Open Source Vector Databases: Qdrant vs Milvus vs Weaviate

Five open source vector databases are worth a shortlist in 2026. Qdrant is Rust-based and wins on single-node latency and filtered ANN. Milvus 2.5 is the billion-scale pick with disk and GPU indexes. Weaviate bundles hybrid search and generative modules. Chroma is the simplest Python option for prototypes and agent memory. pgvector 0.8 is the smart bet when Postgres already runs your data. LanceDB earns a mention for multimodal, read-heavy work on S3. The right pick depends on where your data sits, how big the index gets, and whether you want strict p95 latency or built-in RAG glue.
Why Vector Databases Still Matter in the 2026 RAG Stack
The vector database market looked crowded in 2023 and looks worse now. It is fair to ask if a dedicated engine still earns its keep. pgvector ate the low end. DuckDB-VSS and LanceDB swept up analytical use cases. Still, the top three dedicated engines keep pulling ahead at the high end. Retrieval-Augmented Generation pipelines running on Llama 4, Qwen3.6, and Claude Opus 4.7 now serve tens of millions of chunks. They apply per-tenant filters and need sub-100 ms p95 retrieval. That is where the dedicated engines pay off.
The ground has shifted toward hybrid retrieval. Pure dense ANN has lost out to a mix of dense vectors, sparse signals like SPLADE and BM25, and late-interaction models like ColBERT and ColPali. Every serious vector DB in 2026 ships hybrid retrieval with RRF or DBSF fusion baked in. None of them treat it as an Elasticsearch problem anymore. Binary quantization is now mainstream. Matryoshka embeddings are on every roadmap. Multi-vector storage is table stakes for visual document search.
Self-hosting math has improved too. With local embedding models on an RTX 5090 or H200, the full retrieval stack fits on one well-spec’d box. The cost of a managed vector DB is hard to justify when you already run Kubernetes and object storage.
Qdrant: The Rust-Based Performance Leader
Qdrant is the default pick for teams that need fast, filtered search at scale. It is written in Rust and ships as a single binary. Its HNSW index applies payload filters during the graph walk, not after, so recall stays intact even on tight queries.
Quantization is the most useful knob. Pick scalar (int8), product, or binary per collection. Binary turns 32-bit floats into single bits, which cuts memory by about 32x and speeds queries up to 40x. On OpenAI text-embedding-ada-002 vectors, Qdrant reports recall@100 of 0.98 with 4x oversampling. Cohere embed-english-v2.0 hits 0.98 recall@50 with 2x oversampling. In practice, 100K OpenAI vectors fit in about 128 MB of RAM.
Sparse vectors and hybrid search are native. RRF and DBSF fusion ship in the box, so you don’t need an extra BM25 engine for keyword-plus-semantic results. Multi-vector support handles ColBERT-style late interaction and ColPali visual document retrieval . Distributed mode adds sharding, Raft consensus, replication, and snapshot backups. Official clients exist for Python, Rust, Go, JavaScript/TypeScript, Java, and .NET.
Where Qdrant wins: production RAG with strict p95 SLOs, heavy metadata filters, and sub-100 ms retrieval at 50M vectors on one node. Recent VectorDBBench runs put Qdrant on top for recall at about 98.5 percent on the common datasets. Milvus and Weaviate trail close behind.
A minimal Qdrant quickstart:
docker run -p 6333:6333 -p 6334:6334 qdrant/qdrantfrom qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
client = QdrantClient(url="http://localhost:6333")
client.recreate_collection(
"docs",
vectors_config=VectorParams(size=1024, distance=Distance.COSINE),
)
client.upsert(
"docs",
points=[PointStruct(id=1, vector=[0.1] * 1024, payload={"tenant": "acme"})],
)
hits = client.query_points(
"docs",
query=[0.1] * 1024,
query_filter={"must": [{"key": "tenant", "match": {"value": "acme"}}]},
limit=5,
)
Milvus 2.5: Distributed Scale for Billion-Vector Workloads
Milvus is the right pick when one machine stops being enough. The 2.5 release hardened the cloud-native setup: compute and storage split apart, with etcd for metadata, MinIO or S3 for objects, and Pulsar or Kafka for the write-ahead log. It is heavier to run than Qdrant. It also scales much further.
The GPU CAGRA index, built on NVIDIA cuVS, is the headline feature. On H100 or H200 hardware, index builds run 10 to 50 times faster than CPU HNSW. Queries against billions of vectors stay in the tens of milliseconds. CAGRA memory overhead is about 1.8 times the raw vector data. Milvus 2.6.1 added a hybrid mode where the GPU builds the graph and CPUs run queries. That keeps costs down without hurting quality.
Milvus offers the widest index menu of any engine:
| Index | Strengths | Trade-offs |
|---|---|---|
| HNSW | Best latency/recall balance for in-memory | RAM-bound |
| IVF_FLAT | High recall, fast build | Slower queries than HNSW |
| IVF_PQ | Large memory savings | Recall drops vs. IVF_FLAT |
| SCANN | Strong QPS on CPU | Newer, fewer production war stories |
| DiskANN | Billions of vectors on NVMe with limited RAM | Slower than pure in-memory indexes |
| GPU_CAGRA | Fastest builds and queries on NVIDIA hardware | Requires GPUs, higher memory use |
Partition keys give you cheap multi-tenancy and time-based data lifecycle. Hybrid search blends sparse and dense vectors with BM25 and optional reranking. Milvus Lite, a single-file embedded mode around 10 MB, now goes head-to-head with Chroma and LanceDB for laptops and CI.
Where it wins: more than 100 million vectors, multi-region setups, GPU index rebuilds, and teams that already know Kubernetes. The gotchas are real. You get dependency sprawl, a steeper learning curve on the CRD-based deploy, and a much heavier footprint than a single-binary engine.

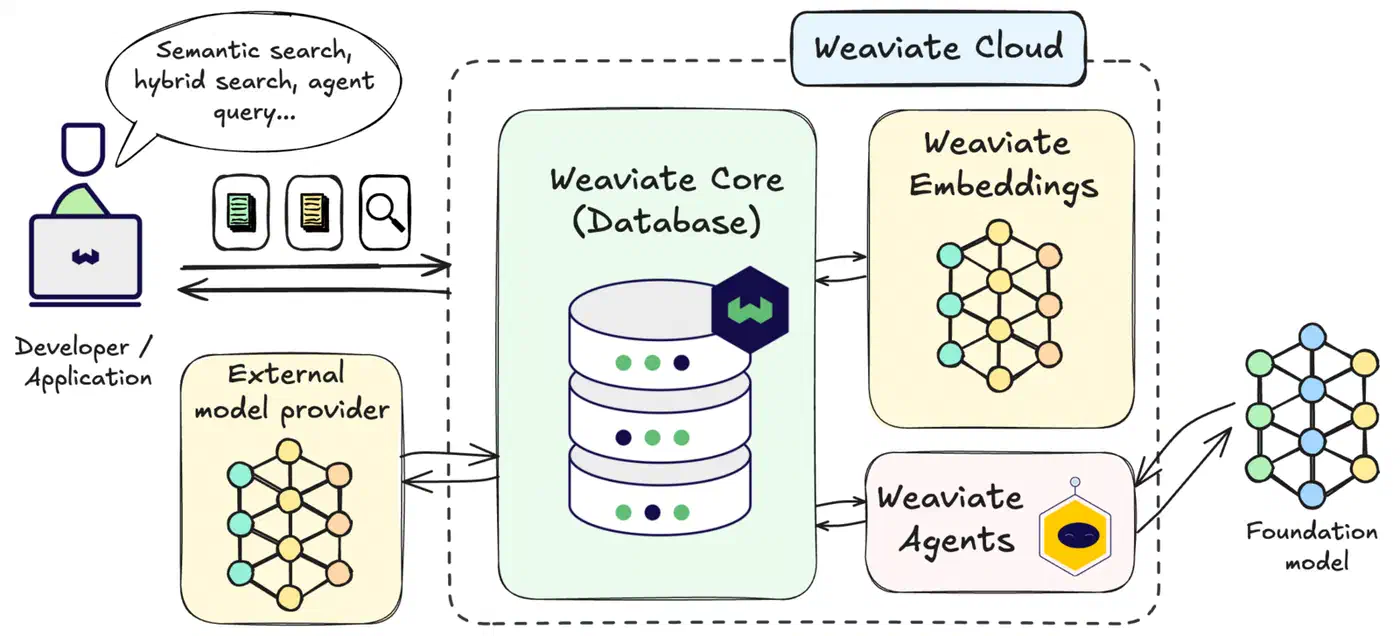
Weaviate: Hybrid Search and Generative Modules Built In
Weaviate’s pitch: ship the whole RAG loop in one process. Vectorizer modules embed your data on ingest and query. Generative modules call an LLM and return an answer. Hybrid search with BM25F handles retrieval. For teams who’d rather skip a framework like LangChain or LlamaIndex, Weaviate is the shortest path from documents to answers.
The server is written in Go and exposes both GraphQL and gRPC APIs. Collection schemas are JSON-like and enforced. Vectorizer modules cover the usual providers: text2vec-ollama, text2vec-openai, text2vec-cohere, and multi2vec-clip for multimodal. Generative modules include generative-ollama, generative-anthropic, and generative-openai. One query can fetch context and produce an answer.
Other differentiators worth naming:
- Native multi-tenancy with per-tenant isolation and async replication.
- Named vectors, where one object can hold multiple embeddings (for example title, body, and image) queried independently.
- Hybrid search with BM25F plus vector fusion, configurable per query.
- Embedded mode for Python and JavaScript when you want the features without a server.
Where Weaviate wins: teams who want RAG end-to-end without a framework, apps that need hybrid plus generative in one hop, and multi-tenant SaaS with strict data isolation. The watch-out is lock-in. The module system is handy, but swapping embedding providers is more work than in Qdrant or Milvus. Committing to a generative module also ties answer formatting to Weaviate-specific config. See how a model-driven fetch strategy shapes your vector store choice.
Chroma, pgvector, and LanceDB: The Lightweight Contenders
Not every project needs a distributed cluster. Three engines keep winning on simplicity.
Chroma 1.5 is Python-first. It is happy running in-process for notebooks, agent memory, and prototypes. When you outgrow that, switch to a client/server setup. The 2025 Rust core rewrite killed the GIL bottleneck and gave roughly 4x write and query throughput. Regex search, BM25, and SPLADE sparse vectors are now first-class. The OSS core stays Apache 2.0 even though Chroma Cloud is now generally available, so self-hosting is not a second-class path.
pgvector 0.8 is the right answer when you already run Postgres 13 or newer. HNSW is supported. Iterative index scans in 0.8 fixed the old “filter kills recall” problem by scanning more of the index when a WHERE clause is selective. Binary quantization works through expression indexing and handles vectors up to 64,000 dimensions. For large tables, pair pgvector with pgvectorscale from Timescale. That adds StreamingDiskANN for cheap disk-based ANN. The pain point sits around 10 to 20 million vectors on a well-tuned Postgres 17 box.
LanceDB is the odd one out: columnar, embedded, and serverless-friendly. Vectors live in the Lance file format on S3 or R2. It shines on read-heavy batch and analytics workloads and on multimodal data. The 2026 roadmap added Lance-native SQL through DuckDB, multi-bucket storage, and 1.5M IOPS benchmarks. If your workload looks more like a data lake than a key-value store, LanceDB is worth a serious look.
A feature matrix makes the trade-offs concrete:
| Feature | Qdrant | Milvus 2.5 | Weaviate | Chroma | pgvector 0.8 | LanceDB |
|---|---|---|---|---|---|---|
| Hybrid search | Native | Native | BM25F + vec | BM25 + SPLADE | Via FTS | Secondary idx |
| Binary quantization | Yes | Yes | Yes (1.25+) | Limited | Via expr idx | Planned |
| Multi-tenancy | Payload + API | Partition keys | Native tenants | Collections | Schemas | Dataset-level |
| GPU acceleration | Experimental | CAGRA | No | No | No | No |
| Sparse vectors | Native | Native | Native | SPLADE | Via extension | Via pyarrow |
| Multi-vector/ColBERT | Yes | Yes | Named vectors | Limited | No | Limited |
| Embedded mode | Local binary | Milvus Lite | Python/JS | Python core | N/A | Native |
| Recommended ceiling | 50M single node | 10B+ clustered | 100M+ | 10M | 20M | 100M+ (disk) |
Short version of the decision:
- Already on Postgres? Use pgvector, add pgvectorscale if you outgrow it.
- Need under 10M vectors in a notebook or small app? Chroma or Milvus Lite.
- Read-heavy, S3-native, multimodal? LanceDB.
- Need billions plus GPU acceleration? Milvus 2.5.
- Need fast filtered ANN under strict latency SLOs? Qdrant.
- Want batteries-included RAG without a framework? Weaviate.
Benchmarks, Deployment Patterns, and Cost
Benchmarks on VectorDBBench and ANN-Benchmarks are a starting point, not gospel. Recent numbers on LAION-100M, Cohere-1M, and MS MARCO put Qdrant at about 98.5 percent recall, Zilliz/Milvus at 97.9 percent, and Weaviate at 97.2 percent. QPS swings wider by setup. At 50 million vectors on similar hardware, Qdrant holds about 41 QPS at 99 percent recall. Redis is worth a mention since it now ships a capable vector module. It has posted higher raw QPS than all three at like recall in the latest Redis-sponsored runs. That tells you more about hardware and tuning than about a true winner.
Memory math beats headline QPS. For 10 million 1024-dimension float32 vectors:
- float32 raw: about 40 GB
- int8 scalar quantization: about 10 GB with roughly 99 percent recall preserved
- binary quantization: about 1.25 GB with 95 to 98 percent recall given reasonable oversampling
That is the gap between a 64 GB box and a 16 GB box. It is usually the deciding factor in self-hosted cost.
For deploy, Qdrant and Weaviate both ship official Helm charts and simple docker-compose setups. Milvus needs etcd, MinIO or S3, and Pulsar or Kafka even for a small cluster. That is why Milvus Lite exists. All three expose Prometheus metrics and OpenTelemetry hooks out of the box. The metrics worth alerting on are p95 and p99 query latency, index build time, WAL or write buffer backlog, and replica health.
Backup stories differ. Qdrant does snapshot backups you can sync to S3. Milvus ships native S3 snapshots. Weaviate has a backup module with S3, GCS, and Azure targets. pgvector rides on Postgres PITR and logical replication. For a 20M-vector workload, a 16-core 64 GB VM handles Qdrant or Weaviate. Milvus wants at least three small nodes even on the low end. Managed tiers (Qdrant Cloud, Zilliz Cloud, Weaviate Cloud Services) stay competitive at 10M to 100M vectors. The math tips back toward self-hosting near 1B vectors, or when compliance rules out cloud providers.
Choosing a Vector Database for Your 2026 RAG Stack
Match the tool to the real constraint. A laptop prototype needs Chroma or Milvus Lite, nothing more. A Postgres shop that wants vector search on an existing table should reach for pgvector 0.8 and pgvectorscale before adding another system. Production RAG with tight latency SLOs lands on Qdrant. Billion-scale, GPU-accelerated, or multi-region work points to Milvus. End-to-end RAG without a framework favors Weaviate. Read-heavy analytics or multimodal work on object storage finds a home in LanceDB.
One closing warning. The costliest migration is rarely the embeddings or index settings. Both port between engines with a bit of code. The pain is the generative module. If you bake a year of prompt work into Weaviate’s generative-anthropic module or any vendor-specific reranker config, you lock in app logic as well as storage. Keep generation in your app layer when you can. Let the vector database do what it is good at: storing and fetching vectors fast.
Reference links: