RAG vs. Long Context: Choosing the Best Approach for Your LLM

RAG and long context windows are not competing replacements. They are different tools built for different problems. If you are trying to choose between them, the short answer is: it depends on the size and nature of your data, your latency and cost constraints, and how much infrastructure complexity you are willing to maintain. The longer answer involves understanding what each approach actually does, where each one breaks down, and what teams running production LLM systems are doing in 2026 - which is usually some combination of both.
The Frozen LLM Problem
Every LLM has a training cutoff. After that date, the model knows nothing about what happened in the world, and it has never known anything about your private data - your internal documentation, your codebase, your customer records, your proprietary research. The model is frozen.
This creates a concrete challenge for anyone building applications on top of LLMs: how do you get the right information into the model at query time? The model cannot look things up on its own. It cannot read your files. It can only work with what you put into its context window.
This is the context injection problem, and there are two primary architectures for solving it. The first is Retrieval-Augmented Generation, or RAG - an engineering approach that selectively pulls relevant information from a large corpus and injects it into the prompt. The second is long context - an approach that simply loads as much of your data as possible into an increasingly large context window and lets the model sort it out.
Both approaches solve the same root problem. They differ in how they solve it, and each has situations where it wins.
How RAG Works
RAG is a pipeline, and understanding it at the component level matters because each step is a potential failure point.
The process starts with ingestion. Your documents - PDFs, markdown files, database records, whatever - are split into smaller chunks, typically a few hundred to a few thousand tokens each. Those chunks are passed through an embedding model, which converts the text into a high-dimensional vector. These vectors are stored in a vector database such as Qdrant , Weaviate , or pgvector .
At query time, the user’s question is embedded using the same model, and the vector database runs a similarity search to find the chunks whose vectors are closest to the query vector. The top-K matching chunks are then injected into the LLM’s context window as supporting context.
Modern RAG systems add two refinements worth knowing. Hybrid search combines dense vector search with BM25 keyword search. Dense search handles semantic similarity well; BM25 is better at exact term matching. Running both and merging the results improves recall, especially for queries involving specific names, IDs, or technical terms that embedding models sometimes mishandle.
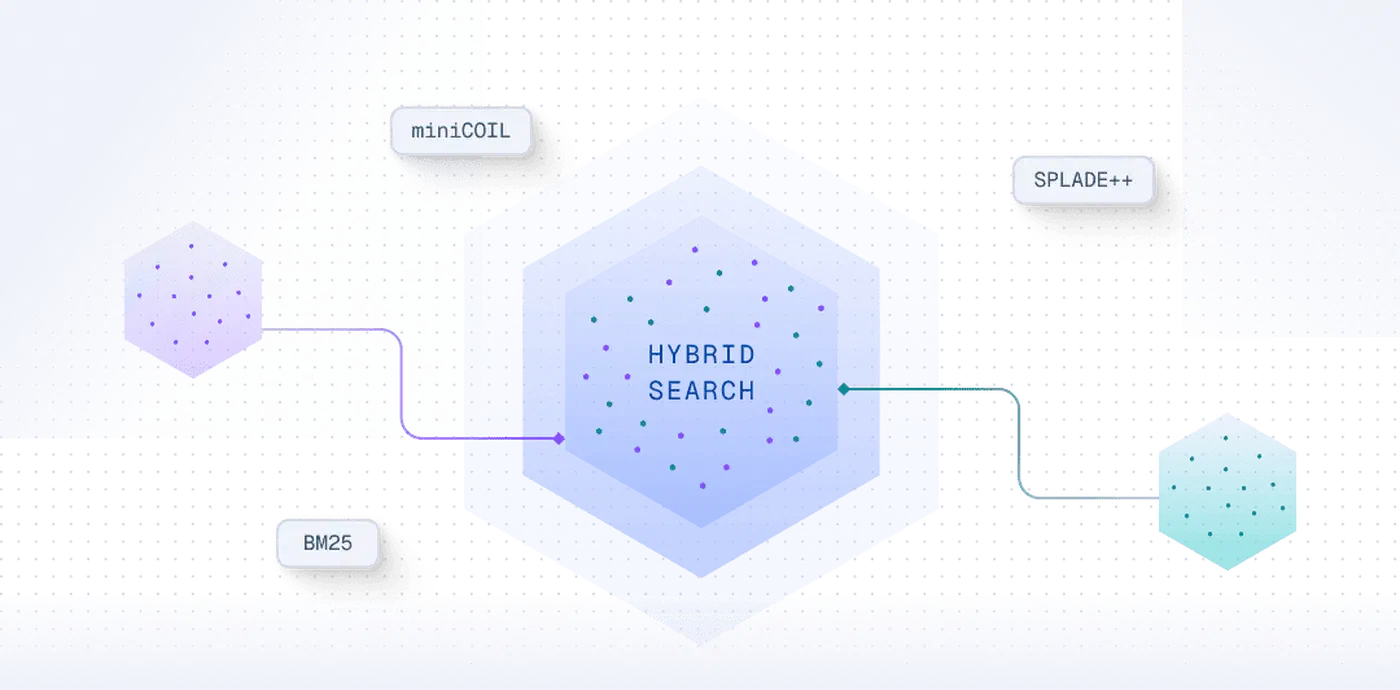
Reranking comes after the initial retrieval step. Once you have, say, 20 candidate chunks, a cross-encoder model re-scores each one against the query and keeps only the highest-scoring. Cross-encoders are slower than vector search but considerably more accurate at relevance judgment. If you want one improvement that pays off reliably in a RAG pipeline, reranking is it.
The critical thing to understand about RAG: the whole system is only as good as its retrieval step. If the right chunk is not retrieved, the LLM cannot produce the right answer. This failure is silent - the model will not say “I could not find the relevant section.” It will produce a plausible-sounding response based on whatever it did retrieve, which may be wrong. Retrieval failures are the primary source of RAG hallucinations .
Chunking Is More Consequential Than It Looks
One decision that trips up most RAG implementations is chunking strategy. The default approach - split every N tokens with some overlap - works well enough for uniform prose but breaks down on structured documents. A technical specification where the answer to a question appears in a table, a code block, or a numbered list will often produce misleading chunks when split naively by token count.
Better approaches include semantic chunking (splitting at paragraph or section boundaries rather than fixed token positions), document-aware chunking (treating each header-delimited section as a single chunk), and late chunking (embedding the full document first, then splitting at query time). The right strategy depends on your source material. If your RAG system is underperforming, the chunking strategy is usually worth investigating before anything else.
Context window size also affects chunking decisions. In 2024, a common chunk size was 512 tokens because context windows were small and you needed many chunks to fit under the limit. With 128K+ context windows now standard across most model APIs, you can use much larger chunks - 2,000 to 4,000 tokens per chunk - which reduces fragmentation and preserves more document structure. Larger chunks mean fewer retrieval results needed, and fewer retrieval results means less noise in the context.
The Long Context Revolution
In 2023, a 4,000-token context window was a tight constraint. By 2026, models like Gemini 1.5 Pro and Claude 3.5 support context windows of 1 million tokens or more. One million tokens is roughly 750,000 words - enough for the entire Lord of the Rings trilogy with space left over.
That scale difference opens a different architectural path: instead of retrieving a small slice of your data, you load the whole thing into context and let the model reason across all of it.
The no-infrastructure appeal is real. There is no chunking strategy to tune, no vector database to operate, no embedding model to keep synchronized with your documents, no reranker to calibrate. You prepare your data once, load it into the context window, and ask your question.
More concretely, long context eliminates retrieval lottery. In a RAG system, if the correct information lives in a chunk that scores poorly in the similarity search - because the query phrasing does not closely match the document phrasing - you lose. The answer is in your data, but your pipeline did not surface it. With long context, if the information is in the context window, the model has access to it.
Long context also enables a category of tasks that RAG handles poorly: holistic reasoning across an entire document set. Consider a question like “what requirements were present in version 1 of this specification but dropped in version 2?” Answering that correctly requires the model to hold both documents in mind simultaneously and compare them in detail. A RAG system might retrieve relevant sections from both versions, but it is unlikely to surface every relevant section, and even when it does, the model is reasoning from fragments. Load both spec versions into a long context window and the comparison becomes tractable.
Why RAG Still Matters
Long context has genuine limits.
Cost is the first practical one. Processing a million-token context window is not cheap. Every token must be processed by the attention mechanism on every request. If you have a 500-page technical manual and users are asking questions about it thousands of times per day, you are paying to process those 500 pages on every single query. RAG pays the embedding and indexing cost once, at ingestion time. At query time, you are processing a few thousand tokens of retrieved context. The cost difference at scale can be an order of magnitude or more.
Attention dilution is the second. Research on the “lost in the middle” problem has shown that transformer-based models do not attend equally to all positions in a long context. Information buried in the middle of a very long input tends to receive less attention than content near the start or end. For tasks that require finding a specific fact in a million-token context, models can miss it even when the information is technically present. This is improving with newer model generations, but it has not been solved.
Scale is the third and most binding constraint. Enterprise data does not fit in a context window. A company with years of documentation, customer interactions, code repositories, and research outputs is working with terabytes or petabytes of data. No context window will accommodate that, and none will in the near term. Vector databases are not a workaround for small context windows - they are the only viable architecture for querying large-scale knowledge stores that will keep growing.
There is also a latency consideration that matters in practice. A RAG query injecting 2,000 tokens of retrieved context into a model will get a response faster than a query that must first load 500,000 tokens into context. For interactive applications, that difference is noticeable.
Which One to Use
The choice is less about which approach is theoretically superior and more about what your situation actually requires.
Use long context when your dataset is bounded and fits within a context window - a specific contract, a single codebase, a known document set. Long context is also the right call when the task requires holistic reasoning across multiple files: gap analysis between document versions, contradiction detection across policy documents, cross-document summarization where completeness matters more than speed. And if you want to reach production quickly without building retrieval infrastructure, long context lets you validate a use case before committing to a pipeline.
Use RAG when you are querying a data set that is too large to fit in any context window - which covers most enterprise knowledge bases. Use it when cost and latency at scale are real constraints, when your corpus is noisy and most of it is irrelevant to any given query (loading 500 loosely related pages into context is worse than retrieving the three that are actually relevant), and when your data changes frequently enough that you need updates queryable immediately without re-ingesting full documents.
Use both when your dataset is large but answers tend to live in predictable, locatable sections. RAG finds the relevant 50,000 to 100,000 tokens; long context then reasons across that retrieved set with full attention and no chunking artifacts. This pattern is what the most capable production systems run today. Taking it further, agentic RAG gives the LLM itself control over when and what to retrieve, enabling multi-hop reasoning and adaptive search strategies that static pipelines cannot match.
The hybrid approach is worth more attention than it usually gets. RAG and long context are not competing at the same layer. RAG is a retrieval mechanism; long context is a reasoning mechanism. Together, RAG handles the “find it” step and long context handles the “reason across it” step. Each covers a weakness the other has.
If you are starting from scratch with a dataset that fits in a context window, start with long context. Get something working, validate the use case, then add RAG only when you hit real limits - the data grows beyond what fits in context, or the cost of full-context processing becomes a problem. Many use cases never reach that point.
If your data is already large or will grow without bound, start with RAG. Build the chunking and embedding pipeline carefully, add hybrid search and reranking early, and treat retrieval as the most critical component in the system - because it is.
The teams building the most capable LLM applications are not treating this as a binary choice. They pick each approach where it is strong, and combine them where neither one alone is sufficient.