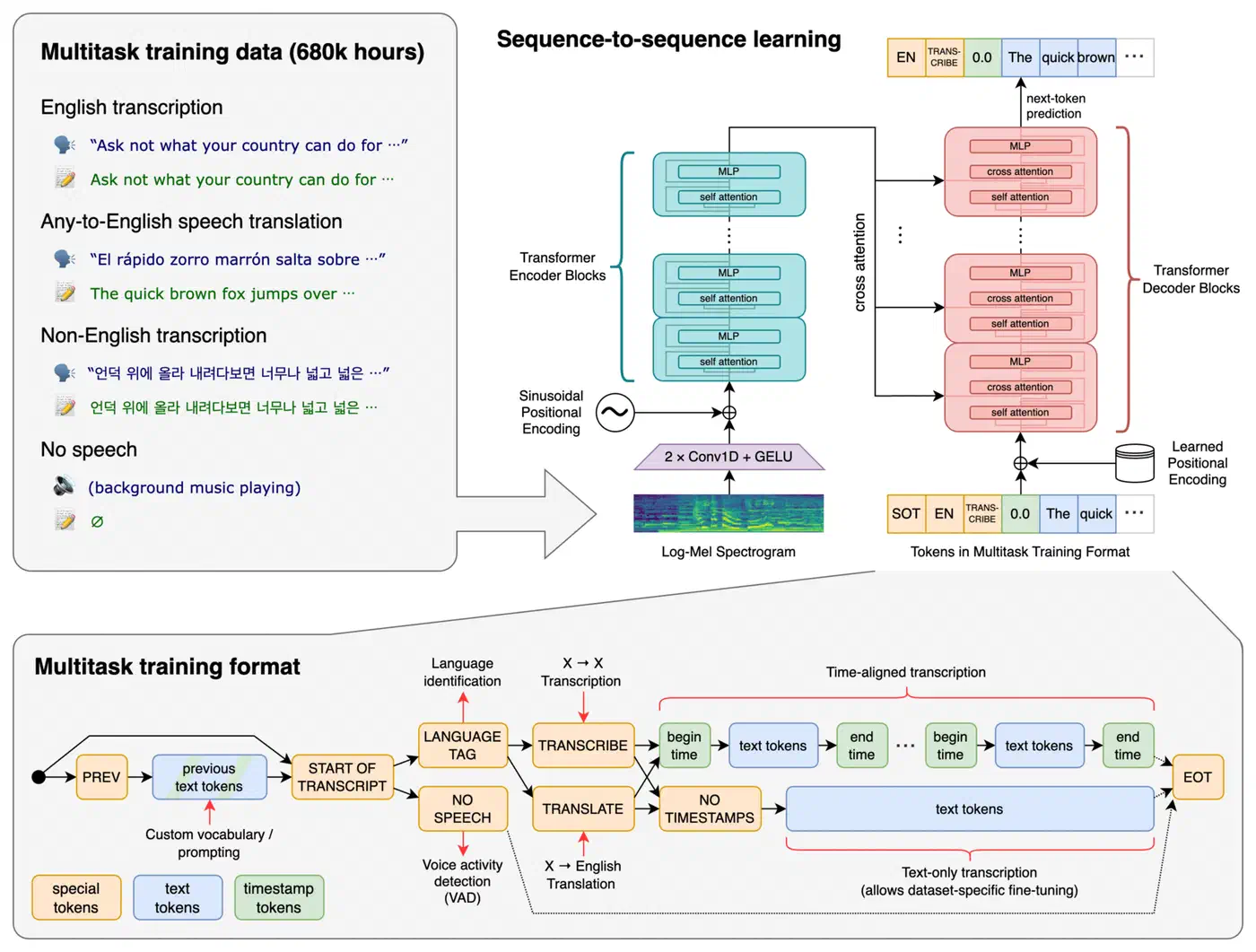
Fine-Tune Whisper with 3 Hours of Audio, 30% WER Gains

OpenAI’s Whisper
is one of the best open-source speech recognition models available. Out of the box, whisper-large-v3-turbo hits roughly 8% word error rate (WER) on general English benchmarks like LibriSpeech. But point it at radiology reports, esports commentary, legal depositions, or manufacturing SOPs and that number can spike to 30-50%. The model simply has not seen enough of those specialized terms during pre-training to transcribe them reliably.
You can fix this. Fine-tuning Whisper on a small dataset of domain-specific audio - as little as one to three hours - with LoRA adapters brings domain-term WER down by 30-60%. The entire training process fits on a single consumer GPU with 12-16 GB of VRAM, takes a couple of hours, and produces an adapter file under 100 MB. What follows is the full process from data preparation through deployment.
When to Fine-Tune Instead of Prompting or Post-Processing
Whisper supports an initial_prompt parameter that biases its decoder toward expected terminology. If you only need to get 5-10 key terms right, this is often enough. You pass the terms in a short prompt and Whisper adjusts its predictions accordingly.
For slightly messier cases, post-processing with a dictionary-based fuzzy matcher or a small language model can catch common misrecognitions after decoding. This adds latency and can introduce its own errors, but it works when the mistakes are predictable and the vocabulary is small.
Fine-tuning makes sense when:
- You have more than 50 unique domain-specific terms that the base model consistently gets wrong
- Accuracy on those terms is critical (medical transcription, legal records, compliance documentation)
- You need consistent output formatting - medical abbreviations, chemical formulas, proprietary product names spelled exactly right
- You are processing enough audio that even small per-file error rates compound into a real problem
The cost is modest. On an RTX 5080 with 16 GB VRAM, a LoRA fine-tuning run takes 2-4 hours of GPU time. The resulting adapter does not change inference speed at all. And you can merge it into the base model for deployment without any extra dependencies.
Which Model to Start From
Your main options in the Whisper family:
| Model | Parameters | Speed | Fine-tuning suitability |
|---|---|---|---|
openai/whisper-large-v3-turbo | 809M | Fast | Best accuracy-to-speed ratio, recommended starting point |
openai/whisper-large-v3 | 1.5B | Moderate | Marginally better accuracy, 2x slower, needs more VRAM |
distil-whisper/distil-large-v3 | ~756M | Fastest | Distilled model, less responsive to fine-tuning |
Start with whisper-large-v3-turbo unless you have a specific reason to use the full 1.5B model. The turbo variant gives you the best tradeoff between transcription quality and resource consumption during both training and inference.
Preparing Your Domain-Specific Dataset
Data quality determines fine-tuning success more than any hyperparameter choice. A clean, well-segmented dataset of one hour will outperform a sloppy dataset of ten hours.
How Much Audio You Need
- 1 hour of accurately transcribed domain audio gives noticeable improvement on key terms
- 3+ hours produces strong, consistent results across the full domain vocabulary
- Beyond 10 hours you hit diminishing returns for narrow domains, though broader domains covering multiple sub-specialties can benefit from more
Audio Format and Segmentation
Whisper expects 16kHz mono audio internally. Pre-convert everything to avoid inconsistencies during training:
ffmpeg -i input.mp3 -ar 16000 -ac 1 output.wavSplit long recordings into segments of 10-30 seconds, aligned to sentence boundaries. WhisperX (v3.3+) handles forced alignment well and gives you timestamps you can use to cut the audio. After automatic segmentation, you will need to manually correct the transcripts - this is the part where the work pays off.
Bootstrapping Transcripts
If you are starting from raw audio with no transcripts at all, run the base Whisper model first to generate rough transcriptions. Then correct the domain-specific terms by hand. This bootstrapping approach is 5-10x faster than transcribing from scratch because most of the common words will already be right - you are only fixing the specialized vocabulary.
Dataset Format
Hugging Face Datasets
expects a DatasetDict with train and test splits. Each example needs:
- An
audiocolumn containing the path to the WAV file - A
transcriptioncolumn with the ground-truth text
from datasets import DatasetDict, Dataset, Audio
train_data = Dataset.from_dict({
"audio": train_audio_paths,
"transcription": train_transcripts
}).cast_column("audio", Audio(sampling_rate=16000))
test_data = Dataset.from_dict({
"audio": test_audio_paths,
"transcription": test_transcripts
}).cast_column("audio", Audio(sampling_rate=16000))
ds = DatasetDict({"train": train_data, "test": test_data})Validation Checklist
Before training, verify:
- No audio leaks between train and test splits (same speaker in the same session should not appear in both)
- Unicode and punctuation are normalized consistently
- All audio files are readable and non-silent
- Blank or near-silent segments are removed
- Transcriptions match the actual audio content
Data Augmentation
If you are short on audio, the audiomentations library lets you stretch your dataset. Apply speed perturbation (0.9x to 1.1x) and add light background noise to create variations without recording additional audio. This improves model robustness, particularly for noisy real-world environments.
from audiomentations import Compose, TimeStretch, AddGaussianNoise
augment = Compose([
TimeStretch(min_rate=0.9, max_rate=1.1, p=0.5),
AddGaussianNoise(min_amplitude=0.001, max_amplitude=0.015, p=0.5),
])Fine-Tuning with Hugging Face Transformers and LoRA
Full fine-tuning of whisper-large-v3-turbo requires 40+ GB of VRAM. LoRA sidesteps this by freezing the base model and training small adapter matrices on the attention layers. You end up updating roughly 2% of the total parameters, which fits comfortably in 11-12 GB of VRAM.
Install Dependencies
pip install "transformers[torch]>=4.48.0" datasets accelerate peft evaluate jiwerPin transformers>=4.48.0 to get the latest Whisper architecture support and bug fixes.
Load the Model and Processor
from transformers import WhisperForConditionalGeneration, WhisperProcessor
model_name = "openai/whisper-large-v3-turbo"
processor = WhisperProcessor.from_pretrained(model_name)
model = WhisperForConditionalGeneration.from_pretrained(model_name)Configure LoRA
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
task_type="SEQ_2_SEQ_LM",
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# Output: trainable params: ~16M || all params: ~809M || trainable%: ~2.0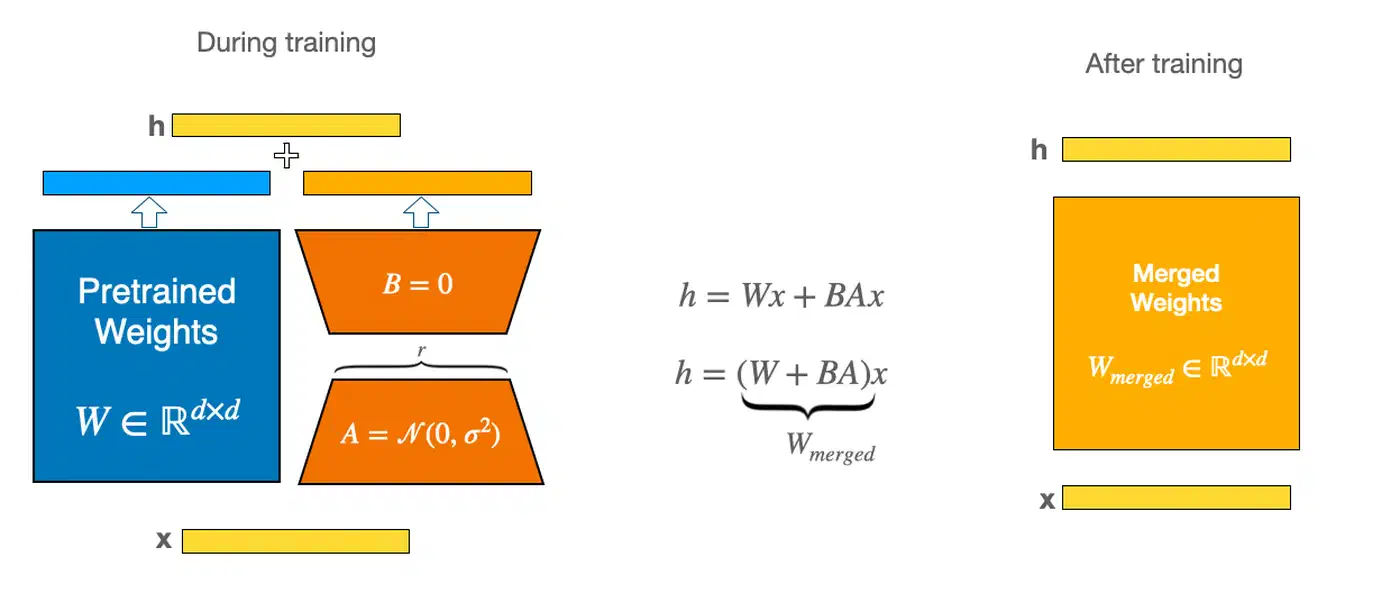
Targeting q_proj and v_proj in the attention layers is the standard starting point. If results are not good enough, you can expand to k_proj and o_proj or increase the rank from 16 to 32. The same LoRA rank and target module choices apply across model types — the Stable Diffusion XL fine-tuning guide
covers the same adapter pattern for image generation if you want to see LoRA applied to a different architecture.
Data Collator and Training Arguments
The data collator handles padding for variable-length audio inputs and sets up the decoder input IDs for English transcription:
from transformers import Seq2SeqTrainingArguments, Seq2SeqTrainer
from dataclasses import dataclass
from typing import Any, Dict, List, Union
import torch
@dataclass
class DataCollatorSpeechSeq2SeqWithPadding:
processor: Any
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
input_features = [{"input_features": f["input_features"]} for f in features]
batch = self.processor.feature_extractor.pad(input_features, return_tensors="pt")
label_features = [{"input_ids": f["labels"]} for f in features]
labels_batch = self.processor.tokenizer.pad(label_features, return_tensors="pt")
labels = labels_batch["input_ids"].masked_fill(
labels_batch.attention_mask.ne(1), -100
)
batch["labels"] = labels
return batch
data_collator = DataCollatorSpeechSeq2SeqWithPadding(processor=processor)training_args = Seq2SeqTrainingArguments(
output_dir="./whisper-finetuned",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=1e-4,
warmup_steps=100,
max_steps=1000,
fp16=True,
evaluation_strategy="steps",
eval_steps=100,
save_steps=100,
predict_with_generate=True,
logging_steps=25,
report_to="none",
)Launch Training
import evaluate
import jiwer
wer_metric = evaluate.load("wer")
def compute_wer(pred):
pred_ids = pred.predictions
label_ids = pred.label_ids
label_ids[label_ids == -100] = processor.tokenizer.pad_token_id
pred_str = processor.tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
label_str = processor.tokenizer.batch_decode(label_ids, skip_special_tokens=True)
wer = wer_metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=ds["train"],
eval_dataset=ds["test"],
data_collator=data_collator,
compute_metrics=compute_wer,
)
trainer.train()Expect roughly 2 hours for 1000 steps on an RTX 5080. VRAM usage should sit around 11 GB with batch size 4 and fp16 enabled. If you hit out-of-memory errors, drop the batch size to 2 and increase gradient_accumulation_steps to 8 to maintain the same effective batch size.
Evaluating and Iterating on Your Fine-Tuned Model
A single WER number on your test set does not tell the whole story. You need to measure domain-term accuracy specifically and verify that general transcription quality has not degraded.
Domain-Term Accuracy
Extract your list of domain-specific terms and compute two metrics:
- Recall: what percentage of domain terms in the reference transcripts does the model transcribe correctly?
- Precision: how often does the model hallucinate similar-sounding non-domain terms where none exist?
def domain_term_recall(references, hypotheses, domain_terms):
hits = 0
total = 0
for ref, hyp in zip(references, hypotheses):
for term in domain_terms:
if term.lower() in ref.lower():
total += 1
if term.lower() in hyp.lower():
hits += 1
return hits / total if total > 0 else 0.0Baseline Comparison
Always run the unmodified base Whisper model on the same test set. Log both overall WER and domain-term WER in a comparison table:
| Metric | Base Model | Fine-Tuned |
|---|---|---|
| Overall WER | 32.1% | 14.7% |
| Domain-term recall | 41% | 87% |
| Domain-term precision | 78% | 94% |
These numbers are illustrative, but 30-60% relative WER reduction on domain terms is typical with 1-3 hours of training data.
Catastrophic Forgetting Check
Test on a slice of LibriSpeech or Common Voice to ensure general transcription quality has not degraded. If WER increases by more than 2% on general audio compared to the base model, your training is overfitting to the domain data. Reduce the number of training steps or lower the learning rate.
Iteration Strategies
If domain-term accuracy is still insufficient after your first training run:
- Add more training examples that contain the problematic terms
- Increase LoRA rank from 16 to 32 (trains more parameters, may capture more complex patterns)
- Train for more steps with a lower learning rate (try 5e-5 instead of 1e-4)
- Expand
target_modulesto includek_projando_projin addition toq_projandv_proj
Merge and Export
Once you are satisfied with the results, merge the LoRA adapter into the base model so you can deploy without the PEFT dependency:
model = model.merge_and_unload()
model.save_pretrained("./whisper-domain-merged")
processor.save_pretrained("./whisper-domain-merged")Deploying Your Fine-Tuned Whisper Model
You have a trained model. Now you need to get it running somewhere other than your training machine.
Quick Local Inference
Load the merged model with the Hugging Face pipeline API:
from transformers import pipeline
pipe = pipeline(
"automatic-speech-recognition",
model="./whisper-domain-merged",
device="cuda",
)
result = pipe("recording.wav")
print(result["text"])This gives you roughly 1.5x real-time speed on an RTX 5080 - fast enough for interactive use but not optimal for batch processing.
Faster Inference with CTranslate2
CTranslate2 and the faster-whisper library can deliver 3x speed improvement and 50% less VRAM usage compared to the standard Hugging Face pipeline:
ct2-opus-converter --model ./whisper-domain-merged \
--output_dir ./whisper-ct2 \
--quantization float16from faster_whisper import WhisperModel
model = WhisperModel("./whisper-ct2", device="cuda", compute_type="float16")
segments, info = model.transcribe("recording.wav")
for segment in segments:
print(f"[{segment.start:.2f}s -> {segment.end:.2f}s] {segment.text}")Docker API Endpoint
For production use, wrap the model in a FastAPI service:
from fastapi import FastAPI, UploadFile
from faster_whisper import WhisperModel
import tempfile
app = FastAPI()
model = WhisperModel("./whisper-ct2", device="cuda", compute_type="float16")
@app.post("/transcribe")
async def transcribe(file: UploadFile):
with tempfile.NamedTemporaryFile(suffix=".wav") as tmp:
tmp.write(await file.read())
tmp.flush()
segments, info = model.transcribe(tmp.name)
return {
"text": " ".join(s.text for s in segments),
"language": info.language,
}Use nvidia/cuda:12.4.1-runtime-ubuntu24.04 as the Docker base image and install faster-whisper and fastapi with uvicorn in your Dockerfile.
Batch Processing
For bulk transcription of large audio collections, parallelize with the Datasets library:
from datasets import Dataset, Audio
audio_ds = Dataset.from_dict({"audio": audio_file_paths})
audio_ds = audio_ds.cast_column("audio", Audio(sampling_rate=16000))
def transcribe_batch(batch):
results = pipe(batch["audio"], batch_size=8)
batch["transcription"] = [r["text"] for r in results]
return batch
transcribed = audio_ds.map(transcribe_batch, batched=True, batch_size=8)Model Versioning
Tag each fine-tuned model with the training dataset version and evaluation scores. Push to a private Hugging Face Hub repository or store in a local model registry. Include the training configuration, WER results on both domain and general test sets, and the date of the training run. This way you can roll back or compare models when you retrain with updated data.
Real-World Integration Examples
Some concrete examples of where this works well:
- Medical dictation: transcribe clinical notes with correct drug names, procedure codes, and anatomical terms, then feed into an EHR system
- Gaming commentary analysis: capture esports terminology, character names, and ability names accurately for automated highlight generation
- Local AI assistant: use as the speech frontend for a voice-controlled assistant where domain accuracy matters more than general conversation
- Manufacturing documentation: transcribe floor workers’ verbal reports with correct part numbers and process names
The model itself is just a checkpoint on disk. How you integrate it depends on your application, but the inference code stays the same regardless of the downstream use case.