Why AI is Killing the Internet: Model Collapse and the Knowledge Commons

The open web was built on a surprisingly fragile premise: that people would share what they know, for free, in public. For roughly two decades that premise held. Developers posted answers on Stack Overflow . Students debated ideas on Reddit. Journalists broke stories indexed by Google. The result was an extraordinary knowledge commons - a vast, searchable, collectively maintained record of human expertise. AI did not just consume that commons. It is in the process of destroying the conditions that made it possible.
This is not a conspiracy theory or a technophobe’s lament. It is a documented economic collapse playing out in real time, with measurable consequences for the quality of AI models themselves. Understanding what is happening - and why - matters whether you are a developer, a content creator, a researcher, or simply someone who uses the internet to learn things.
The Death of the Knowledge Commons
The numbers are concrete and they arrived fast. Stack Overflow, once the world’s largest coding knowledge base, saw question volume fall by roughly 78% between 2022 and 2025. The site that helped generations of developers debug code, understand frameworks, and share hard-won solutions went from a thriving community to a platform conducting mass layoffs inside three years. That is not a gradual decline - it is a cliff edge.
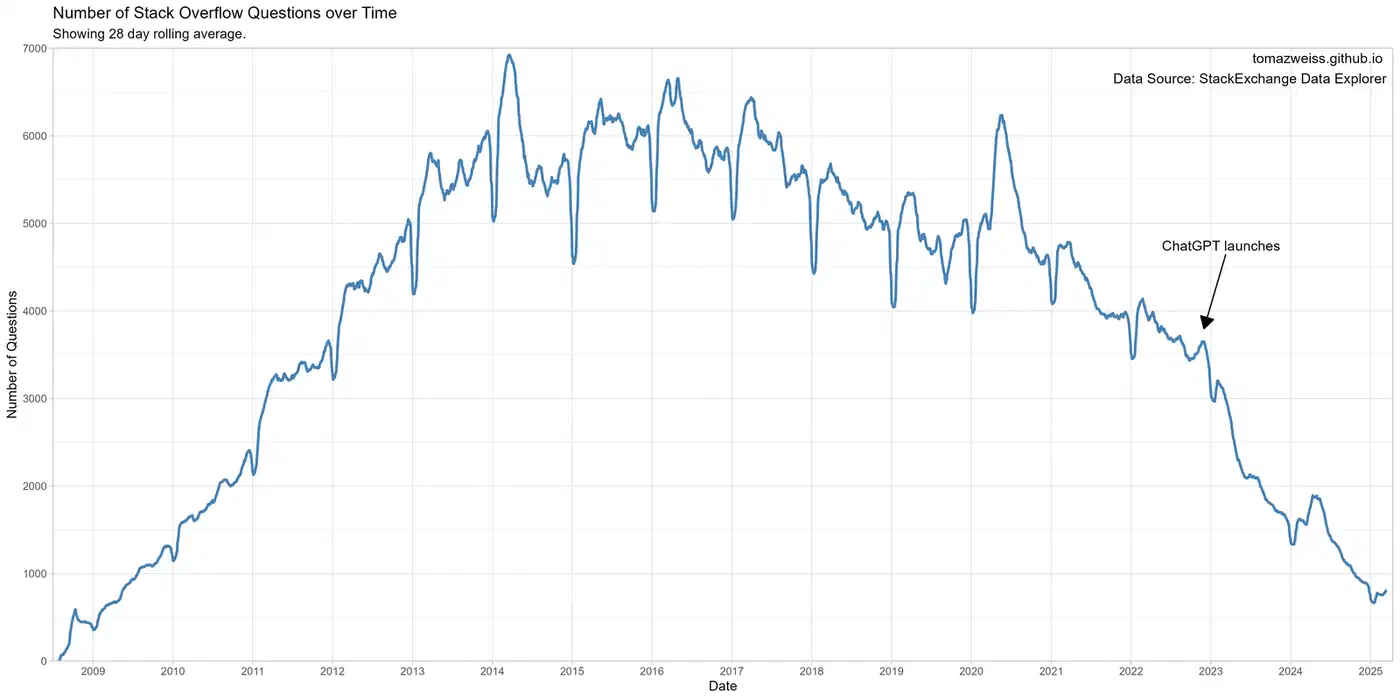
Stack Overflow is not an isolated case. Chegg , an education platform that built its business on student Q&A and tutoring services, watched its stock price collapse by roughly 99% over the same period. The business model - connect students with human expertise - became untenable the moment students could get instant answers from ChatGPT for free. Publishers across the web reported losing roughly one-third of their search traffic to AI-intercepted queries, where Google’s AI Overviews or similar features answer the question without the user ever visiting the source.
Even Sam Altman, CEO of OpenAI, acknowledged in 2024 that genuine human content on the internet is becoming harder to find, increasingly displaced by synthetic output. The “Dead Internet Theory” - once a niche online speculation that the web was already mostly bot-generated noise - has moved from fringe conspiracy to something researchers and journalists are now documenting with actual data.
The significance here goes beyond nostalgia for old websites. These platforms were not just useful services. They were the substrate that AI was trained on. Stack Overflow, Reddit, Wikipedia, and millions of personal blogs formed the corpus that made large language models capable in the first place. As those platforms hollow out, the conditions for producing the next generation of high-quality training data deteriorate with them.
The Mechanics of Destruction: Severing the Incentive Loop
The collapse follows a specific economic logic that is worth tracing carefully, because understanding it is the key to understanding why this is a structural problem rather than a temporary disruption.
Humans share knowledge publicly for reasons that are not purely altruistic. Stack Overflow contributors earned reputation scores that signaled professional competence. Bloggers monetized via ads and affiliate links, which required search traffic. Reddit moderators built communities that generated social capital. Wikipedia editors participated in a genuine collective project with clear cultural prestige. These incentives were not incidental - they were the engine.
AI training pipelines harvested roughly 15 years of that collaborative effort without returning value to the sources. The Common Crawl, the primary dataset underlying most large language models, scraped billions of web pages - the accumulated output of human expertise freely shared online. None of the platforms or individuals who produced that content received compensation, attribution, or even notification.
That extraction would be sustainable if AI had preserved the traffic that made those platforms financially viable. Instead, it intercepted it. When a developer searches for how to handle a specific Python exception and gets an AI-generated answer directly in the search results, Stack Overflow gets neither the page view nor the ad revenue. When a student asks ChatGPT to explain calculus, Chegg loses a subscriber. The platforms that generated the high-quality training data are starved of the revenue that allowed them to operate, moderate, and grow.
The incentive gap compounds this. If a developer knows their Stack Overflow answer will not be seen - because AI has displaced discovery - they have less reason to write a detailed, well-sourced response. Why spend 45 minutes crafting a thorough answer for reputation points on a platform that is declining? The result is a feedback loop: less traffic leads to less contribution, which leads to lower quality, which leads to further decline.
Model Collapse: The Science of Self-Consumption
Model collapse is what happens when this feedback loop reaches the training pipeline. In 2024, researchers at Oxford University published a paper in Nature demonstrating that AI models trained on AI-generated data degrade in measurable, statistically predictable ways. The degradation is not subtle or gradual - it compounds across generations.
Researchers at Rice University described the phenomenon with a term that captures the mechanism precisely: Model Autophagy Disorder , or MAD. The analogy is a photocopier copying a photocopy. The first copy is nearly indistinguishable from the original. The second is slightly worse. By the tenth generation, text becomes blurry and details are lost. With AI models, the “blurring” manifests as outputs that become progressively more generic, more repetitive, and less capable of engaging with unusual or edge-case problems.
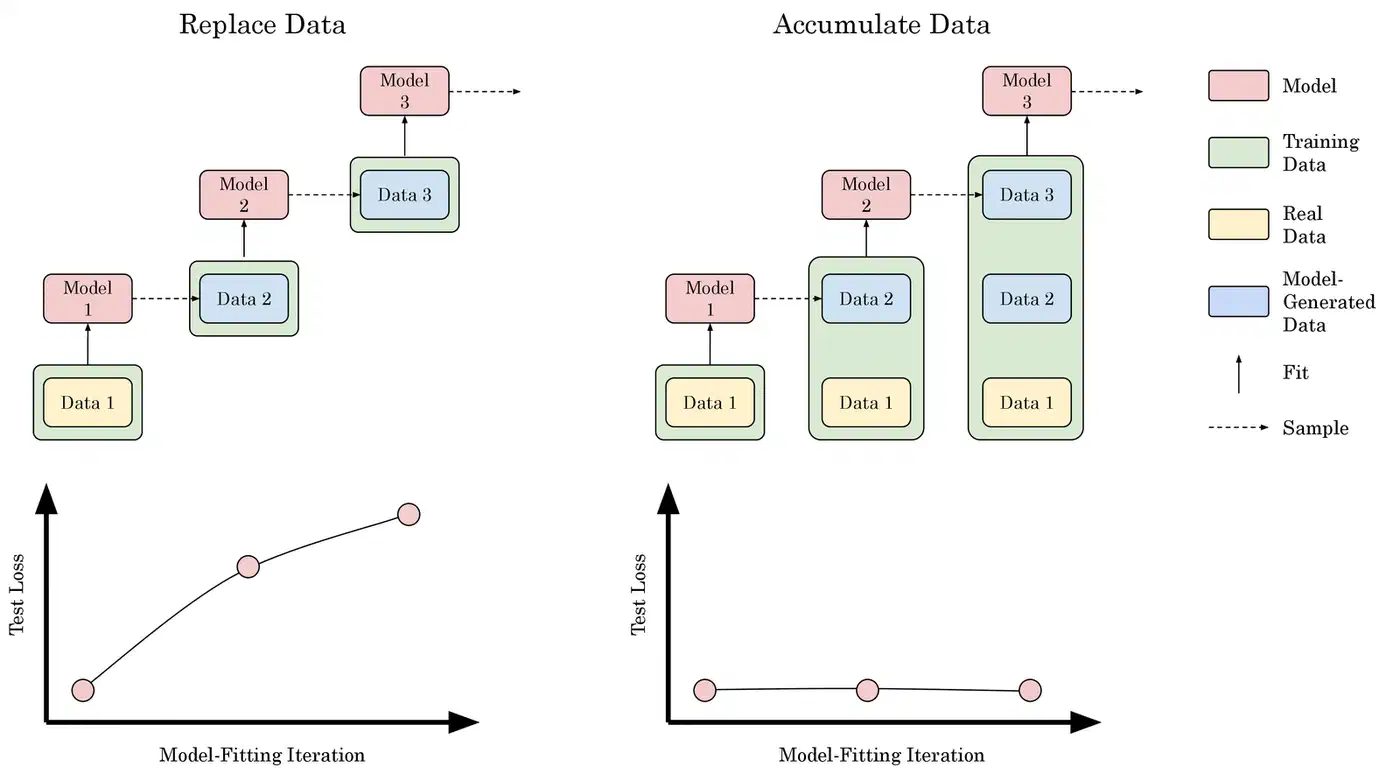
What gets lost first tells the real story. Statistical distributions of human-generated text have long tails - unusual phrasings, niche expertise, creative leaps, unconventional approaches to problems. A creative solution to a hard engineering problem is not in the center of the distribution; it is in the tail. When models train on synthetic data, those tails get truncated. Each generation of models gets better at producing confident, fluent, plausible-sounding output in the center of the distribution - and worse at the kinds of novel, specific, edge-case reasoning that actually advances knowledge.
The practical consequence is an AI ecosystem that becomes progressively more competent at sounding authoritative while eroding in its capacity for genuinely new insight. The outputs feel polished. The reasoning sounds coherent. But the ability to synthesize novel connections from genuinely diverse human experience shrinks with each training cycle. Production teams are already living with these symptoms — and fixing LLM hallucinations in deployed systems is increasingly a matter of architectural defense, not just better prompts.
The Data Wall: Exhausting the Internet
Model collapse is a quality problem. There is also a quantity problem.
Epoch AI , a research organization that tracks AI compute and data trends, has estimated that high-quality human-generated text data suitable for training large language models could be effectively exhausted by 2028. This is not a claim that the internet runs out of words - there will always be more text. It is a claim that the corpus of carefully written, factually grounded, genuinely informative human text is finite, and AI training is consuming it at a rate that exceeds human production capacity.
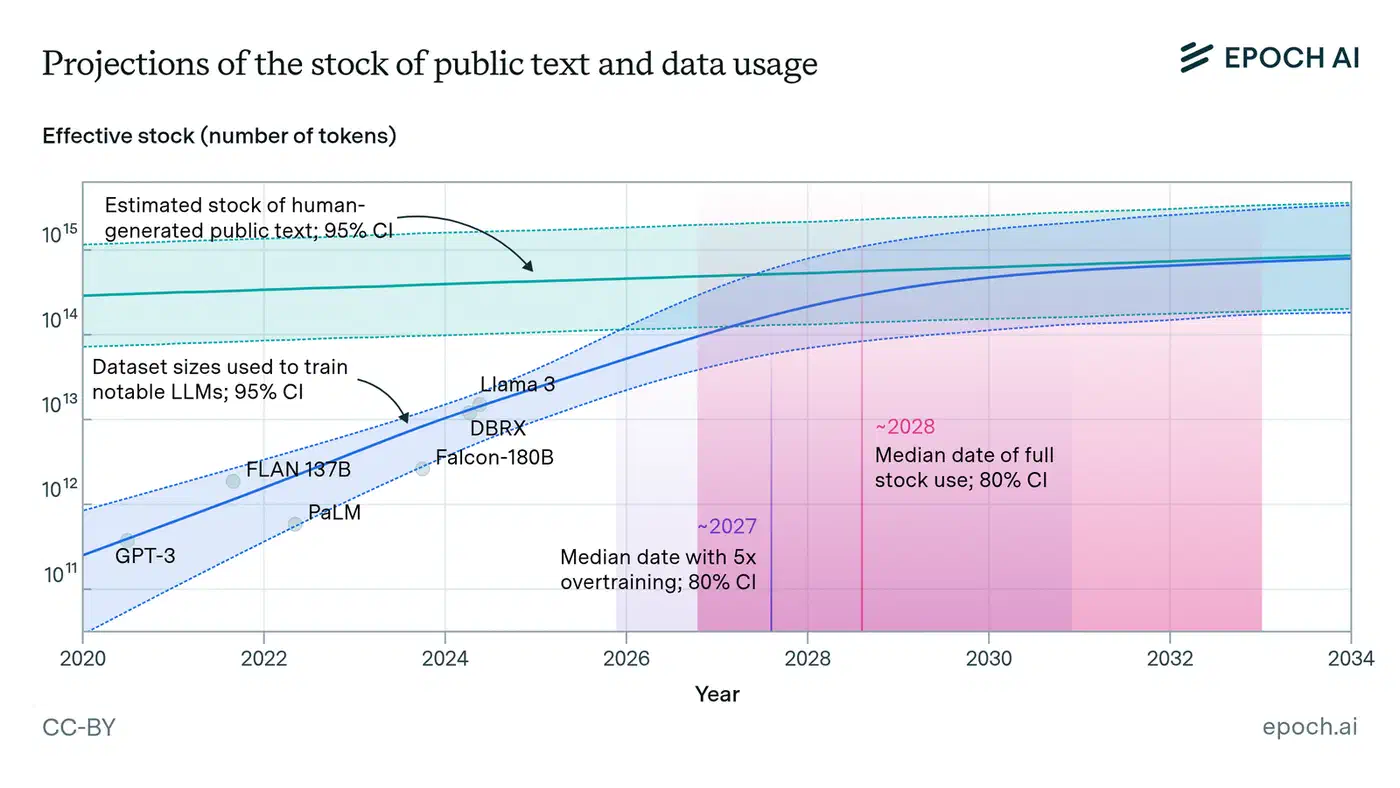
The contamination problem compounds this. The exponential growth of synthetic content makes it increasingly difficult to filter “clean” human-generated data for future training runs. Current AI-text detection tools work reasonably well against older, less sophisticated models. As models improve, their outputs become indistinguishable from human writing under automated analysis. Future training datasets will contain significant proportions of synthetic text that cannot be reliably identified or removed.
This creates a situation where the data wall is not just a ceiling but an accelerating problem. The more AI content floods the web, the harder it becomes to find clean human signal, the more future models must rely on synthetic data, and the faster model collapse proceeds. It is a compounding dynamic, not a linear one.
Epistemic Stagnation: A Future Without New Knowledge
The deepest concern in this picture is not about AI model quality. It is about the future of human knowledge generation.
When a developer encounters an unusual bug - one caused by a rare interaction between library versions, operating system behavior, and hardware configuration - and solves it using ChatGPT in a private conversation, that solution ceases to exist for anyone else. The fix is applied. The problem goes away. The knowledge is never posted, never indexed, never available to the next developer who hits the same edge case. Under the old model, that developer would have posted a Stack Overflow question, received community input, and added a searchable record to the commons. The knowledge would persist and be discoverable.
This is the broken knowledge loop. AI answers feel like a more efficient way to solve problems. In the immediate term, for the individual user, they often are. But each private AI interaction that replaces a public forum post represents knowledge that fails to enter the collective record. Over thousands of such interactions daily, across millions of developers, the web’s accumulation of novel solutions stagnates. The security audits of AI-generated applications have begun to quantify what that quality gap looks like in practice: thousands of vulnerabilities in code that passed superficial review because the model sounded confident.
There is also a deeper issue about recombination versus generation. Current AI systems can recombine existing knowledge with impressive fluency - finding patterns across text and synthesizing coherent outputs. Discovering facts about the world that are not implicit in their training data is something they cannot do. When the training data stops growing with fresh human discovery, the AI’s recombinative capability operates on an increasingly fixed corpus. AI systems trained on AI outputs that were themselves trained on earlier AI outputs, all tracing back to a human corpus that is no longer being meaningfully updated. The model keeps generating confident answers; the knowledge base those answers draw from calcifies in place.
The web starts to feel like a hall of mirrors - authoritative-sounding responses pointing back to other authoritative-sounding responses, the whole structure resting on a foundation that stopped being updated years ago.
Cautious Optimism and the Road Forward
None of this means the situation is fixed. There are genuine technical responses worth paying attention to, even if none of them fully resolve the problem.
Self-play and reinforcement learning from internal reasoning is the most credible near-term mitigation. Models like DeepSeek R1 demonstrated that a model can generate its own synthetic training signal by reasoning through problems step by step and verifying outputs against ground truth in domains where that verification is possible - mathematics, coding, formal logic. If this approach scales, it could partially decouple model quality from the human text corpus, at least in those verifiable domains. The limitation is real: verification requires objective ground truth, and for most of what humans write about - history, ethics, political analysis, creative work - no such ground truth exists.
Some historical perspective is worth holding, though it should not be used to wave away the current problem. The internet did displace encyclopedias, but it also produced Wikipedia and GitHub. The printing press was genuinely disruptive to the scribal profession, and the result was mass literacy. Technologies that destroy old knowledge formats sometimes create new ones that were not previously imaginable. Whether AI follows that pattern or breaks it is an open question, and the people who say they know the answer with confidence are guessing.
Stack Overflow and similar platforms are already trying to adapt, integrating AI tools into their workflows rather than pretending they can compete with free AI chat on equal terms. Whether that works depends on whether they can rebuild the incentive structures - reputation, community, discovery - that made contribution worthwhile when search traffic was still flowing.
The timing issue is harder to wave away. The industrial revolution produced severe disruption, but it played out over generations. Communities had time to adapt, migrate, retrain. The shift currently underway in how knowledge is produced and consumed is measured in quarters, not decades. The knowledge commons that took 20 years to assemble could erode significantly within five. That is not a comfortable timeline for adaptation, for the platforms trying to pivot, or for the AI models that will need fresh human-generated data to avoid the compounding effects of self-consumption.
What is being lost matters beyond the platforms themselves. The value of publicly shared human expertise was never just about having answers available - it was about having a continuously updated, collectively maintained record of how humans are actually solving problems right now. When that record stops being updated, AI models trained on it will gradually produce answers to a world that no longer exists quite the way they describe it.