Open-Weight Coding Models Ranked by Capability Per GB (2026)

The best open-weight coding model you can run on a 24 GB GPU in 2026 is Qwen3.6-27B at Q4. It scores 77.2 on SWE-bench Verified while fitting in about 17 GB, the highest coding skill per gigabyte you can actually load at home. DeepSeek V4 wins the leaderboard, but no consumer card can hold it. Most of these leaders come from China’s frontier coding models .
Key Takeaways
- Qwen3.6-27B at Q4 gives the most coding skill per GB on a 24 GB card.
- DeepSeek V4 tops the leaderboard, but no home GPU can run it.
- GLM-4.7-Flash fits 24 GB and still clears 59 percent on SWE-bench.
- Qwen and Devstral ship Apache 2.0; the big models lean on MIT.
- Pick by the GPU you own, not by the top of the leaderboard.
Why Capability Per GB Beats the Leaderboard
Most 2026 roundups rank coding models by the score of a flagship variant that needs a multi-GPU server. For anyone running models at home, that number is a fantasy. The only figure that counts is how much coding skill fits in the VRAM you actually own.
So this post uses a different metric: SWE-bench Verified points divided by the VRAM in gigabytes that the smallest usable local quant needs. A 1.6 trillion-parameter model scoring 80.6 means nothing if it never loads on your card, one reason raw benchmark scores tell only part of the story. Therefore the “best” model changes depending on the GPU in your machine.
The consumer VRAM ladder in 2026 has three meaningful rungs. There’s the 16 GB tier (RTX 5070 Ti and 4060 Ti class), the 24 GB tier (RTX 3090, 4090, and 5080), and the 32 GB tier (RTX 5090). Apple Silicon adds unified memory from 32 GB up to 128 GB, which behaves differently again.
Q4_K_M is the default quant for every fit calculation here. It roughly halves VRAM versus Q8 with a small quality loss, so it’s the sweet spot for local use. Most local LLM runtimes load these GGUF quants out of the box. Q8 shows up only where a 32 GB card or a big Mac unlocks it.
In day-to-day use on a 24 GB card, the split between dense and sparse models becomes obvious fast. A dense 27B model generates at roughly 43 tokens per second, which feels fine for editing. A Mixture-of-Experts (MoE) model like the 35B-A3B fires only about 3 billion parameters per token, so it streams at around 120 tokens per second on the same 4090. Meanwhile the leaderboard champion sits unused, because it simply will not fit.
What Are the Best Open-Weight Coding Models in 2026?
Four families are worth a local user’s attention. Each ships open weights, posts a real coding score, and offers at least one variant small enough to consider. Here’s the headline picture before the local-fit lens narrows things down.
Qwen from Alibaba leads the open field. The general-purpose Qwen3.6-27B dense model posts 77.2 on SWE-bench Verified and is widely called the strongest open coding model that fits a 24 GB card. The Qwen3.6-35B-A3B MoE trails slightly at 73.4 but generates much faster. The older Qwen3-Coder line (480B-A35B and 30B-A3B) rounds out the family, all under Apache 2.0. For a broader open model comparison beyond coding, Qwen also holds up well against Gemma and Llama.
DeepSeek V4 wins on raw score. Released April 24, 2026 under MIT, it ships in two sizes: V4-Pro (1.6 trillion total, 49 billion active) and V4-Flash (284 billion, 13 billion active), both with a 1M-token context. V4-Pro hits 80.6 SWE-bench Verified and a leading 93.5 on LiveCodeBench, the highest open scores of the year . The architecture tricks behind DeepSeek V4 explain how it reaches those numbers.
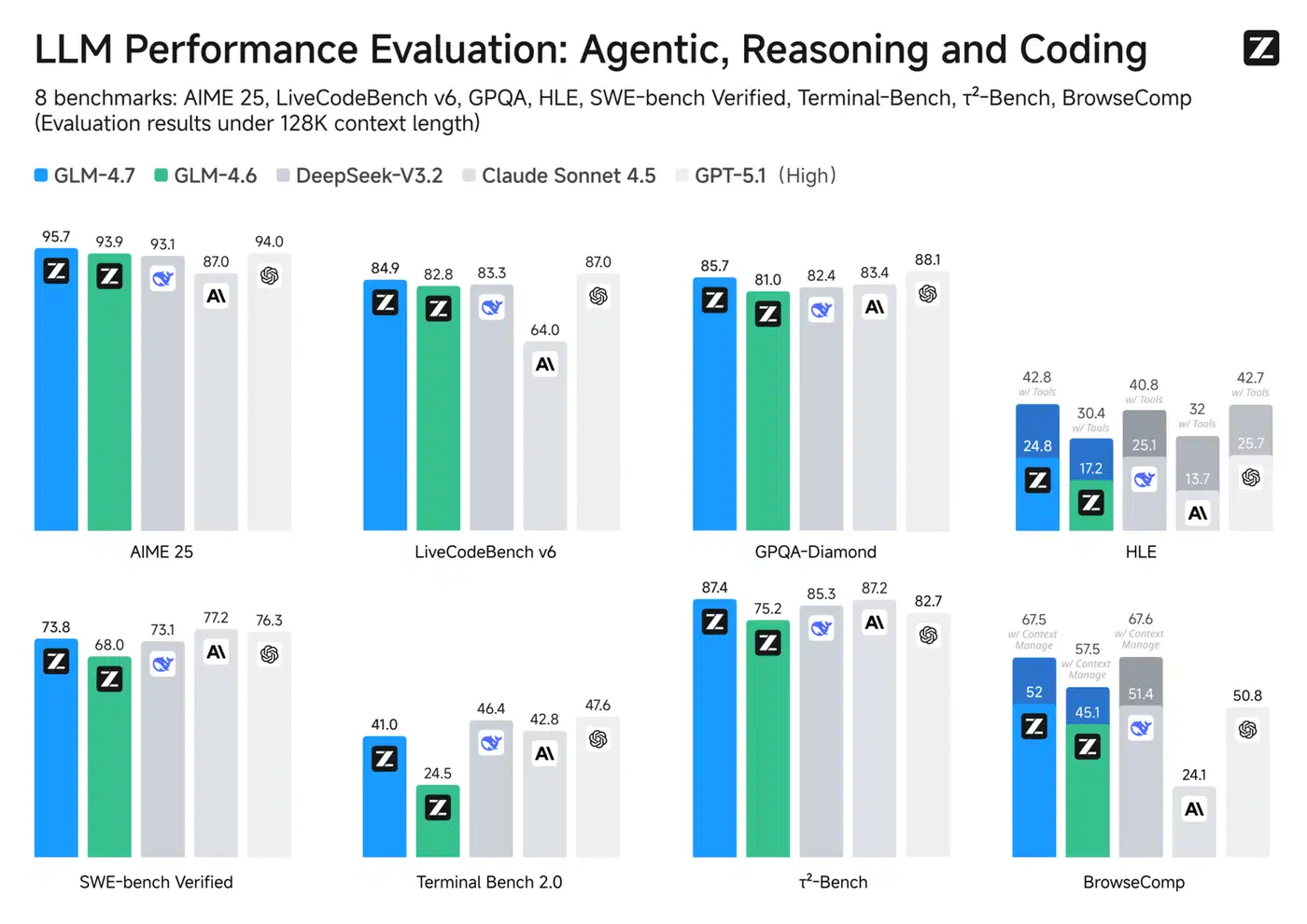
GLM-4.7 from Z.ai (Zhipu) is a 358 billion-parameter MoE under MIT, released December 22, 2025. It scores 73.8 SWE-bench and 84.9 LiveCodeBench with a 200K context. More usefully for home rigs, the GLM-4.7-Flash variant (30 billion total, ~3 billion active) clears 59.2 SWE-bench and was built to run locally.
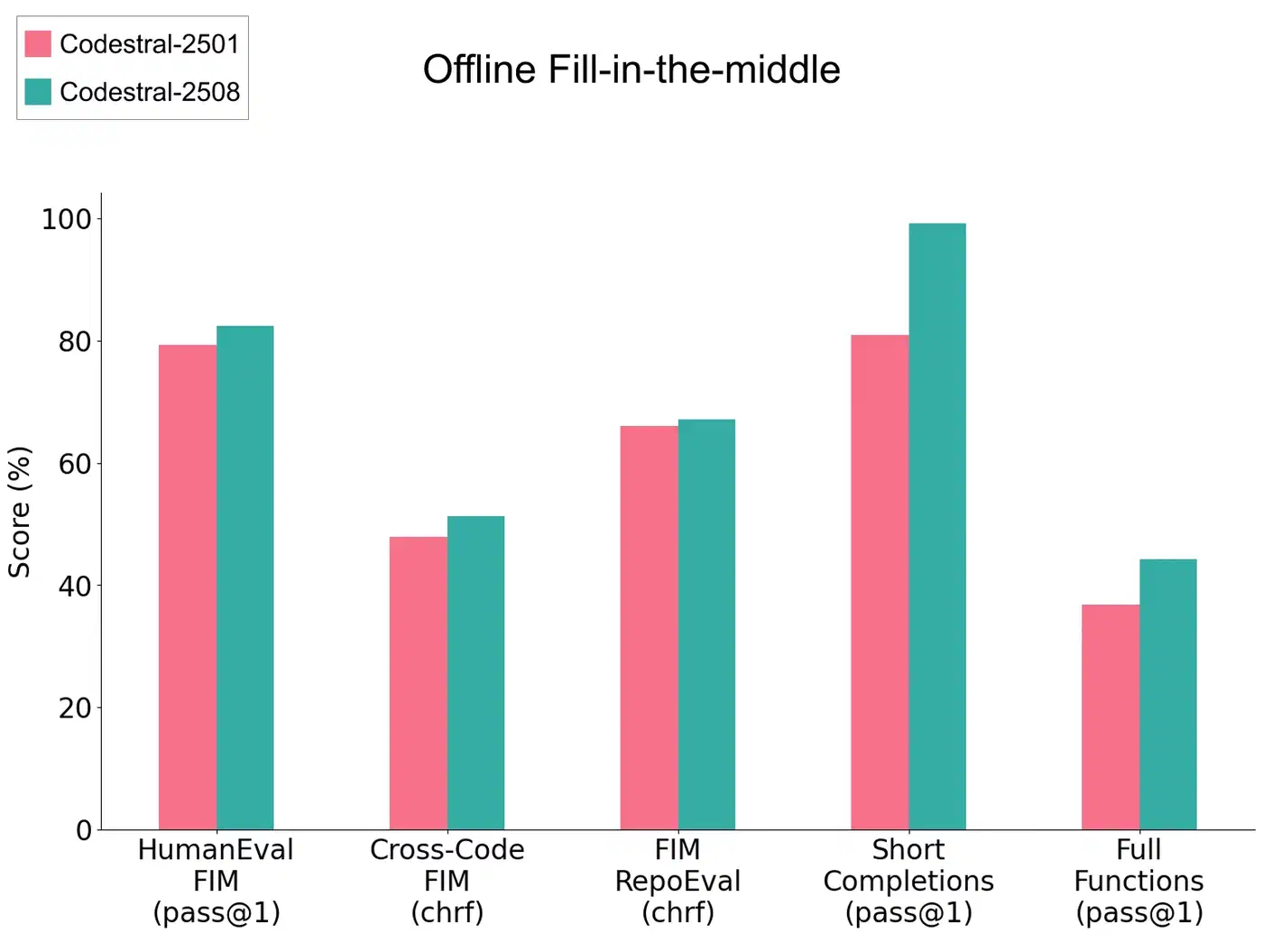
Codestral and Devstral from Mistral split the work. Codestral 25.08 is a 22 billion-parameter fill-in-the-middle (FIM) autocomplete specialist with a 256K context, 80-plus languages, and about 95 percent FIM pass rate. For agentic coding, Devstral Small (24B, Apache 2.0) scores about 53.6 SWE-bench and Devstral Medium about 61.6.
The license story splits too, and it changes what you can ship. Qwen3-Coder, Qwen3.6, and Devstral Small are Apache 2.0. DeepSeek V4 and GLM-4.7 are MIT. Codestral’s weights, by contrast, ship under Mistral’s non-production terms.
| Model | Best coding score (SWE-bench / LiveCodeBench) | Open sizes | Context | Release |
|---|---|---|---|---|
| Qwen3.6-27B | 77.2 / ~84 | 27B dense; 35B-A3B; Qwen3-Coder 30B & 480B | 262K (1M YaRN) | Apr 2026 |
| DeepSeek V4 | 80.6 / 93.5 | V4-Pro 1.6T-A49B; V4-Flash 284B-A13B | 1M | Apr 24, 2026 |
| GLM-4.7 | 73.8 / 84.9 | 358B MoE; GLM-4.7-Flash 30B-A3B | 200K | Dec 22, 2025 |
| Codestral / Devstral | 61.6 (Devstral Medium) / n/a | Codestral 25.08 22B; Devstral Small 24B; Devstral Medium | 256K | 2025-2026 |
One caveat on the scores. HumanEval is largely saturated in 2026 , with frontier models clustered at 91 to 95 percent and only a few points between them. SWE-bench Verified tests multi-file patches against real GitHub issues, so it separates coding models far better. That’s why every ranking here anchors on SWE-bench, not HumanEval.
The Local-Fit Frontier on a 24 GB Card
Here the ranking gets useful. Take the same four families, drop the flagship score, and swap in the smallest variant that actually runs. Then pair it with the quant, the VRAM it needs, and a capability-per-GB verdict. The question is simple: given a 24 GB card, which model gives the most coding ability per gigabyte?
Qwen3.6-27B dense needs about 17 GB at Q4_K_M, which sits comfortably on a 24 GB card. At 77.2 SWE-bench, that works out to roughly 4.5 points per gigabyte. No other model you can run at home matches that ratio, so it takes the top spot.
The Qwen3.6-35B-A3B MoE needs about 19 to 22 GB at Q4_K_M, a tight but workable fit on 24 GB. It scores 73.4 SWE-bench, a touch below the dense model. The payoff is speed: because only about 3 billion parameters fire per token, it streams at roughly 120 tokens per second on a 4090. That makes it the fastest usable option.
GLM-4.7-Flash is the headroom champion. It needs about 15 GB at Q4 and around 22 GB at Q8, so it leaves plenty of room for context. At 59.2 SWE-bench it trails the Qwen pair, but it also drops onto a 16 GB card and even runs well on Apple Silicon , hitting 60 to 80 tokens per second on an M3 Max.
Codestral 25.08 is small enough for a 16 GB card at Q4, around 13 to 14 GB. Still, it’s an autocomplete and FIM specialist, not an agentic issue-solver. Its capability-per-GB verdict is high for inline completion and low for fixing GitHub issues. Judge it on the job it was built for.
DeepSeek V4 and full GLM-4.7 simply don’t fit consumer cards. V4-Pro at 1.6 trillion parameters needs serious hardware even after quantization. V4-Flash at 284 billion wants a multi-GPU box or 150 GB-plus of memory, and the full 358 billion GLM-4.7 is server-class. Their leaderboard scores are irrelevant to the local-fit frontier.
| Model | Smallest usable size | Quant | VRAM needed | Verdict |
|---|---|---|---|---|
| Qwen3.6-27B | 27B dense | Q4_K_M | ~17 GB | Best overall: 77.2 SWE-bench in 24 GB |
| Qwen3.6-35B-A3B | 35B/3B MoE | Q4_K_M | ~19-22 GB | Fastest usable: ~120 tok/s, 73.4 SWE-bench |
| GLM-4.7-Flash | 30B/3B MoE | Q4 | ~15 GB | Most headroom: 59.2 SWE-bench, fits 16-24 GB |
| Codestral 25.08 | 22B dense | Q4 | ~13-14 GB | Autocomplete only: high FIM, not agentic |
| DeepSeek V4-Flash | 284B/13B MoE | Q4 | ~150 GB+ | Does not fit consumer GPUs |
So the ranking for a 24 GB card is clear. Qwen3.6-27B wins on capability per GB. Qwen3.6-35B-A3B wins on speed per GB. GLM-4.7-Flash wins on headroom. Codestral wins only for inline autocomplete.
Open-Weight License Fine Print
Most roundups call all of these models “open” and stop there. The licenses diverge in ways that decide what you can legally ship, so read them before you download weights. Three terms separate the field: commercial use, redistribution, and any field-of-use caps.
MIT covers DeepSeek V4 and GLM-4.7, and it’s the most permissive option here. You get commercial use, modification, redistribution, and fine-tuning with no field-of-use caps. Outputs and distillation are unrestricted. The DeepSeek V4 release ships MIT and the GLM-4.7 model card confirms MIT .
Apache 2.0 covers Qwen3-Coder, Qwen3.6, and Devstral Small. Commercial use is allowed, a patent grant is included, and you must keep attribution and a NOTICE file. There are no distillation or output restrictions, which makes it a safe default for a SaaS product.
Codestral’s weights are the exception. They historically ship under Mistral’s non-production terms, which restrict commercial deployment of the weights themselves. Commercial use runs through Mistral’s API or a separate agreement. If you need local commercial use from this family, Devstral Small is the Apache 2.0 escape hatch.
| Model | License | Commercial use | Notable restriction |
|---|---|---|---|
| Qwen3-Coder / Qwen3.6 | Apache 2.0 | Yes | Attribution + NOTICE file |
| DeepSeek V4 | MIT | Yes | None of note |
| GLM-4.7 / GLM-4.7-Flash | MIT | Yes | None of note |
| Codestral 25.08 | Mistral non-production (weights) | Via API or agreement | Weights not for self-host; use Devstral Small instead |
In concrete terms, the choice is easy. If you want to fine-tune and ship weights inside a commercial product with zero licensing calls, pick Qwen (Apache) or DeepSeek and GLM (MIT). If you only need inline autocomplete and will pay per token, Codestral’s API is fine. You can cross-check any score against the SWE-bench Verified leaderboard before you commit.