Feature Flags DIY: 100-Line SDK vs. LaunchDarkly Cost

You can build a fully functional feature flag system using a JSON configuration file, environment variable overrides, and a single evaluation function in roughly 100 lines of Python. This gives you gradual rollouts, kill switches, and per-environment toggles without paying for LaunchDarkly , Unleash , or any other SaaS platform. The core pattern is straightforward: define each flag with a name, a boolean or percentage-based rule, and a list of target environments, then evaluate it at runtime through a thin SDK you own and control completely.
That does not mean commercial platforms are pointless. They offer dashboards, audit logs, and team management features that matter at scale. But for most projects - especially early-stage products, internal tools, and teams that want full control over their infrastructure - a homegrown solution gets the job done with zero external dependencies and zero per-seat costs.
What Feature Flags Actually Do and When You Need Them
A feature flag is a runtime conditional that controls whether a code path executes. At its simplest, the pattern looks like this:
if flag_enabled("new_checkout"):
use_new_checkout()
else:
use_old_checkout()The point of this pattern is that it decouples deployment from release. You can ship code to production that users never see until you flip a toggle. This opens up four categories of flags, each solving a different problem.
Release flags gate incomplete features so you can merge to main continuously without exposing half-built functionality. This is how trunk-based development works in practice - the feature sits behind a disabled flag until it is complete, tested, and reviewed, which eliminates long-lived feature branches and the merge conflicts that come with them.
Ops flags are kill switches. Wrapping a call to an external API with if flag_enabled("enable_payment_provider") means you can disable that dependency in production within seconds when it starts throwing errors. Flip the flag instead of deploying a rollback.
Experiment flags route a percentage of traffic to a variant for A/B testing or canary releases. Five percent of users see the new recommendation algorithm while ninety-five percent see the existing one. You monitor error rates and performance, then ramp up gradually.
Permission flags restrict access to specific users, teams, or environments. Show the admin panel only to users in the beta_testers group. Enable the debug toolbar only in staging. These give you an access control layer you can adjust without touching code.
SaaS flag services cover all of these use cases with polished UIs and SDKs, but they come with trade-offs. LaunchDarkly’s Foundation plan starts at $12 per service connection per month plus $10 per 1,000 client-side MAU. Unleash Enterprise runs $75 per seat per month with a five-seat minimum. Flagsmith offers a free tier capped at 50,000 requests. For a small team running a handful of services, a self-built system avoids the external dependency, the network latency on every flag evaluation, and the monthly bill entirely.

Designing the Flag Configuration Schema
The whole system starts with a well-structured configuration file. Store flags in a flags.json file at the project root (or /etc/myapp/flags.json for deployed services) with a flat dictionary structure keyed by flag name.
Here is a complete example with six realistic flags covering all four flag types:
{
"version": 2,
"flags": {
"new_checkout": {
"enabled": true,
"description": "Redesigned checkout flow with single-page layout",
"environments": ["staging", "production"],
"rollout_percentage": 25,
"user_groups": [],
"expires": "2026-08-01"
},
"dark_mode": {
"enabled": true,
"description": "Dark mode theme toggle for all users",
"environments": ["staging", "production"],
"rollout_percentage": 100,
"user_groups": [],
"expires": "2026-06-15"
},
"enable_payment_provider_v2": {
"enabled": false,
"description": "Kill switch for new payment provider integration",
"environments": ["production"],
"rollout_percentage": 100,
"user_groups": [],
"expires": "2026-09-01"
},
"experimental_search": {
"enabled": true,
"description": "ML-powered search results ranking",
"environments": ["staging"],
"rollout_percentage": 10,
"user_groups": ["internal"],
"expires": "2026-07-01"
},
"admin_debug_panel": {
"enabled": true,
"description": "Extended debug panel in admin interface",
"environments": ["staging", "development"],
"rollout_percentage": 100,
"user_groups": ["beta_testers", "internal"],
"expires": "2026-12-31"
},
"bulk_export": {
"enabled": true,
"description": "CSV/JSON bulk export for user data",
"environments": ["staging", "production"],
"rollout_percentage": 50,
"user_groups": [],
"expires": "2026-06-01"
}
}
}Each flag object contains five fields. enabled is the master toggle - when false, the flag is off regardless of any other rule. environments limits where the flag is active. rollout_percentage controls what fraction of users see the feature (0 through 100). user_groups restricts the flag to specific cohorts for permission-style flags. expires marks when the flag should be cleaned up, which is critical for preventing flag debt.
Environment variable overrides follow the convention FLAG_<NAME>=true|false. For example, FLAG_NEW_CHECKOUT=true forces the flag on regardless of JSON configuration. This lets ops teams toggle flags per-deployment without editing files - useful in container orchestration where each instance might need different behavior.
The top-level version field lets the evaluation SDK handle backward-compatible changes to the schema. When you add new fields to flag objects in the future, older SDKs can detect the version mismatch and either handle it gracefully or raise a clear error.
Building the Evaluation SDK
The SDK is a single Python module that loads configuration, evaluates flags, and returns a boolean. Here is the complete implementation:
"""feature_flags.py - Lightweight feature flag evaluation SDK."""
import hashlib
import json
import logging
import os
import threading
from datetime import date
from pathlib import Path
from typing import Optional
logger = logging.getLogger(__name__)
_config: dict | None = None
_config_lock = threading.Lock()
_config_path: Path = Path("flags.json")
def _load_config(path: Optional[Path] = None) -> dict:
"""Load and parse the flag configuration file."""
target = path or _config_path
with open(target, "r") as f:
return json.load(f)
def init(config_path: str = "flags.json") -> None:
"""Initialize the flag system. Call once at startup."""
global _config, _config_path
_config_path = Path(config_path)
with _config_lock:
_config = _load_config(_config_path)
logger.info("Feature flags loaded from %s", config_path)
def reload_flags() -> None:
"""Hot-reload flags from disk without restarting the process."""
global _config
with _config_lock:
_config = _load_config(_config_path)
logger.info("Feature flags reloaded from %s", _config_path)
def _get_config() -> dict:
"""Return current config, loading from disk if not yet initialized."""
global _config
if _config is None:
with _config_lock:
if _config is None:
_config = _load_config()
return _config
def _check_rollout(flag_name: str, user_id: str, percentage: int) -> bool:
"""Deterministic percentage-based rollout using SHA-256 hashing."""
hash_input = f"{flag_name}:{user_id}".encode("utf-8")
hash_bytes = hashlib.sha256(hash_input).digest()
hash_int = int.from_bytes(hash_bytes[:4], byteorder="big")
return (hash_int % 100) < percentage
def flag_enabled(
flag_name: str,
user_id: Optional[str] = None,
environment: Optional[str] = None,
user_group: Optional[str] = None,
) -> bool:
"""Evaluate whether a feature flag is enabled.
Args:
flag_name: The flag identifier matching a key in flags.json.
user_id: Optional user ID for percentage-based rollouts.
environment: Override for current environment. Defaults to APP_ENV.
user_group: The group the current user belongs to.
Returns:
True if the flag is enabled for the given context, False otherwise.
"""
# Check environment variable override first
env_override = os.environ.get(f"FLAG_{flag_name.upper()}")
if env_override is not None:
return env_override.lower() in ("true", "1")
config = _get_config()
flags = config.get("flags", config) # Support both nested and flat formats
flag = flags.get(flag_name)
if flag is None:
logger.warning("Unknown feature flag: %s", flag_name)
return False # Fail closed
# Master toggle check
if not flag.get("enabled", False):
return False
# Environment check
current_env = environment or os.environ.get("APP_ENV", "development")
allowed_envs = flag.get("environments", [])
if allowed_envs and current_env not in allowed_envs:
return False
# User group check
allowed_groups = flag.get("user_groups", [])
if allowed_groups:
if user_group is None or user_group not in allowed_groups:
return False
# Expiry warning
expires = flag.get("expires")
if expires:
try:
expiry_date = date.fromisoformat(expires)
if date.today() > expiry_date:
logger.warning(
"Feature flag '%s' expired on %s - schedule removal",
flag_name,
expires,
)
except ValueError:
pass
# Percentage-based rollout
rollout = flag.get("rollout_percentage", 100)
if rollout < 100 and user_id:
return _check_rollout(flag_name, user_id, rollout)
elif rollout < 100 and not user_id:
return False # Cannot evaluate percentage without a user ID
return TrueA few design decisions worth noting in this implementation.
The SDK fails closed on unknown flags. If someone calls flag_enabled("nwe_checkout") with a typo, it returns False and logs a warning. This catches mistakes quickly without breaking production.
Environment variable overrides take absolute priority. Checking os.environ.get(f"FLAG_{flag_name.upper()}") before touching the JSON config means ops teams can force any flag on or off instantly through container environment variables, Kubernetes ConfigMaps, or a simple export command.
The percentage rollout is deterministic. Hashing flag_name:user_id with SHA-256 and taking the first four bytes mod 100 ensures that the same user always lands on the same side of the rollout boundary. No database needed to track assignments. The hash is uniform enough that a 25% rollout will consistently route roughly 25% of distinct user IDs to the enabled path.
Thread safety comes from _config_lock, a threading lock that protects the _config dictionary during reload. In a multi-threaded server (like a threaded Flask or Django deployment), one thread calling reload_flags() while another calls flag_enabled() will not cause a corrupted read. The lock is only held during the file read and dictionary swap, so contention is minimal. For async servers using asyncio, you would swap threading.Lock for asyncio.Lock and make the I/O calls awaitable.
Go Implementation
The same pattern translates cleanly to Go
. The key difference is using sync.RWMutex for concurrent access:
package featureflags
import (
"crypto/sha256"
"encoding/binary"
"encoding/json"
"fmt"
"os"
"strings"
"sync"
)
type Flag struct {
Enabled bool `json:"enabled"`
Environments []string `json:"environments"`
RolloutPercentage int `json:"rollout_percentage"`
UserGroups []string `json:"user_groups"`
Description string `json:"description"`
Expires string `json:"expires"`
}
type Config struct {
Version int `json:"version"`
Flags map[string]Flag `json:"flags"`
}
var (
config *Config
configLock sync.RWMutex
)
func Init(path string) error {
configLock.Lock()
defer configLock.Unlock()
data, err := os.ReadFile(path)
if err != nil {
return err
}
config = &Config{}
return json.Unmarshal(data, config)
}
func FlagEnabled(name, userID, env string) bool {
envOverride := os.Getenv("FLAG_" + strings.ToUpper(name))
if envOverride == "true" || envOverride == "1" {
return true
}
if envOverride == "false" || envOverride == "0" {
return false
}
configLock.RLock()
defer configLock.RUnlock()
flag, exists := config.Flags[name]
if !exists || !flag.Enabled {
return false
}
if len(flag.Environments) > 0 {
found := false
for _, e := range flag.Environments {
if e == env { found = true; break }
}
if !found { return false }
}
if flag.RolloutPercentage < 100 && userID != "" {
hash := sha256.Sum256([]byte(fmt.Sprintf("%s:%s", name, userID)))
val := binary.BigEndian.Uint32(hash[:4]) % 100
return int(val) < flag.RolloutPercentage
}
return true
}Go’s sync.RWMutex gives you a read-write lock where multiple goroutines can read the config simultaneously, but writes (reloads) acquire exclusive access. This is more efficient than a plain mutex in read-heavy workloads, which is exactly the pattern for flag evaluation.
JavaScript/TypeScript Implementation
For Node.js applications:
import { createHash } from "crypto";
import { readFileSync } from "fs";
interface Flag {
enabled: boolean;
environments: string[];
rollout_percentage: number;
user_groups: string[];
description: string;
expires: string;
}
interface FlagConfig {
version: number;
flags: Record<string, Flag>;
}
let config: FlagConfig | null = null;
export function init(path: string = "flags.json"): void {
const raw = readFileSync(path, "utf-8");
config = JSON.parse(raw);
}
export function flagEnabled(
name: string,
userId?: string,
env?: string
): boolean {
const envOverride = process.env[`FLAG_${name.toUpperCase()}`];
if (envOverride === "true" || envOverride === "1") return true;
if (envOverride === "false" || envOverride === "0") return false;
if (!config) init();
const flag = config!.flags[name];
if (!flag || !flag.enabled) return false;
const currentEnv = env || process.env.APP_ENV || "development";
if (flag.environments.length > 0 && !flag.environments.includes(currentEnv))
return false;
if (flag.rollout_percentage < 100 && userId) {
const hash = createHash("sha256").update(`${name}:${userId}`).digest();
const val = hash.readUInt32BE(0) % 100;
return val < flag.rollout_percentage;
}
return flag.rollout_percentage >= 100;
}Node.js is single-threaded by default, so the JavaScript version does not need a lock for hot-reloading. A simple fs.watch callback calling init() is sufficient for picking up config changes. If you use worker threads, wrap the config in a SharedArrayBuffer or pass updated configs via message channels.
Gradual Rollouts and Kill Switches in Practice
The code above is the entire SDK, but the real value of feature flags shows up in how you use them during incidents and releases.
In a canary rollout, you start at 1% rollout, monitor error rates and latency for 30 minutes, bump to 10%, wait again, then 50%, then 100%. Each step is a single edit to flags.json or an environment variable change with no deployment needed. For the full production deployment pipeline, see our guide on deploying with Docker Compose and Traefik
. If errors spike at 10%, drop back to 1% while you investigate. The deterministic hashing means the same 1% of users stay in the experiment throughout, giving you consistent behavior to debug.
The kill switch pattern wraps calls to flaky external services in a flag check. When the service starts returning 500s, set FLAG_ENABLE_PAYMENT_PROVIDER_V2=false to fall back to the old integration. The turnaround time is however long it takes to set an environment variable - seconds, compared to the 10-15 minutes a typical deployment takes.
For trunk-based development, developers merge incomplete features behind disabled flags every day. The main branch is always deployable because unfinished code never executes in production. This eliminates the pain of long-lived feature branches, which are a leading cause of merge conflicts and integration problems. When the feature is ready, enable the flag in staging, test, then roll out to production.
Admin Endpoint for Flag Inspection
For production visibility, expose a /flags endpoint that returns the current state of all flags. Protect it with authentication so only your team can access it:
from flask import Flask, jsonify
app = Flask(__name__)
@app.route("/flags")
def get_flags():
"""Return current flag states for debugging. Requires auth."""
config = _get_config()
return jsonify(config)On-call engineers can hit this endpoint to verify flag states without SSH access to the server. Pair it with a simple CLI tool for toggling flags from the command line. For building polished terminal tools, see our guide on building CLI tools with Cobra and Bubble Tea .
"""flag_cli.py - Toggle feature flags from the command line."""
import json
import sys
def toggle(config_path: str, flag_name: str, enabled: bool) -> None:
with open(config_path, "r") as f:
config = json.load(f)
if flag_name not in config["flags"]:
print(f"Unknown flag: {flag_name}")
sys.exit(1)
config["flags"][flag_name]["enabled"] = enabled
with open(config_path, "w") as f:
json.dump(config, f, indent=2)
print(f"Flag '{flag_name}' set to {enabled}")
if __name__ == "__main__":
toggle(sys.argv[1], sys.argv[2], sys.argv[3].lower() == "true")For multi-instance deployments where a JSON file on disk will not cut it (each instance has its own file), swap the file backend for a database. SQLite works for single-node setups. For distributed systems, use Redis or PostgreSQL as the flag store. Manage schema changes with version-controlled migrations like Alembic to keep your flag store in sync across deployments.
Integration with FastAPI
Feature flags work well as a FastAPI dependency:
from fastapi import Depends, FastAPI, HTTPException
app = FastAPI()
def require_flag(flag_name: str):
"""FastAPI dependency that gates a route behind a feature flag."""
def check():
if not flag_enabled(flag_name, environment="production"):
raise HTTPException(status_code=404)
return Depends(check)
@app.get("/new-dashboard", dependencies=[require_flag("new_dashboard")])
async def new_dashboard():
return {"message": "Welcome to the new dashboard"}For Django , add a middleware that checks flags before routing:
class FeatureFlagMiddleware:
def __init__(self, get_response):
self.get_response = get_response
self.flag_routes = {"/new-dashboard/": "new_dashboard"}
def __call__(self, request):
for path, flag in self.flag_routes.items():
if request.path.startswith(path) and not flag_enabled(flag):
return HttpResponseNotFound()
return self.get_response(request)Testing, Cleanup, and Avoiding Flag Debt
Feature flags rot quickly without active cleanup. Every flag you add is a branch in your code that doubles the number of states your system can be in. Two flags mean four states. Ten flags mean 1,024. This combinatorial explosion is why cleanup discipline matters as much as the implementation itself.
Every feature behind a flag needs at least two test cases - one with the flag enabled and one disabled. Use a pytest fixture that patches flag_enabled. For a more robust testing approach, consider property-based testing with Hypothesis
to automatically generate edge-case inputs.
import pytest
@pytest.fixture(params=[True, False])
def new_checkout_flag(request, monkeypatch):
monkeypatch.setenv("FLAG_NEW_CHECKOUT", str(request.param).lower())
return request.param
def test_checkout_flow(new_checkout_flag):
if new_checkout_flag:
assert checkout_page() == "new_layout"
else:
assert checkout_page() == "classic_layout"You should also set up a CI gate for expired flags. Write a pre-commit hook or CI step that parses flags.json, checks each flag’s expires date, and fails the build when any flag is past its expiration:
"""check_expired_flags.py - CI gate for flag expiry."""
import json
import sys
from datetime import date
with open("flags.json") as f:
config = json.load(f)
expired = []
for name, flag in config["flags"].items():
if flag.get("expires"):
if date.fromisoformat(flag["expires"]) < date.today():
expired.append(f" {name} (expired {flag['expires']})")
if expired:
print("Expired feature flags found:")
print("\n".join(expired))
sys.exit(1)Removing a flag safely takes five steps: (1) set rollout to 100% for at least two weeks, (2) verify no errors or rollbacks during that period, (3) remove the flag_enabled check from the code, (4) remove the flag entry from flags.json, (5) deploy. Do not skip step 1 - running at full rollout proves the feature is stable before you remove the safety net.
Track flag count as a project metric. If a single service has more than 20 active flags, you have flag debt. Set a team policy: every sprint, remove at least one expired flag. Make it part of your definition of done.
After removing a flag from flags.json, stale calls to flag_enabled("removed_flag") will silently return False (fail closed). Write a custom Ruff
or flake8 rule that cross-references flag_enabled() calls against the keys in flags.json and flags any mismatches during CI.
DIY Flags vs. the Alternatives
| Feature | DIY (this post) | LaunchDarkly | Unleash (OSS) | Flipt | OpenFeature SDK |
|---|---|---|---|---|---|
| Cost | Free | From $12/svc/mo + MAU | Free (self-host) or $75/seat/mo | Free (GPL-3.0) | Free (CNCF) |
| Setup time | 30 minutes | 1-2 hours | 1-2 hours | 30-60 minutes | Varies by provider |
| Dashboard | None (JSON + CLI) | Full web UI | Web UI | Web UI + GitOps | Depends on provider |
| A/B testing | Percentage rollout only | Built-in with analytics | Basic via strategies | No | Provider-dependent |
| Audit log | Manual (git history) | Built-in | Built-in | Git history | Provider-dependent |
| Multi-language SDKs | Build per language | 25+ SDKs | 15+ SDKs | Go, REST, gRPC | Standardized across languages |
| Vendor lock-in | None | High | Low (OSS core) | None | None (vendor-neutral spec) |
| External dependency | None | Yes (SaaS) | Optional (self-host) | None (single binary) | Depends on provider |
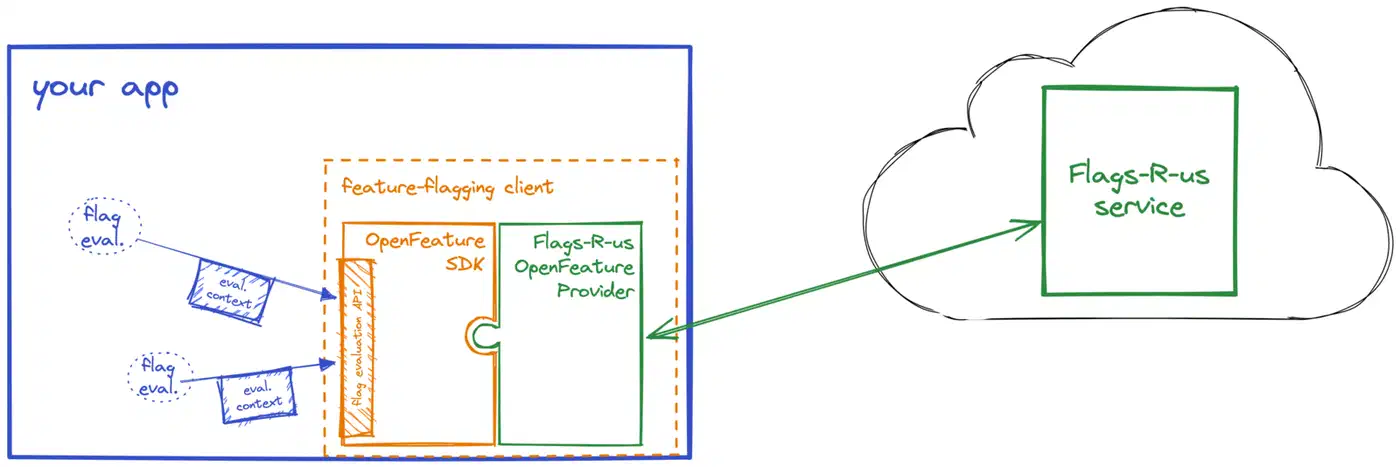
OpenFeature is worth knowing about. It is a CNCF incubating project that defines a vendor-neutral API for feature flagging. If you build your DIY system today but think you might migrate to a commercial platform later, implementing the OpenFeature provider interface means your application code never changes - you just swap the backend. Flipt already supports OpenFeature natively, and most commercial platforms have adapters.
The DIY approach works best when you have fewer than 50 flags, a small team (under 20 developers), and you value control over convenience. Once you exceed those thresholds, the audit logging, role-based access, and dashboard features of commercial platforms start earning their cost.