MCP Server Development: Build Custom Tools for Claude and Local LLMs

The Model Context Protocol
gives LLMs a standard way to call external tools, read files, and query databases. You skip the rewrite each time you switch models. You can build a working MCP server in Python with the official mcp SDK in under 100 lines. It runs with Claude Desktop or Claude Code in minutes. This guide walks the full path, from a tiny first server to production.
What MCP Is and Why It Changes Tool Use
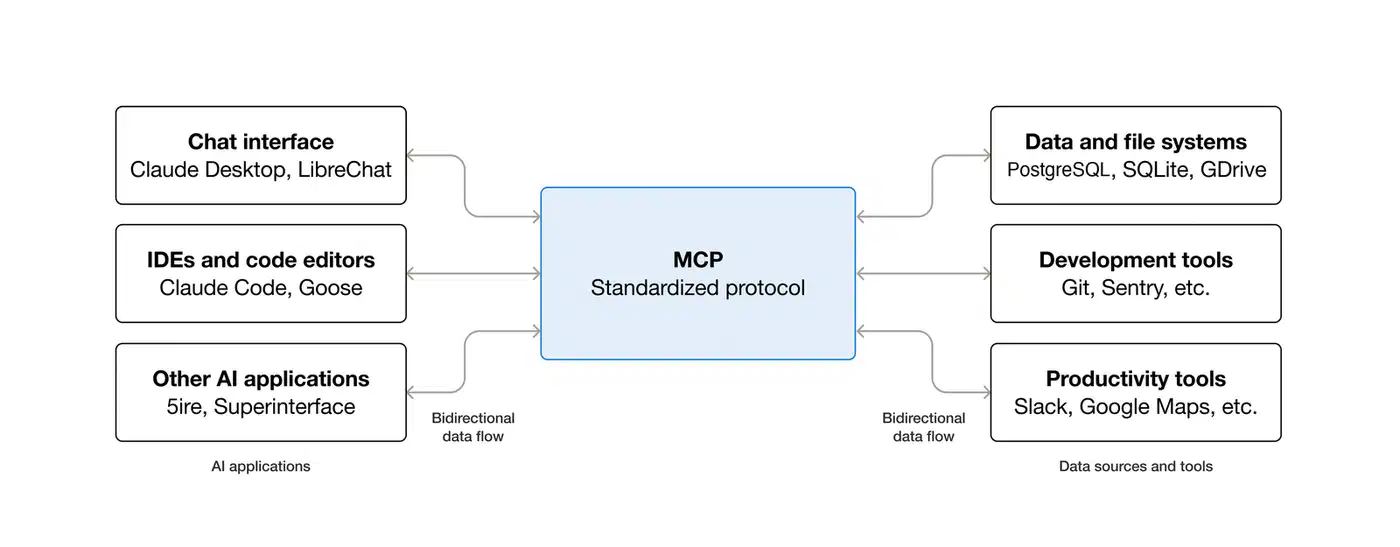
MCP is a JSON-RPC 2.0 protocol. It lets an LLM client (like Claude Desktop
, Claude Code, or Cursor) find and call tools exposed by a server process. The big shift from older function-calling is the discovery step. Instead of hard-coding tool defs into every prompt, the client sends a tools/list request when it connects. It gets back the full schema for everything the server exposes. Add a new tool, restart the server, and any client sees it on the next connect.
The spec defines three primitive types:
- Tools: model-invoked functions that do things (read a file, query a database, call an API)
- Resources: app-controlled data the model can read, like file contents or database rows
- Prompts: reusable prompt templates the user or model can invoke
The spec also defines two transport modes. stdio runs the server as a child process of the MCP client. SSE/HTTP runs the server as a standalone network service. For single-user local setups, stdio is simpler and safer because no network port is open. SSE mode is the right pick when many clients or users share one server instance.
MCP ships natively in Claude Desktop, Claude Code , Cursor, Windsurf, VS Code Copilot agents, and several Ollama front-ends like Open WebUI. Anthropic wrote the spec, but it now sees broad industry pick-up. The TypeScript and Python SDKs are kept alive by the community and Anthropic together.
One thing the spec handles well is capability negotiation. When the client connects, a full initialize handshake runs before any tool is called. Both sides agree on a protocol version and a set of optional features. If your server crashes at startup, or writes stray text to stdout before the handshake ends, the client fails silently. The debug section below covers this common early headache.
Setting Up Your Development Environment
The recommended Python setup uses uv
for dependency management:
uv init mcp-server
cd mcp-server
uv add "mcp[cli]>=1.5"This creates a virtual env and lockfile on its own. If you prefer pip, the same call is pip install "mcp[cli]>=1.5". The [cli] extra installs the mcp command-line tool. You use it to run and test servers directly.
For TypeScript, the setup is:
npm init -y
npm install @modelcontextprotocol/sdk@^2.0For simple servers, a single server.py (or index.ts) file is enough. Larger projects do better when tool defs live in a tools/ folder. The main server file then stays focused on startup and routing.
Registering with Claude Desktop: Edit ~/.config/Claude/claude_desktop_config.json on Linux. Use the matching path on macOS or Windows. Then add your server entry:
{
"mcpServers": {
"my-tools": {
"command": "uv",
"args": ["run", "server.py"],
"cwd": "/path/to/mcp-server"
}
}
}For Claude Code, use the CLI: claude mcp add my-tools -- uv run server.py. This writes the config to .claude/settings.json in the current project. It also persists across sessions.
MCP Inspector is worth installing before you write one line of server code: npx @modelcontextprotocol/inspector. It opens a browser GUI. You manually send tools/list and tools/call requests against any server. The raw JSON-RPC exchange shows up in real time. Running it against your server before you wire in a real LLM catches schema errors and handler crashes on the spot. You skip the noise of debugging through an LLM client.
Building Your First MCP Server
The Python SDK’s FastMCP class handles protocol handshake, capability ads, and request routing. A tiny file-reading server looks like this:
from mcp.server.fastmcp import FastMCP
server = FastMCP("my-tools")
@server.tool()
def read_file(path: str) -> str:
"""Read a file's contents. Path must be within the allowed directory."""
import os
allowed_base = "/home/user/documents"
abs_path = os.path.realpath(path)
if not abs_path.startswith(allowed_base):
return f"Error: access denied - path must be within {allowed_base}"
with open(abs_path) as f:
return f.read()
if __name__ == "__main__":
server.run()The @server.tool() decorator turns the function’s type hints and docstring into the JSON schema the LLM receives. The function signature is the tool’s API. Parameter names and the docstring are what the model sees when it picks a tool to call. Write them the way you would write docs for another developer.
The path traversal check above is not optional. The LLM controls the path argument, so treat it as untrusted input
. os.path.realpath() resolves symlinks before the prefix check. A path like /home/user/documents/../../../etc/passwd won’t slip through.
A tool that calls a REST API uses the same pattern with async support:
import httpx
import os
@server.tool()
async def search_gitea(query: str, repo: str = "") -> str:
"""Search code or issues in the local Gitea instance."""
token = os.environ.get("GITEA_TOKEN")
if not token:
return "Error: GITEA_TOKEN environment variable not set"
base_url = os.environ.get("GITEA_URL", "http://localhost:3000")
headers = {"Authorization": f"token {token}"}
async with httpx.AsyncClient() as client:
params = {"q": query, "limit": 10}
if repo:
params["repos"] = repo
resp = await client.get(
f"{base_url}/api/v1/repos/search",
headers=headers,
params=params,
timeout=10.0
)
resp.raise_for_status()
data = resp.json()
results = [f"- {r['full_name']}: {r['description']}" for r in data.get("data", [])]
return "\n".join(results) if results else "No results found"Credentials go in env vars, not source code. Pass them via the env field in the MCP client config:
{
"mcpServers": {
"my-tools": {
"command": "uv",
"args": ["run", "server.py"],
"env": {
"GITEA_TOKEN": "your-token-here",
"GITEA_URL": "http://localhost:3000"
}
}
}
}Resources are not the same as tools. The model calls tools on its own. Resources are data the app exposes that the model can read when told to. Use @server.resource() for things like listing the config files on disk:
@server.resource("config://list")
def list_configs() -> str:
"""List available configuration files."""
import glob
files = glob.glob("/home/user/.config/myapp/*.yaml")
return "\n".join(files)Run the server in stdio mode with mcp run server.py. For SSE, add --transport sse --port 8808.
Database Integration and Security
SQLite uses Python’s standard library and needs no extra packages:
import sqlite3
@server.tool()
def query_logs(level: str = "error", limit: int = 50) -> str:
"""Query application logs by severity level."""
allowed_levels = {"debug", "info", "warning", "error", "critical"}
if level.lower() not in allowed_levels:
return f"Error: level must be one of {', '.join(sorted(allowed_levels))}"
conn = sqlite3.connect("/var/log/myapp/logs.db")
cursor = conn.cursor()
cursor.execute(
"SELECT timestamp, message FROM logs WHERE level = ? ORDER BY timestamp DESC LIMIT ?",
(level, min(limit, 200))
)
rows = cursor.fetchall()
conn.close()
return "\n".join(f"[{r[0]}] {r[1]}" for r in rows)Two things to notice. The parameterized query (? placeholders) blocks SQL injection even if the LLM makes a hostile level string. The allowed_levels allowlist adds a second layer of checks. The limit cap stops the model from asking for thousands of rows in one call. That’s a real concern in multi-step agentic workflows, where tools run in tight loops.
For PostgreSQL, use asyncpg with connection pooling:
import asyncpg
import asyncio
_pool = None
async def get_pool():
global _pool
if _pool is None:
_pool = await asyncpg.create_pool(os.environ["DATABASE_URL"])
return _pool
@server.tool()
async def lookup_user(email: str) -> str:
"""Look up a user account by email address."""
pool = await get_pool()
async with pool.acquire() as conn:
row = await conn.fetchrow(
"SELECT id, name, created_at FROM users WHERE email = $1",
email
)
if row is None:
return "User not found"
return f"ID: {row['id']}, Name: {row['name']}, Created: {row['created_at']}"Connection pooling skips the TCP handshake cost of opening a fresh database connection on every tool call. The LLM can fire tools many times in one conversation turn. Per-call setup time adds up fast.
Using Pydantic models as tool parameter types lifts reliability a lot. It pairs well with structured output techniques when you need the LLM itself to produce valid JSON. Swap primitive types for a model when a tool takes several structured inputs:
from pydantic import BaseModel, Field
class SearchParams(BaseModel):
query: str = Field(..., description="Search terms to look for")
max_results: int = Field(10, ge=1, le=100, description="Maximum results to return")
@server.tool()
def search_docs(params: SearchParams) -> str:
"""Search the documentation index."""
# Pydantic has already validated and coerced the inputs
...The JSON schema exposed via tools/list is built from the Pydantic model. That includes limits like ge=1, le=100. Well-behaved LLM clients use these limits to make valid inputs. The check runs on its own before your handler function fires.
For SSE transport, add Bearer token auth in middleware. Store tokens hashed on the server and rotate them like any API key. Rate limiting is also worth wiring in before any server takes real traffic. A sliding window counter per tool name, backed by a collections.deque, is enough to stop a runaway agentic loop from hitting external APIs hundreds of times per minute.
Testing, Debugging, and Deployment
Test tool handler functions on their own, away from the MCP protocol. They’re regular Python functions, so pytest works directly:
# test_server.py
from server import read_file, query_logs
def test_read_file_blocks_traversal():
result = read_file("/home/user/documents/../../../etc/passwd")
assert result.startswith("Error: access denied")
def test_query_logs_rejects_invalid_level():
result = query_logs(level="DROP TABLE users")
assert result.startswith("Error:")
def test_query_logs_caps_limit():
# Should not raise even with an unreasonably large limit
result = query_logs(level="error", limit=99999)
assert isinstance(result, str)For protocol-level debugging, start with MCP Inspector (npx @modelcontextprotocol/inspector). Point it at your server command or SSE URL. Then craft tools/call payloads by hand to check response schemas and error paths.
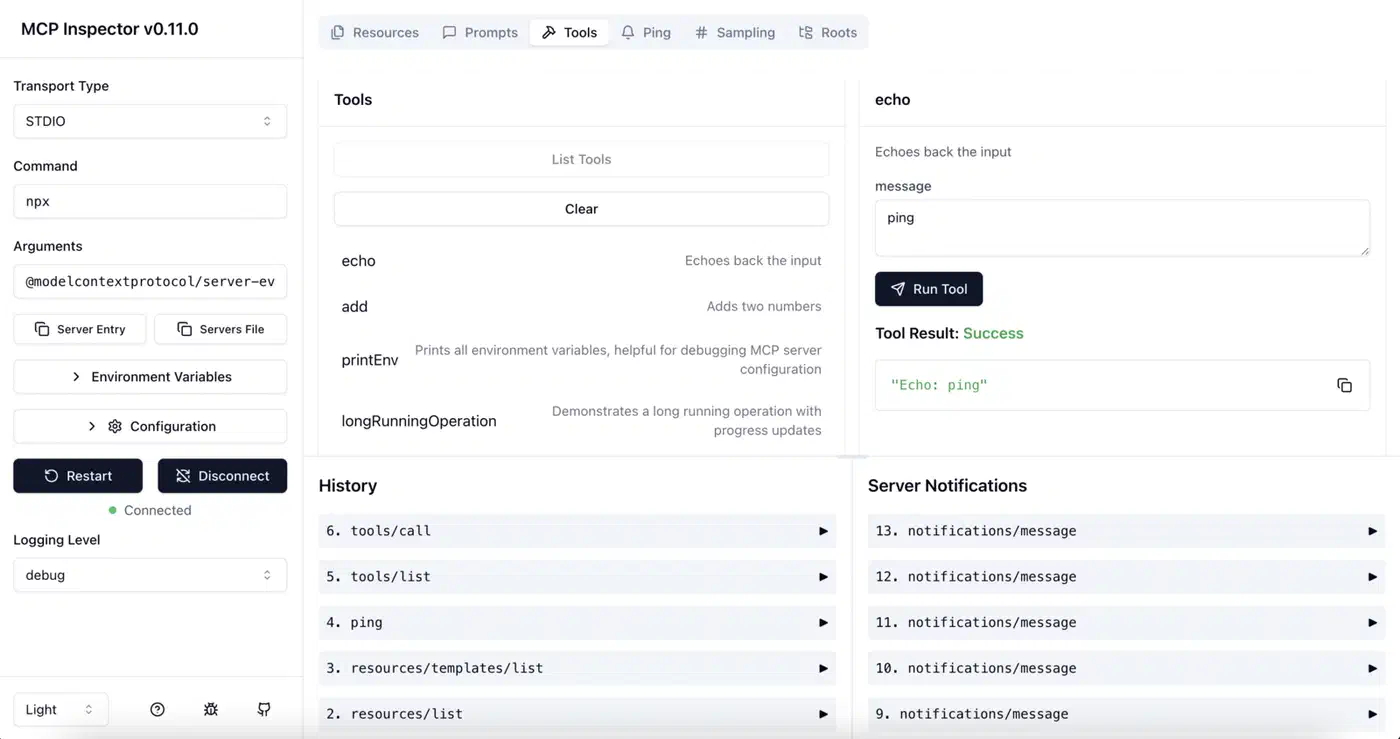
When things go wrong at the transport level, set MCP_LOG_LEVEL=debug before you start the server. This logs every JSON-RPC message to stderr. Most “tool not found” errors in production trace back to a failed init handshake. The usual cause is the server crashing at startup, or printing debug text to stdout before the first JSON-RPC message. That stray text corrupts the stream.
For production with SSE mode, run the server behind a reverse proxy with TLS termination. A tiny systemd unit:
[Unit]
Description=My MCP Server
After=network.target
[Service]
Type=simple
User=mcpuser
WorkingDirectory=/opt/mcp-server
EnvironmentFile=/etc/mcp-server/environment
ExecStart=/opt/mcp-server/.venv/bin/mcp run server.py --transport sse --port 8808
Restart=on-failure
[Install]
WantedBy=multi-user.targetDocker Compose works well for servers that need a database or fenced file system access:
services:
mcp-server:
build: .
ports:
- "127.0.0.1:8808:8808"
environment:
- DATABASE_URL=postgresql://user:pass@db:5432/mydb
volumes:
- /home/user/documents:/documents:ro
depends_on:
- db
db:
image: postgres:16
volumes:
- pgdata:/var/lib/postgresql/data
volumes:
pgdata:Binding to 127.0.0.1 on the host side means only local processes can reach the server. The ro mount flag on the document volume blocks the server from writing to the host file system, even if a bug in the tool handler tries.
One setup worth a look for local LLMs: if you run Ollama with a front-end like Open WebUI, SSE mode lets many model sessions share the same MCP server and its connection pool. The overhead is small. You skip the chore of running a separate server process per user session.
Typed tool schemas, Pydantic checks, parameterized queries, and env-based credential injection cover most of the security concerns in real MCP servers. The remaining work, rate limiting, SSE auth, and audit logging, follows the same patterns you’d apply to any internal API service.
Running Multiple Servers Together
MCP clients can connect to several servers at once. Claude Desktop and Claude Code both support this. You add many entries under mcpServers in the config, and each one runs as a separate process. The client merges every tool schema from every connected server into one list. It then routes each tools/call to the right server, based on the tool name.
This split is useful for keeping concerns apart. A database server, a file-system server, and an API server can be built and updated on their own. When you fix a bug in the database server, you restart only that process. The others stay up.
One naming caveat: tool names must be unique across all connected servers. If two servers expose a tool called read_file, the client behavior is undefined. In practice, one silently shadows the other. Prefix your tool names with a namespace (db_query_logs, fs_read_file) to dodge conflicts when many servers run side by side.
For teams sharing MCP servers across many developers, SSE mode plus a project-scoped config (.claude/settings.json checked into the repo) gives a clean setup. Everyone on the team gets the same tools the moment they clone the project. The server itself can run on shared infra, or as a Docker service in the project’s compose stack.
If hand-writing a server feels like too much work, some tools that auto-generate tested CLIs for GUI apps offer an alternative to the MCP route.