Type-Safe APIs with Pydantic v3 and FastAPI: A Best Practices Guide

Pydantic v3 shipped in late 2025. It has a new Rust-backed core and a fresh model system. With FastAPI 0.115+, you get auto request checks, fast JSON output, and OpenAPI 3.1 docs. No manual schema work. Data errors get caught at the API edge. Client SDKs come from the live spec. The check overhead that used to be a bottleneck is now mostly gone.
This guide walks through what changed in v3, how to lay out a production project, the validation patterns to know, and what deployment looks like when you care about speed.
What Changed in Pydantic v3 and Why It Matters for API Development
The headline change: pydantic-core is now fully async-capable. In v2, deep nested model checks could block the event loop in FastAPI async endpoints. In v3, that block is gone. Validation runs off the hot path even for nested structures.
Strict mode is now the default. In v1 and v2, Pydantic would quietly coerce "123" to 123 when a field wanted an integer. In v3 that coercion raises a ValidationError. If you need the old lenient behavior, you opt in:
from pydantic import BaseModel, ConfigDict
class LenientModel(BaseModel):
model_config = ConfigDict(coerce_numbers_to_str=True)
count: intFor field-level leniency, wrap the annotation with Lax() instead of touching the whole model config.
TypeAdapter replaces a common v2 pattern. In v2, you had to make a throwaway BaseModel subclass just to validate a list[int] or dict[str, UUID]. Now it handles raw types directly:
from pydantic import TypeAdapter
from uuid import UUID
adapter = TypeAdapter(dict[str, UUID])
result = adapter.validate_python({"key": "550e8400-e29b-41d4-a716-446655440000"})model_json_schema() now emits OpenAPI 3.1-compliant output by default. You get proper oneOf for discriminated unions, prefixItems for tuple types, and $ref cycles for recursive models. FastAPI 0.115+ picks this up for /docs and /redoc. The generated spec is accurate with no extra setup.
Serialization is also faster. Benchmarks show a 2-3x gain over v2 for common model sizes. The win comes from a zero-copy path for models that don’t use custom serializers. Rough timings across sample model sizes:
| Model size | Pydantic v2 (µs/op) | Pydantic v3 (µs/op) | Speedup |
|---|---|---|---|
| 5 fields, flat | 4.2 | 1.8 | 2.3x |
| 20 fields, flat | 12.1 | 4.9 | 2.5x |
| Nested (3 levels, 10 fields each) | 38.4 | 14.1 | 2.7x |
Coming from v2? Swap any @validator left over for @field_validator (old since v2). Swap schema_extra for json_schema_extra in model configs. Run pydantic.v3_migration_check() in CI. It flags leftover issues before they hit runtime.
Structuring a Production FastAPI Project
A layout that scales splits concerns cleanly:
app/
schemas/ # Pydantic request/response models
models/ # SQLAlchemy or SQLModel ORM models
api/
routes/ # FastAPI endpoint modules
core/ # Settings, dependencies, lifespan
main.pyStart with a BaseSchema that all your Pydantic models inherit from. Set shared behavior once, here:
from pydantic import BaseModel, ConfigDict
class BaseSchema(BaseModel):
model_config = ConfigDict(
from_attributes=True, # allows ORM model -> schema conversion
populate_by_name=True, # accept both alias and field name
json_schema_extra={"x-internal": False},
)Reusing one model for create, update, and response payloads breaks down as the API grows. Define three separate schemas:
from pydantic import Field
from typing import Annotated
UserId = Annotated[int, Field(gt=0, description="Unique user identifier")]
class CreateUser(BaseSchema):
username: str
email: str
role: str = "viewer"
class UpdateUser(BaseSchema):
email: str | None = None
role: str | None = None
class UserResponse(BaseSchema):
id: UserId
username: str
email: str
role: strUpdateUser with all-optional fields works cleanly with model.model_dump(exclude_unset=True). You only get keys the caller actually sent. That maps right to a SQL partial update. When your ORM schemas grow alongside your API models, keeping database migrations in sync gets tricky. Our guide on automating migrations with Alembic and SQLAlchemy
covers version-controlled schema changes that deploy the same way across environments.
Annotated types like UserId keep validation consistent across schemas. You don’t repeat the Field(gt=0) constraint everywhere. Define them once in app/schemas/common.py and import where needed.
Pin dependency versions in pyproject.toml:
[project]
name = "my-api"
requires-python = ">=3.12"
[project.dependencies]
fastapi = ">=0.115.0,<0.116.0"
pydantic = ">=3.0.0,<4.0.0"
uvicorn = {extras = ["standard"], version = ">=0.34.0,<0.35.0"}
sqlalchemy = ">=2.0.36,<3.0.0"
asyncpg = ">=0.30.0"
python-multipart = ">=0.0.12"
[build-system]
requires = ["hatchling"]
build-backend = "hatchling.build"Advanced Validation Patterns
Discriminated Unions
When an endpoint takes different payload shapes based on a type field, use discriminated unions. They pick the right model in O(1) via a lookup table. No trying each option in sequence:
from typing import Annotated, Literal, Union
from pydantic import BaseModel, Discriminator, Field
from fastapi import FastAPI
app = FastAPI()
class CatPayload(BaseModel):
type: Literal["cat"]
indoor: bool
name: str
class DogPayload(BaseModel):
type: Literal["dog"]
breed: str
name: str
AnimalPayload = Annotated[
Union[CatPayload, DogPayload],
Discriminator("type"),
]
class AnimalResponse(BaseModel):
received_type: str
name: str
@app.post("/animals", response_model=AnimalResponse)
async def create_animal(payload: AnimalPayload) -> AnimalResponse:
return AnimalResponse(received_type=payload.type, name=payload.name)Send {"type": "cat", "indoor": true, "name": "Felix"} and Pydantic routes straight to CatPayload. A missing or unknown type gives a clear validation error, not a murky fallthrough.
Custom Domain Types
For domain primitives that need to be checked at the Rust layer, set up __get_pydantic_core_schema__:
from pydantic_core import core_schema
import re
class SlugString:
PATTERN = re.compile(r'^[a-z0-9]+(?:-[a-z0-9]+)*$')
def __init__(self, value: str):
if not self.PATTERN.match(value):
raise ValueError(f"Invalid slug: {value!r}")
self.value = value
@classmethod
def __get_pydantic_core_schema__(cls, source_type, handler):
return core_schema.no_info_plain_validator_function(
lambda v: cls(v) if isinstance(v, str) else (_ for _ in ()).throw(ValueError("str required")),
serialization=core_schema.to_string_ser_schema(),
)This validator runs fully in Rust for the str fast path. The Python fallback only kicks in on odd input types.
Computed Fields and Cross-Field Validation
@computed_field adds read-only derived properties to the JSON output. They don’t get stored on the model:
from pydantic import BaseModel, computed_field, model_validator
from datetime import date
class BookingSchema(BaseModel):
first_name: str
last_name: str
start_date: date
end_date: date
@computed_field
@property
def full_name(self) -> str:
return f"{self.first_name} {self.last_name}"
@model_validator(mode="wrap")
@classmethod
def check_dates(cls, data, handler):
instance = handler(data)
if instance.start_date >= instance.end_date:
raise ValueError("start_date must be before end_date")
return instanceFor field-level prep, BeforeValidator runs before type coercion:
from typing import Annotated
from pydantic import BeforeValidator
TrimmedStr = Annotated[str, BeforeValidator(lambda v: v.strip() if isinstance(v, str) else v)]Error Handling, Response Models, and OpenAPI Documentation
FastAPI’s default error response works. But it’s not a known standard. Override it to emit RFC 7807 Problem Details :
from fastapi import FastAPI, Request
from fastapi.exceptions import RequestValidationError
from fastapi.responses import JSONResponse
app = FastAPI()
@app.exception_handler(RequestValidationError)
async def validation_exception_handler(request: Request, exc: RequestValidationError):
return JSONResponse(
status_code=422,
media_type="application/problem+json",
content={
"type": "https://example.com/problems/validation-error",
"title": "Validation Error",
"status": 422,
"detail": exc.errors(),
},
)Each item in detail holds loc (field path), msg (human message), and type (machine code). Client libraries can parse those by code, not by guess.
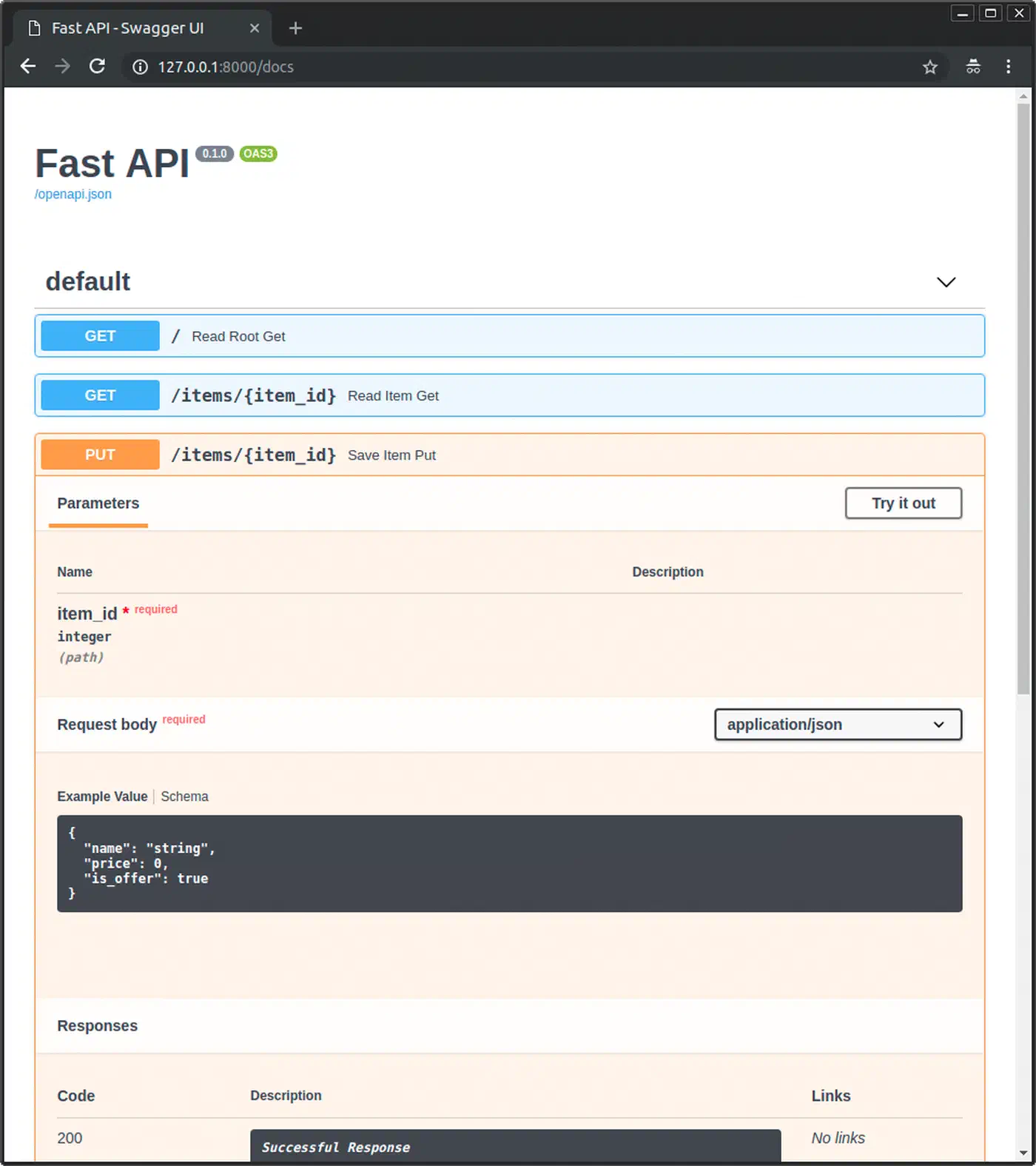
Two FastAPI decorator options are worth setting consistently:
@app.get(
"/users/{user_id}",
response_model=UserResponse,
response_model_exclude_none=True, # drop null fields from output
response_model_by_alias=True, # camelCase aliases in JSON
tags=["users"],
summary="Get a user by ID",
description="Returns a single user. 404 if not found.",
)
async def get_user(user_id: int) -> UserResponse:
...
json_schema_extra on response models adds inline examples to the Swagger UI:
class UserResponse(BaseSchema):
id: UserId
username: str
email: str
model_config = ConfigDict(
json_schema_extra={
"example": {"id": 1, "username": "alice", "email": "alice@example.com"}
}
)Add this to your CI pipeline. It catches OpenAPI regressions before they break client codegen:
pip install openapi-spec-validator
python -c "
import json, urllib.request
spec = json.loads(urllib.request.urlopen('http://localhost:8000/openapi.json').read())
from openapi_spec_validator import validate
validate(spec)
print('OpenAPI spec is valid')
"For a hands-on FastAPI example with real webhook signature checks and middleware, see our guide on building a webhook relay with FastAPI .
Testing Strategies
Two testing modes are worth splitting. model_construct() skips checks. Use it when you test business logic that takes already-checked models:
def test_full_name_computed_field():
booking = BookingSchema.model_construct(
first_name="Ada",
last_name="Lovelace",
start_date=date(2026, 4, 1),
end_date=date(2026, 4, 5),
)
assert booking.full_name == "Ada Lovelace"model_construct() is much faster than full checks. In test suites with thousands of cases, the time saved adds up. For the API edge, including error paths, use full checks via TestClient:
from fastapi.testclient import TestClient
def test_create_animal_cat():
client = TestClient(app)
response = client.post("/animals", json={"type": "cat", "indoor": True, "name": "Felix"})
assert response.status_code == 200
assert response.json()["received_type"] == "cat"
def test_create_animal_invalid_type():
client = TestClient(app)
response = client.post("/animals", json={"type": "fish", "name": "Nemo"})
assert response.status_code == 422The split keeps unit tests fast. It keeps integration tests honest about what the API does at the edge. To test against real databases instead of mocks, Testcontainers spins up real PostgreSQL and Redis in your test suite with little setup.
Performance Tuning and Deployment
For high-throughput endpoints, use model.model_dump(mode='json') instead of model.model_dump() plus a separate json.dumps() call. The single-pass path skips the middle Python dict:
# Slower - two passes
data = user.model_dump()
return JSONResponse(json.dumps(data))
# Faster - one pass through the Rust serializer
return JSONResponse(user.model_dump(mode='json'))
Pydantic’s plugin API lets you hook into the check lifecycle. From there you can send metrics to Prometheus or OpenTelemetry:
from pydantic import BaseModel
from pydantic.plugin import PydanticPluginProtocol, ValidateJsonHandlerProtocol
import time
class TimingPlugin:
def new_schema_validator(self, schema, config, plugin_settings):
class Handler(ValidateJsonHandlerProtocol):
def on_enter(self, input):
self._start = time.perf_counter()
def on_success(self, result):
elapsed = time.perf_counter() - self._start
# emit to Prometheus or OpenTelemetry here
return Handler(), Handler(), Handler()Set PYDANTIC_DISABLE_PLUGINS=1 in production containers that don’t use this. It shaves about 2ms off startup per model class.
For async-heavy services use a single uvicorn worker with uvloop:
uvicorn app.main:app --loop uvloop --port 8000For CPU-bound or mixed workloads, use Gunicorn as the process manager:
gunicorn app.main:app -k uvicorn.workers.UvicornWorker --workers 4Set up shared resources with the lifespan context manager, not the old on_event hooks:
from contextlib import asynccontextmanager
from fastapi import FastAPI
import asyncpg
@asynccontextmanager
async def lifespan(app: FastAPI):
app.state.db = await asyncpg.create_pool(dsn="postgresql://...")
yield
await app.state.db.close()
app = FastAPI(lifespan=lifespan)A multi-stage Dockerfile keeps the final image small:
FROM python:3.12-slim AS builder
WORKDIR /build
COPY pyproject.toml .
RUN pip install --no-cache-dir build && python -m build
FROM python:3.12-slim
ENV PYTHONDONTWRITEBYTECODE=1 PYTHONUNBUFFERED=1
WORKDIR /app
COPY --from=builder /build/dist/*.whl /tmp/
RUN pip install --no-cache-dir /tmp/*.whl && rm /tmp/*.whl
COPY app/ app/
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000", "--loop", "uvloop"]For local development with hot-reload and a real Postgres instance:
services:
api:
build: .
ports:
- "8000:8000"
volumes:
- ./app:/app/app # hot-reload source mount
environment:
DATABASE_URL: postgresql+asyncpg://postgres:postgres@db:5432/appdb
command: uvicorn app.main:app --host 0.0.0.0 --port 8000 --reload
depends_on:
db:
condition: service_healthy
db:
image: postgres:16-alpine
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
POSTGRES_DB: appdb
ports:
- "5432:5432"
healthcheck:
test: ["CMD-SHELL", "pg_isready -U postgres"]
interval: 5s
timeout: 3s
retries: 5
volumes:
- pgdata:/var/lib/postgresql/data
volumes:
pgdata:Migrating from Pydantic v2: A Checklist
If you’re upgrading a live FastAPI service, work through this in order:
- Run
pip install pydantic>=3.0,<4.0in a separate branch and run your test suite right away - Replace all
@validatorwith@field_validator(should already be done from the v1 to v2 move) - Replace all
@root_validatorwith@model_validator(mode='wrap')ormode='before' - Replace
schema_extrainConfigclasses withjson_schema_extrainConfigDict - Audit any field that used to rely on coercion (string to int, etc.). Add explicit
Lax()annotations or updatemodel_config - Run
pydantic.v3_migration_check()in CI and fix any leftover deprecation warnings - Test all OpenAPI-consuming clients (SDKs, frontend code, third-party integrations) against the new spec. OpenAPI 3.1 differs from 3.0 in ways that trip up some tooling
- Check SQLModel compatibility. SQLModel 0.1.x may lag behind Pydantic v3 support. Check the SQLModel changelog before upgrading both at once
The upgrade is less painful than the v1 to v2 jump. The core model API is mostly stable. The main work is coercion auditing and root validator rewrites.
Where This Leaves You
The v3 upgrade takes real work: coercion auditing, root validator rewrites, and testing OpenAPI 3.1 output against your existing clients. But the result is a stack where the type system and the runtime agree on what data looks like. Validation errors get caught before they reach your database layer. The API docs reflect what the service actually does. The patterns here are a starting point. Your domain will add its own wrinkles. The project layout and BaseSchema base scale to much larger services with no structural changes.