Qwen3.6-35B-A3B: Alibaba's open-weight coding MoE

Qwen3.6-35B-A3B is Alibaba Cloud’s Apache 2.0 sparse Mixture-of-Experts model released April 14, 2026. It carries 35 billion total parameters but activates only about 3 billion per token, and on agentic coding suites it beats Gemma 4-31B and matches Claude Sonnet 4.5 on most vision tasks. A 20.9GB Q4 quantization runs on a MacBook Pro M5, which is the reason this release has taken over half the AI timeline for the past week.
The economics are what make this release noteworthy rather than just another open-weight announcement. When only 3B parameters fire per token, you get the inference cost of a small model with the capability ceiling of something closer to a 30B dense flagship, at least on the specific workloads this model was tuned for. For repo-level coding agents running on a single workstation, that shifts the practical calculus in a way that previous open releases never quite managed. Alibaba’s image sibling, Qwen-Image , earns the same praise for legible in-image text among local generators.
What Qwen3.6-35B-A3B Actually Is (and Why the A3B Suffix Matters)
Readers see “35B parameters” and assume a flagship-scale dense model that needs a multi-GPU server to run. The A3B suffix, shorthand for “activated 3 billion,” reframes that assumption. All 35B weights sit on disk and in GPU memory, but any given forward pass routes through roughly 3B of them. You pay the storage cost of a large model and the compute cost of a small one.
The Mixture-of-Experts layout backs this up with concrete numbers. The model contains 256 total experts, of which 8 routed experts plus 1 shared expert activate per token, each with an expert intermediate dimension of 512. A dense 30B-class model fires every parameter every step, while a sparse MoE pulls only the few experts the router thinks are relevant to the current token. That is where the efficiency comes from.
Attention does the other half of the work. The 40 transformer layers are arranged as 10 repeated blocks, each block being three Gated DeltaNet layers (linear attention) followed by one Gated Attention layer (full attention), with an MoE block after each attention pass. Linear attention is cheap at long context but weak on information retrieval across the window, and periodic full-attention layers repair that weakness. This hybrid attention and MoE layout has become the default for 2026-era efficient architectures, and Qwen3.6 is the clearest Apache-2.0 implementation of it so far.
Multi-Token Prediction adds the final lever. MTP heads are baked into the model, which lets SGLang and vLLM perform speculative decoding without needing a separate draft model. In practice this translates to meaningful tokens-per-second gains on the same hardware, with no extra deployment complexity.
For ecosystem context: the release landed roughly a month after Junyang Lin’s March 2026 departure as Qwen’s technical lead, and momentum has clearly been preserved. Qwen now reports more than 600 million downloads and 170,000 derivative models on Hugging Face, surpassing Meta’s Llama family in raw adoption. The weights live on Hugging Face
as Qwen/Qwen3.6-35B-A3B, and the announcement is on the Qwen blog
.
The Benchmark Story: Where It Beats Gemma 4-31B and Matches Sonnet 4.5
Benchmarks are the reason this release matters, but a wall of scores obscures what is load-bearing. Cluster the numbers by capability and the picture gets clearer. Agentic coding is where Qwen3.6 leads for its weight class, math and reasoning are top-tier among open weights, and vision matches a dense frontier model without leading it.
The agentic coding results are the headline. A 3B-active sparse model is posting scores against a 31B dense competitor and winning by double-digit margins on every coding benchmark the team reports.
| Benchmark | Qwen3.6-35B-A3B | Gemma 4-31B | Claude Sonnet 4.5 |
|---|---|---|---|
| SWE-bench Verified | 73.4 | 52.0 | 72.1 |
| SWE-bench Pro | 49.5 | 35.7 | 48.9 |
| SWE-bench Multilingual | 67.2 | 51.7 | 66.0 |
| Terminal-Bench 2.0 | 51.5 | 42.9 | 50.8 |
| AIME 2026 | 92.7 | 84.1 | 90.5 |
| GPQA Diamond | 86.0 | 79.4 | 84.7 |
| MMLU-Pro | 85.2 | 80.1 | 85.0 |
| MMMU (vision) | 81.7 | - | 82.3 |
| RefCOCO (grounding) | 92.0 | - | 88.1 |
Reasoning and math are the second cluster worth attention. GPQA Diamond at 86.0, AIME 2026 at 92.7, and HMMT February 2026 at 83.6 put this model at the top of any open-weight leaderboard for the quarter. General knowledge tracks the same pattern: MMLU-Pro 85.2, MMLU-Redux 93.3, and C-Eval 90.0, where strong Chinese knowledge is expected and delivered given the training mix.
Vision-language is the most nuanced part of the story. MMMU 81.7, MathVista-mini 86.4, RealWorldQA 85.3, MMBench EN-DEV v1.1 92.8, OmniDocBench 1.5 89.9, and VideoMMU 83.7 track Claude Sonnet 4.5 closely on most tasks. Qwen3.6 pulls ahead on spatial grounding, where RefCOCO at 92.0 and ODInW13 at 50.8 are stronger than what Sonnet 4.5 publishes. On general visual reasoning, call it a tie rather than a win.
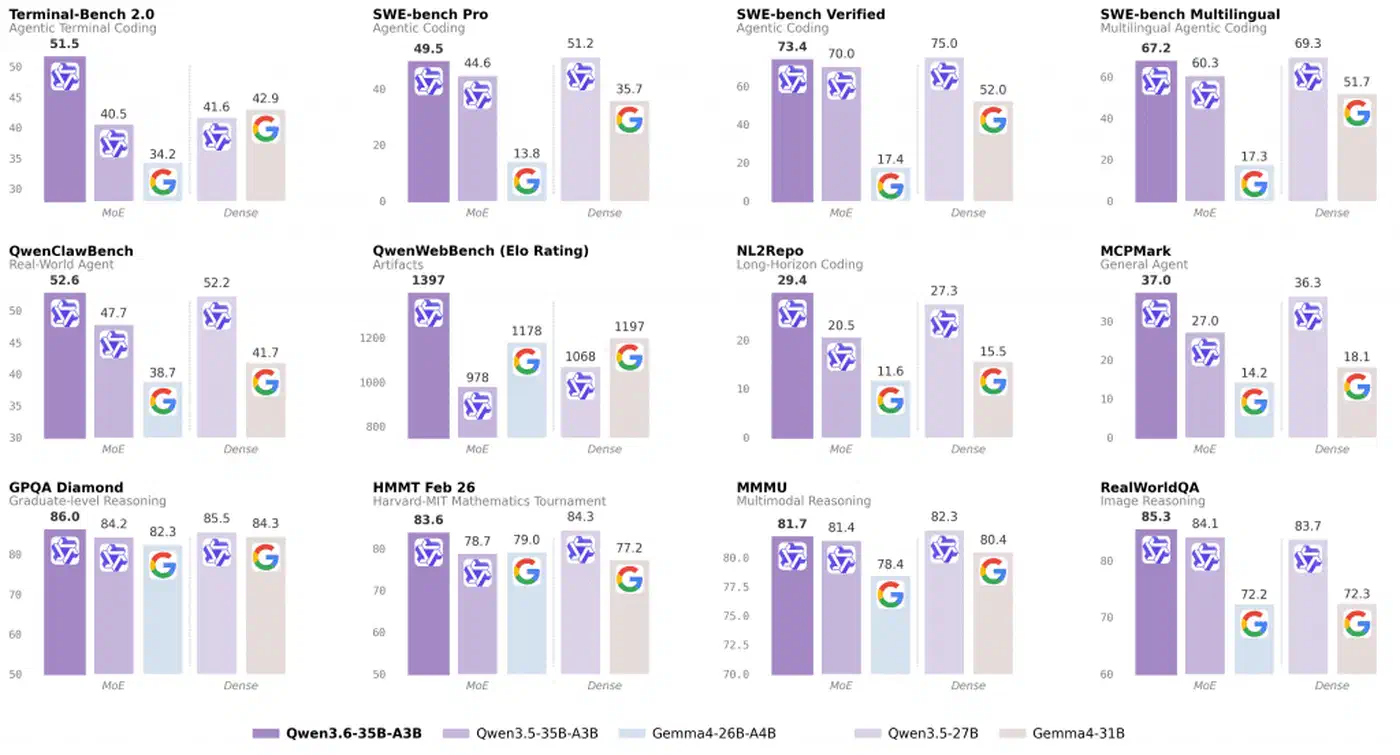
One caveat on all of this: these numbers are vendor-reported on public suites. They are reproducible in principle, but they have not been independently replicated at the time of writing. Treat them as the strongest published claims rather than settled ground truth. The officechai comparison coverage is a useful third-party summary while the community replicates results.
Agentic Coding Features: Thinking Preservation, Tool Calling, and the 262k Context Window
Benchmarks sell the model; features decide whether it fits into a real development workflow. The native 262,144-token context is extensible to roughly 1,010,000 tokens with YaRN rope scaling. At those lengths, whole-repo analysis, full documentation-set ingestion, and multi-hour agent runs all become tractable on a single deployment without aggressive chunking.
The model exposes two sampling modes. Thinking mode runs at temperature 1.0, top-p 0.95, top-k 20, and presence penalty 1.5, and it is the default. Instruct mode uses temperature 0.7 and top-p 0.8. For coding specifically, the release notes recommend temperature 0.6. Getting these right matters more than usual because the hybrid attention layout is sensitive to sampling pressure on long contexts.
The new feature in this release is the preserve_thinking flag. Pass chat_template_kwargs: {"preserve_thinking": true} through the chat template and prior-turn reasoning traces ride along into subsequent turns rather than being stripped. For iterative agent loops this is a real improvement. The agent does not recompute a fresh plan on every step, redundant thought tokens stop being emitted, and the conversation remembers its own reasoning between tool calls. Qwen2-era agents had to reconstruct this by hand with external memory stores, which was always fragile.
Tool calling uses the qwen3_coder parser. On vLLM you enable it with --enable-auto-tool-choice --tool-call-parser qwen3_coder, and you get proper structured tool invocations instead of the JSON-mode workarounds that Qwen2 demanded. The model also plays cleanly with Qwen-Agent
and MCP servers, so the same tool stack you already run with Claude Code slots straight in. The Qwen Code CLI
is the open-weight counterpart to Claude Code, Cursor’s agent mode, and OpenAI’s Rust-powered Codex agent
, and it is what most of the early adopters are driving repo-level work through.
Running It Locally or in Production: SGLang, vLLM, and the Laptop Quantization
This is where developers want copy-pasteable commands. Both the production path and the laptop path are reasonable with Qwen3.6, which is not something I can say for most open-weight releases at this scale.
For SGLang v0.5.10 or newer, the serving command is:
python -m sglang.launch_server \
--model-path Qwen/Qwen3.6-35B-A3B \
--port 8000 \
--tp-size 8 \
--context-length 262144 \
--reasoning-parser qwen3For vLLM v0.19.0 or newer with tool use:
vllm serve Qwen/Qwen3.6-35B-A3B \
--port 8000 \
--tensor-parallel-size 8 \
--max-model-len 262144 \
--reasoning-parser qwen3 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coderSpeculative decoding through MTP on SGLang adds noticeable throughput on the same hardware:
--speculative-algo NEXTN \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4For heterogeneous CPU-GPU setups, KTransformers remains the right tool. MoE sparsity is the reason. Because only 8 of 256 experts fire per token, offloading the inactive experts to system RAM costs less than it would on a dense model of the same total size. On a single RTX 4090 paired with 128GB of DDR5 and KTransformers, you can get useful tokens per second out of a model this large, which was not true for dense 30B-class models under the same setup.
The laptop path is where this release breaks new ground. Simon Willison’s April 16 writeup
documents running the 20.9GB Unsloth Qwen3.6-35B-A3B-UD-Q4_K_S.gguf on a MacBook Pro M5 through LM Studio and the llm-lmstudio plugin.

unsloth/Qwen3.6-35B-A3B-GGUF on Hugging Face. A dynamic 4-bit quantization fits comfortably on a 24GB-unified-memory Mac, with room left over for the OS and whatever else you are running. For pushing past the native 262k context, the rope_scaling field in config.json takes the YaRN parameters.
Teams that prefer not to self-host can reach the model through Alibaba Cloud Model Studio as qwen3.6-flash. Exact per-million-token pricing on this specific variant is not public at time of writing; the Qwen3.6-Plus tier is listed at around 2 RMB per million input tokens in mainland China and roughly $0.325 per million input tokens through third-party platforms like OpenRouter
, which gives a rough anchor.
The Honest Assessment: Where It Wins, Where It Doesn’t
Readers are rightly skeptical of vendor launches, and the correct framing here is a narrow one. Qwen3.6-35B-A3B wins in specific places, ties in a few others, and does not dethrone dense frontier models on the workloads those frontier models are still built for.
Concrete strengths include: agentic coding benchmarks against models with 10 times its active parameter count, local inference at useful speed on a single high-end laptop (which no prior open release in this capability class could claim), an Apache 2.0 license that clears procurement for most enterprises, and a 1-million-token context ceiling via YaRN that extends past Claude Sonnet’s window.
The pelican test is the most quoted anecdote and worth calibrating carefully. Willison asked the model to produce an SVG of a pelican riding a bicycle, a task he has used for years as a smoke test for visual reasoning. Qwen3.6 produced a correctly-shaped bicycle frame; Claude Opus 4.7 did not.

On the flamingo-on-unicycle follow-up, Qwen added sunglasses, a bowtie, and left a cheeky SVG comment reading <!-- Sunglasses on flamingo! -->. Entertaining, but a narrow signal about creative illustration rather than a general capability claim.
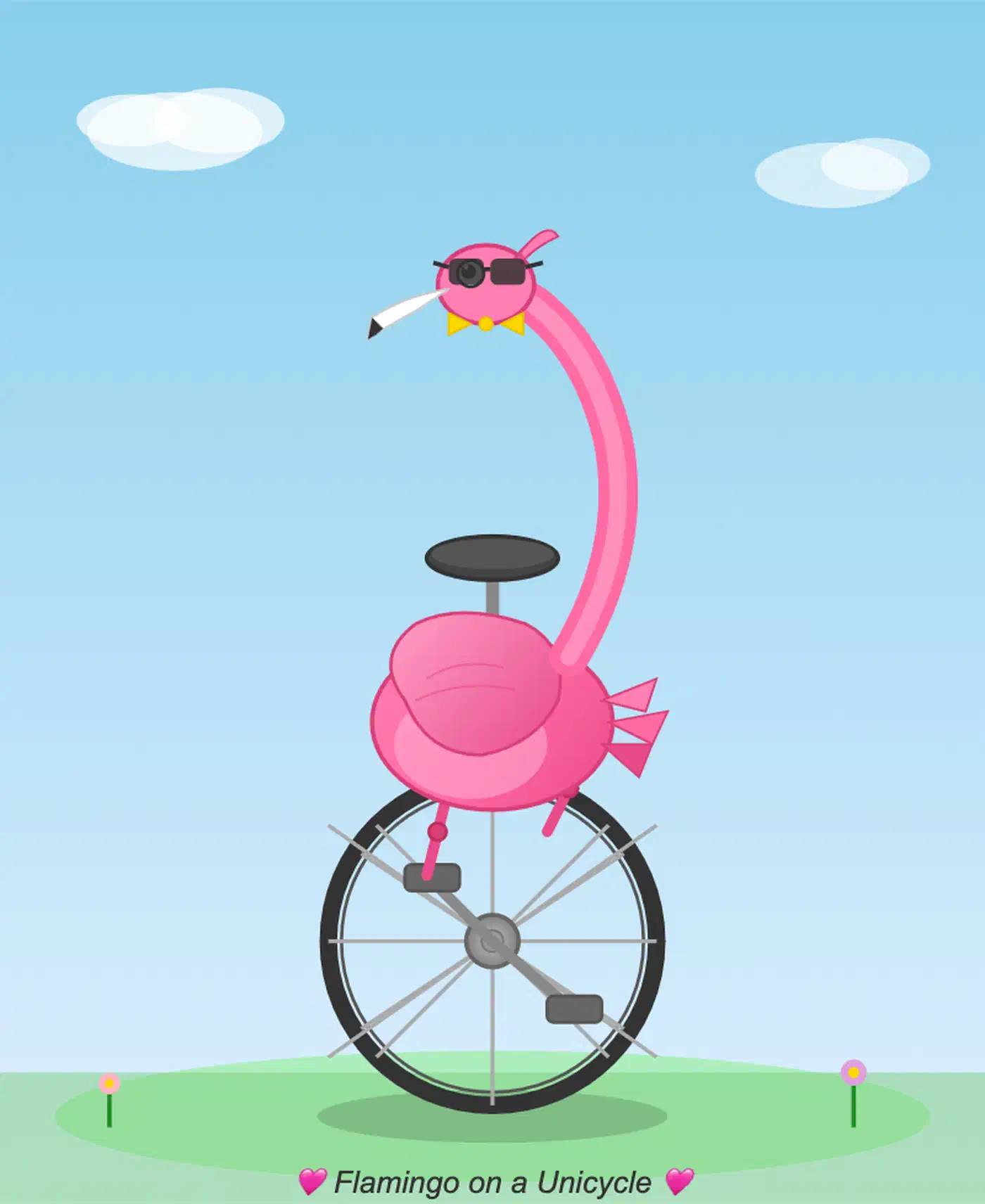
Willison’s own caveat is the one to internalize. He does not claim the quantized 21GB model is generally more useful than Opus 4.7, only that it nailed that particular task. That is the right level of calibration for any reader tempted to conclude a local model now replaces a frontier API.
Dense frontier models still likely lead on subtle reasoning over adversarial prompts, long-horizon tool chains where a single bad step cascades, and tasks where per-token quality matters more than throughput or cost. Safety behavior on Qwen3.6 is also less documented than on the major closed models, which matters for consumer-facing deployments. The Chinese-versus-English quality gap at long context has not been independently audited either, and some community users have flagged uneven behavior on multilingual edge cases.
A practical decision rubric looks like this. Reach for Qwen3.6-35B-A3B when you need local or private inference, repo-scale context, Apache-2.0 license cleanliness, or derivative-model rights. Keep paying for Claude or GPT when you need the absolute ceiling on one-shot reasoning quality, the strongest safety tuning available, or the most consistent behavior on adversarial long-horizon prompts. If you want a larger sparse model in the same class , MiniMax M2.7 scales the idea to 230B total parameters and lands close to Claude Opus on coding.
The 2026 takeaway is architectural rather than political. Three billion active parameters now matches or beats 30B dense parameters on the single workload (agentic coding) that the largest share of professional developers cares about. If that result generalizes to other narrow workloads over the next few releases, the compute budget for local AI gets rewritten again.