Defensive Coding in Rust: Error Handling Patterns That Scale

Rust’s error handling ecosystem in 2026 centers on four patterns: Result<T, E> with custom enums for libraries, thiserror
for ergonomic enum derivation, anyhow
for application-level error propagation, and miette
or color-eyre
for human-friendly diagnostic reports. The right choice depends on whether you are writing a library (where callers need to match on specific error variants) or an application (where you need to propagate errors with context and print them readably). Most non-trivial Rust projects use both thiserror in their library crates and anyhow in their binary crates.
This split is not accidental. Library authors must give downstream consumers structured types to match on. Application developers want to collect errors from every dependency, attach context as failures propagate up, and print a readable report at the top level. The crates in Rust’s error handling ecosystem are designed to complement each other rather than compete, and knowing where each one fits saves hours of rework when a project grows from a weekend prototype into something that runs in production.
Result, Option, and the ? Operator
Before reaching for any crate, you need to understand the built-in primitives that every Rust error handling approach builds on.
Result<T, E> is an enum with two variants: Ok(T) and Err(E). Unlike exceptions in Python or Java, errors in Rust are values that must be explicitly handled. The compiler refuses to let you ignore a Result - if you call a function that returns one and do nothing with it, you get a warning. Errors are not hidden control flow in Rust - they are data, and the compiler holds you to that.
Option<T> represents the absence of a value (None) rather than an error condition. Converting between them is straightforward: .ok_or(err) turns an Option into a Result, and .ok() goes the other direction. The distinction matters because None communicates “nothing here” while Err communicates “something went wrong.”
The ? operator handles most error propagation in practice. When you write:
let data = fs::read_to_string("config.toml")?;the ? operator checks the Result. If it is Ok, it unwraps the value and assigns it to data. If it is Err, it returns that error from the enclosing function immediately. The operator also performs automatic From trait conversion, so if the function’s return type expects a different error type, Rust will convert it as long as a From implementation exists.
unwrap() and expect("msg") exist as escape hatches. They extract the value from Ok or Some, but they panic on Err or None. Reserve these for cases where the invariant is truly unreachable - a regex pattern that is known at compile time to be valid, for example. In production code, ? is almost always the right tool.
map_err transforms the error type inline without unwrapping:
file.read_to_string(&mut buf)
.map_err(|e| ConfigError::IoError(e))?;This converts a std::io::Error into your domain-specific error type before propagation.
Pattern matching with match gives you exhaustive handling. The compiler ensures you address both Ok and Err, and if you later add a new error variant to an enum, every unhandled match site breaks at compile time. This is one of Rust’s strongest guarantees
: the type system forces you to confront new failure modes rather than silently ignoring them.
Custom Error Enums: The Library Pattern
Libraries must expose structured, matchable error types so callers can decide how to handle each failure case. The standard approach is defining an error enum with one variant per failure mode:
#[non_exhaustive]
pub enum DatabaseError {
ConnectionFailed(String),
QueryTimeout {
query: String,
timeout_ms: u64,
},
InvalidSchema(SchemaError),
AuthenticationDenied,
}Each variant represents a distinct category of failure. Callers can pattern match on these variants to take specific recovery actions - retry on ConnectionFailed, show a login prompt on AuthenticationDenied, abort on InvalidSchema.
To integrate with Rust’s error trait ecosystem, you need two trait implementations. std::fmt::Display provides human-readable messages for each variant. std::error::Error connects your type to the standard error trait, enabling .source() chaining so logging frameworks and error reporters can traverse the full chain of causes.
The #[non_exhaustive] attribute on the enum is a forward-compatibility measure. Without it, adding a new variant in a future release is a breaking change because downstream match statements become incomplete. With #[non_exhaustive], callers are forced to include a wildcard _ => arm, making new variants additive rather than breaking.
For automatic error conversion with the ? operator, implement From<SourceError> for your error type:
impl From<std::io::Error> for DatabaseError {
fn from(e: std::io::Error) -> Self {
DatabaseError::ConnectionFailed(e.to_string())
}
}Preserving the source error chain is important for debugging compiled programs
. Store the original error inside your variant (either as a field or through Error::source()) so that when something goes wrong three layers deep, the full chain is available for inspection.
One pattern to avoid in library APIs: using Box<dyn Error> as your public error type. It erases all type information and prevents callers from matching on specific variants. Box<dyn Error> has its place in internal plumbing or application code where you just need to propagate errors, but it should not appear in a library’s public interface.
thiserror: Derive Macros That Eliminate Boilerplate
Writing Display and Error implementations by hand is tedious, especially as your error enum grows. thiserror
(currently at v2.0.18) eliminates this boilerplate with derive macros while keeping your error types fully structured and matchable.
The #[derive(thiserror::Error)] macro generates Display, Error, and From implementations from attributes on your enum variants:
#[derive(Debug, thiserror::Error)]
pub enum AppError {
#[error("database error")]
Db(#[from] sqlx::Error),
#[error("config file {path} not found")]
ConfigMissing {
path: String,
#[source]
cause: std::io::Error,
},
#[error("invalid input: {0}")]
Validation(String),
}The #[error("...")] attribute on each variant generates the Display implementation. You can interpolate named fields directly into the format string. The #[error(transparent)] attribute delegates display entirely to the wrapped error.
#[from] on a field generates a From implementation automatically. In the example above, Db(#[from] sqlx::Error) means that ? will convert any sqlx::Error into AppError::Db without you writing any conversion code.
#[source] is different from #[from]. It marks a field as the error’s source for .source() chain traversal but does not generate a From impl. Use #[source] when you want to preserve the error chain but need manual control over how errors are converted - for instance, when you want to add extra fields alongside the source error.
thiserror has zero runtime overhead. It is a proc-macro crate with no dependencies beyond proc-macro2, syn, and quote. It is the standard choice for library error types in the Rust ecosystem, used by tokio, reqwest, serde, and hundreds of other major crates.
thiserror vs snafu
snafu is the main alternative to thiserror for structured error types. Where thiserror keeps things minimal (typically 2 lines per variant), snafu is more opinionated and feature-rich - about 5 lines per variant when using source errors and backtraces. snafu generates context selector types that provide a builder-like pattern for attaching context when errors are created. For most library crates, thiserror’s lighter footprint is the better fit. snafu becomes more attractive in large, complex applications where you want the error type itself to carry richer context about what went wrong.
anyhow: Ergonomic Error Handling for Applications
Application code has different priorities. You care about reporting errors to users and logs, not about downstream callers matching on variants. anyhow (currently at v1.0.100) provides a single error type with rich context chaining that fits this use case perfectly.
anyhow::Result<T> is an alias for Result<T, anyhow::Error>. anyhow::Error wraps any type that implements std::error::Error, eliminating the need to define a top-level error enum for your binary. Any library error that passes through your application code just works with ?.
The most useful part is context chaining. The .context() and .with_context() methods (from the Context trait) attach human-readable descriptions to errors as they propagate:
let config = fs::read_to_string(&config_path)
.with_context(|| format!("loading config from {}", config_path.display()))?;
let parsed: Config = toml::from_str(&config)
.context("parsing config file")?;When this error reaches main(), printing it with {:?} (Debug format) shows the full chain:
Error: parsing config file
Caused by:
0: expected `=`, found newline at line 3 column 1Each .context() call adds a layer to the chain, so you get a complete trace of what was happening at each level when the failure occurred.
anyhow::bail! creates and returns an error in one expression: bail!("port {} already in use", port). anyhow::ensure! is the error-handling equivalent of assert!: ensure!(count > 0, "count must be positive, got {}", count). Both are convenience macros that reduce boilerplate in validation logic.
For the rare cases where you need to recover a specific error type, anyhow::Error supports downcasting:
if let Some(io_err) = err.downcast_ref::<std::io::Error>() {
// handle I/O error specifically
}This should be uncommon in application code. If you find yourself downcasting frequently, you probably want structured error types with thiserror instead.
The recommended pattern for non-trivial Rust projects
: use thiserror in your library crates (where callers need structured, matchable types) and anyhow in your main.rs or binary crate (where you just need to propagate and display errors). The two crates are designed to work together.
Beyond the Basics: color-eyre, miette, and Error Reporting
For CLI tools, developer-facing utilities, and applications where error presentation matters, specialized reporting crates turn error chains into readable, actionable output.
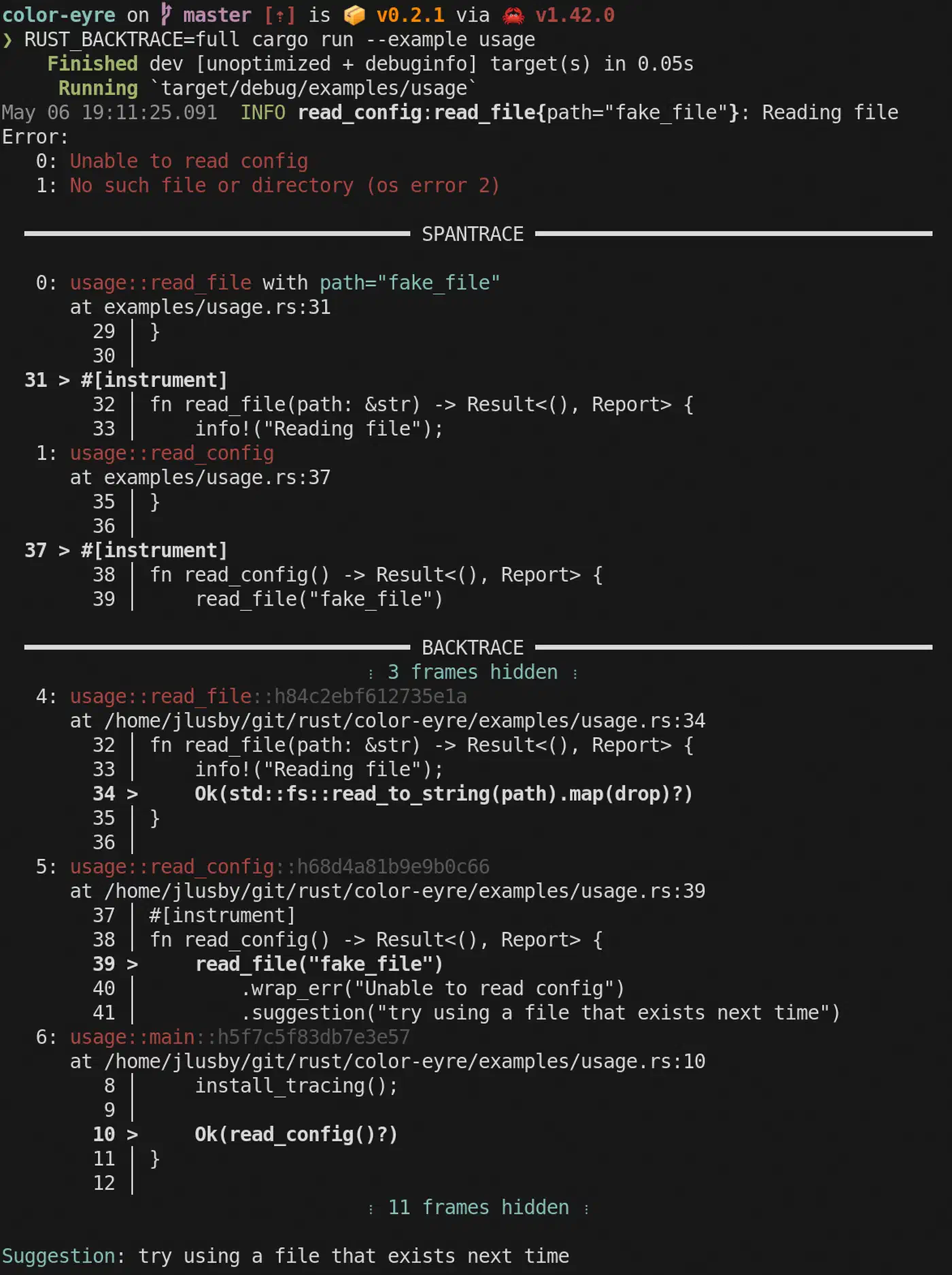
color-eyre
color-eyre
(v0.6.5) replaces anyhow in CLI applications where you want colorized error reports. Install it once at the top of main():
fn main() -> eyre::Result<()> {
color_eyre::install()?;
// ...
}After that, eyre::Result<T> works as a drop-in replacement for anyhow::Result<T>. The difference is in the output: error reports get color-coded with ANSI escape sequences, and if you use the tracing
crate, SpanTrace integration shows which tracing spans were active when the error occurred. Panic reports also get colorized with source location and backtrace information.
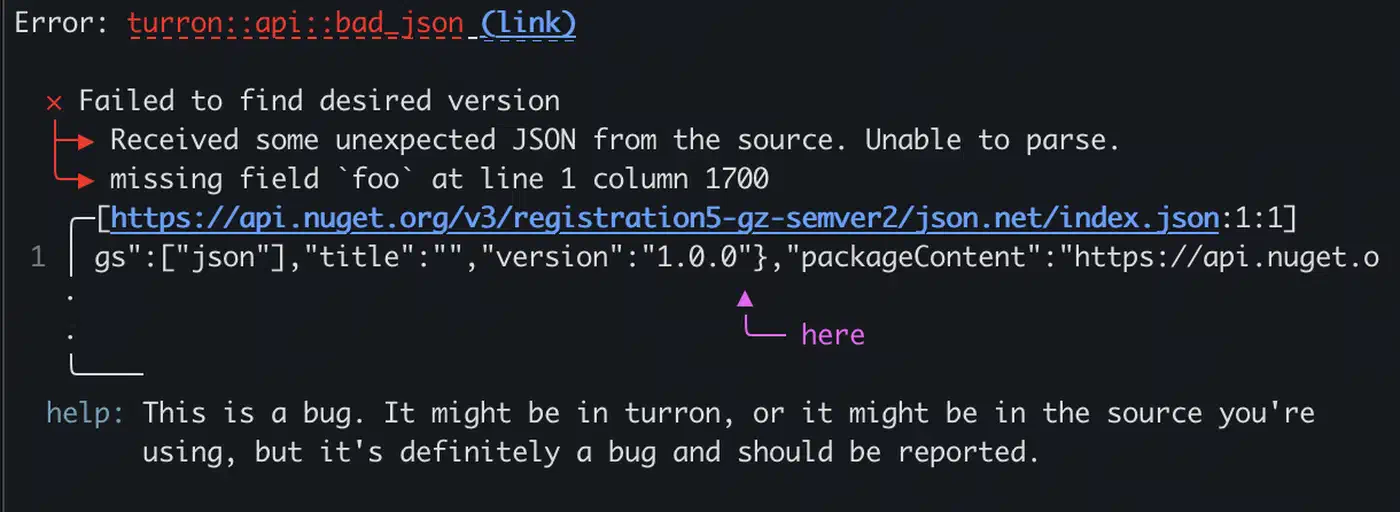
miette
miette (v7.6.0) goes further. It generates rich diagnostic reports with source code snippets, labeled spans pointing to the exact character range that caused the error, help text, and URL links. It is purpose-built for compilers, linters, and developer tools - any situation where you want to show the user exactly what went wrong and where.
#[derive(Debug, miette::Diagnostic, thiserror::Error)]
#[error("invalid config")]
#[diagnostic(
code(config::invalid),
help("check the documentation at https://example.com/config")
)]
struct ConfigError {
#[source_code]
src: String,
#[label("this value is not valid")]
span: SourceSpan,
}When this error is reported, miette renders the source code with an underline pointing to the problematic span, plus the help text and error code. If you have used the Rust compiler’s own error messages, you have seen this style of output.
Error Types in Web Servers
For HTTP servers built with axum
or actix-web
, the pattern shifts slightly. You implement IntoResponse for your error type to map internal errors to appropriate HTTP status codes:
| Error Variant | HTTP Status |
|---|---|
DatabaseError::ConnectionFailed | 503 Service Unavailable |
ValidationError | 400 Bad Request |
AuthenticationDenied | 401 Unauthorized |
NotFound | 404 Not Found |
This keeps error handling consistent throughout the application while translating internal structure into the format HTTP clients expect.
Structured Logging Integration
Combining structured error types with the tracing crate lets you log errors with full context - span data, error chain, backtrace - to structured logging backends. A typical setup sends JSON-formatted logs to systems like Loki or Elasticsearch, where each error carries enough metadata to debug issues without reproducing them locally.
When to Panic vs When to Return Result
The boundary between panic! and Result is not arbitrary. Rust’s standard library documentation gives clear guidance: return Result when failure is an expected possibility that calling code should handle. Panic when continuing would violate a fundamental invariant that makes further execution meaningless or dangerous.
Concrete examples of when panic! is acceptable:
- In tests, where
unwrap()andexpect()are idiomatic because a failed assertion should abort the test - In prototype code where error handling would obscure the logic you are exploring
- When an internal invariant has been violated (an index that should always be in bounds, a state machine transition that should be impossible)
- When external code returns a state so invalid that recovery is not meaningful
For everything else - file I/O, network requests, parsing user input, database queries - use Result. In backend services, favoring recovery over panic
keeps the service running under adverse conditions. A web server that panics on a malformed request takes down the entire process; one that returns a 400 status code keeps serving other clients.
Async Error Handling and Tokio
Error handling in async Rust follows the same patterns, with one wrinkle: tokio::spawn wraps your task’s return value in a JoinHandle, and awaiting that handle gives you a Result<T, JoinError>. If the task itself returns a Result, you end up with Result<Result<T, E>, JoinError> - a nested result where the outer layer represents task-level failures (panics, cancellation) and the inner layer represents your application errors.
The common pattern is to flatten this:
let result = tokio::spawn(async {
do_work().await
}).await;
match result {
Ok(Ok(value)) => { /* task succeeded, work succeeded */ }
Ok(Err(app_err)) => { /* task succeeded, work failed */ }
Err(join_err) => { /* task itself failed (panic or cancel) */ }
}With anyhow, you can use .context() on the JoinError to provide a description of which task failed, keeping the error chain informative even across task boundaries.
Choosing the Right Tool
| Scenario | Recommended Approach |
|---|---|
| Library crate, callers need to match errors | Custom enum + thiserror |
| Binary/CLI, just propagate and display | anyhow |
| CLI with colored output and tracing | color-eyre |
| Compiler, linter, or developer tool | miette |
| Large complex system with rich context | snafu |
| Web server error responses | thiserror + IntoResponse impl |
These crates complement each other rather than compete. Pick thiserror or snafu for your library boundaries, anyhow or color-eyre for your binary, and miette if your tool needs to point at source code. The library vs. application divide is the decision that matters most - get that right and the rest follows.