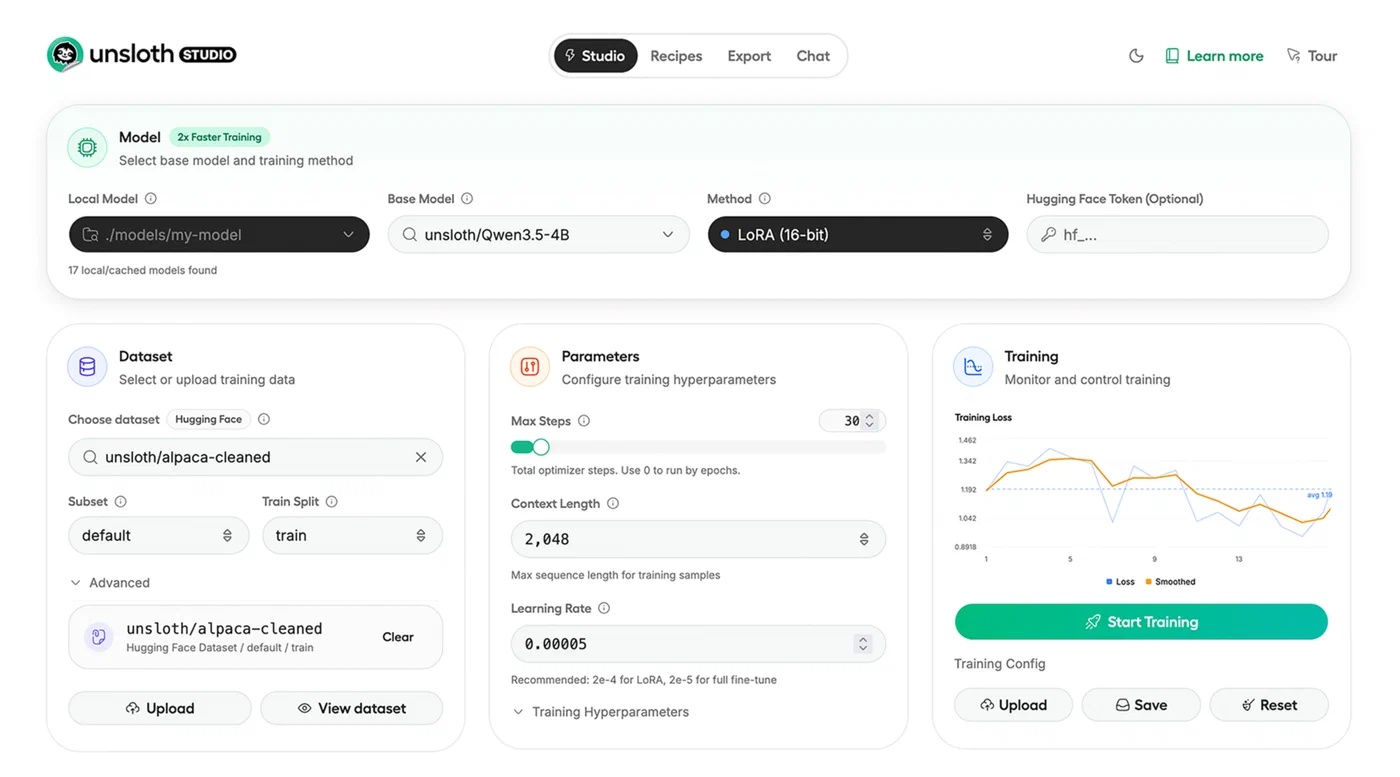
You upload a dataset, pick a model, and train through a browser interface with built-in loss monitoring and model comparison. Good option if you’d rather not write training scripts.
For multi-GPU setups, DeepSpeed or FSDP with the standard Hugging Face stack is the established approach. Unsloth Studio is adding multi-GPU support as well, though it wasn’t available at time of writing.
Quick Reference
| Step | Command / Setting |
|---|---|
| Install | pip install unsloth |
| Load model | FastModel.from_pretrained("unsloth/gemma-4-E4B-it-bnb-4bit", load_in_4bit=True) |
| Add LoRA | FastModel.get_peft_model(model, r=16, lora_alpha=16) |
| Train | SFTTrainer(..., args=SFTConfig(gradient_checkpointing="unsloth")) |
| Export GGUF | model.save_pretrained_gguf("output", tokenizer, quantization_method="q4_k_m") |
| Deploy | ollama create my-model -f Modelfile |
The full workflow - from pip install to a deployed GGUF model - fits in under 50 lines of Python and takes under an hour on consumer hardware. Start with E4B and a small dataset to validate your approach, then scale up.