DeepSeek V4 Tech Report: 3 Tricks That Cut Compute 73%

DeepSeek V4 is a 1.6 trillion parameter open-weight Mixture-of-Experts model with a 1M token context that uses 27% of V3.2’s inference FLOPs and 10% of its KV cache. The DeepSeek V4 tech report credits three moves: hybrid CSA plus HCA attention, Manifold-Constrained Hyper-Connections, and the Muon optimizer replacing AdamW.
Key Takeaways
- DeepSeek V4 is a free, open-weight AI that goes toe-to-toe with the top closed models from OpenAI, Anthropic, and Google.
- It reads 1 million tokens in one prompt, enough for several full books or a long agent run without losing track.
- It runs on roughly a quarter of the compute its previous version needed, making long-context AI affordable to operate.
- A smaller team built it without access to top NVIDIA chips, proving clever engineering can rival raw GPU spend.
- It scored a perfect 120 out of 120 on the 2025 Putnam math competition and beats Google’s Gemini 3.1 Pro at 1M-token recall.
DeepSeek V4 at a Glance
The official launch announcement on April 24, 2026 framed the release as “the era of cost-effective 1M context length” and shipped two checkpoints under the MIT license: DeepSeek-V4-Pro at 1.6T total / 49B activated parameters, and DeepSeek-V4-Flash at 284B total / 13B activated. Both models support a 1M token context window natively, both ship as open weights on Hugging Face , and the routed expert weights use FP4 precision while most other parameters use FP8.
The structural backdrop is what makes the engineering choices read as forced moves rather than flourishes. DeepSeek operates with a far smaller team than OpenAI, Anthropic, or Google DeepMind, no access to the top NVIDIA SKUs, and far less aggregate compute than its frontier rivals. The paper opens with the constraint stated as a goal:
In order to break the efficiency barrier in ultra-long contexts, we develop the DeepSeek-V4 series, including the preview versions of DeepSeek-V4-Pro with 1.6T parameters (49B activated) and DeepSeek-V4-Flash with 284B parameters (13B activated). Through architectural innovations, DeepSeek-V4 series achieve a dramatic leap in computational efficiency for processing ultra-long sequences.
DeepSeek-AI (DeepSeek V4 tech report, 2026)
The paper reads more like a systems engineering writeup than a scaling-laws update. Every section trades floating-point operations or memory for algorithmic and infrastructural complexity, and the trade-offs come with specific numbers attached.

The Attention Wall: Why 1M Tokens Breaks Vanilla Transformers
The original Vaswani et al. attention mechanism compares every new token against every prior token, which produces quadratic compute cost: 10 tokens means 100 comparisons per step, 100,000 tokens means 10 billion, and 1,000,000 tokens means a trillion. The KV cache architecture problem is the dual: every past token’s key and value tensors live in HBM GPU memory, and at 1M tokens that footprint reaches gigabytes per concurrent request.
FlashAttention and grouped-query attention help, but neither bends the curve enough to make 1M-token long context windows a default rather than a stunt. DeepSeek frames the requirement bluntly:
The emergence of reasoning models has established a new paradigm of test-time scaling, driving substantial performance gains for Large Language Models. However, this scaling paradigm is fundamentally constrained by the quadratic computational complexity of the vanilla attention mechanism, which creates a prohibitive bottleneck for ultra-long contexts and reasoning processes.
DeepSeek-AI (DeepSeek V4 tech report, 2026)
Compute cost and memory footprint must both come down, or a 1M-context model is undeployable at production economics.
Hybrid Attention: CSA, HCA, and a Sliding Window
The architectural core of V4 is a three-pathway attention stack interleaved across layers. Compressed Sparse Attention (CSA) groups every four KV entries into a single compressed entry along the sequence dimension, then uses a “Lightning Indexer” with FP4 attention math to select a top-k of those compressed entries for each query. Heavily Compressed Attention (HCA) is the global-overview pathway: it consolidates every 128 tokens into a single entry and then attends densely over the short resulting sequence. A Sliding Window Attention branch keeps the most recent 128 tokens uncompressed so that local fidelity (numbers, names, code, function arguments) stays exact.
DeepSeek V4 Pro stacks 61 transformer layers and uses HCA in the first two layers, then interleaves CSA and HCA across the remaining 59. CSA selects top-1024 compressed KV entries per query in V4 Pro and top-512 in V4 Flash. The reframing the paper makes explicit:
As the context length reaches extreme scales, the attention mechanism emerges as the dominant computational bottleneck in a model. For DeepSeek-V4, we design two efficient attention architectures: Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA), and employ their interleaved hybrid configuration, which substantially reduces the computational cost of attention in long-text scenarios.
DeepSeek-AI (DeepSeek V4 tech report, 2026)
The design question DeepSeek answers is “how little can we attend to and still understand everything,” and the three pathways together implement a tiered answer: exact recent tokens via the sliding window, sparse selective recall via CSA, and global structure via HCA.
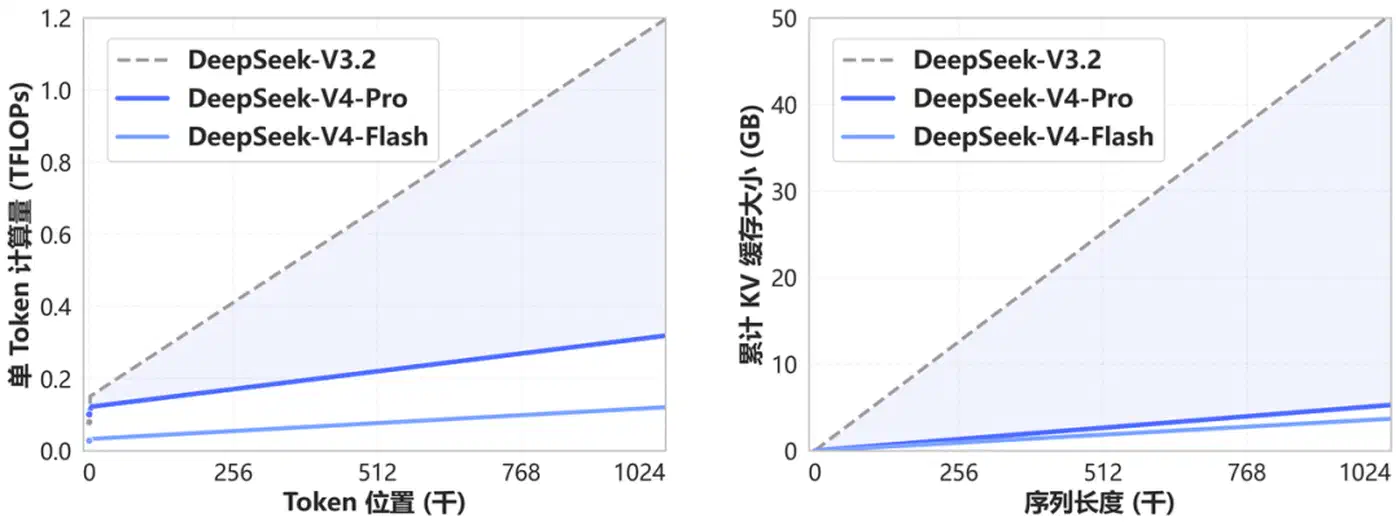
The Efficiency Payoff: 73% FLOP Reduction at 1M Tokens
Compared with DeepSeek V3.2 , V4 Pro at 1M-token context uses 27% of the single-token inference FLOPs and 10% of the accumulated KV cache. V4 Flash, with its smaller activated parameter count, pushes further: 10% of V3.2’s single-token FLOPs and 7% of its KV cache at 1M tokens.
| Metric (1M context) | DeepSeek V3.2 | DeepSeek V4 Pro | DeepSeek V4 Flash |
|---|---|---|---|
| Total parameters | 671B | 1.6T | 284B |
| Activated parameters | 37B | 49B | 13B |
| Single-token FLOPs (rel.) | 100% | 27% | 10% |
| Accumulated KV cache (rel.) | 100% | 10% | 7% |
| Training tokens | - | 33T | 32T |
Against a BF16 GQA8 baseline with head dimension 128 (a common LLM attention configuration), the V4 KV cache shrinks to roughly 2% of baseline size at 1M-token context. Operationally, that translates to lower VRAM per concurrent user, smaller batch-cost ratios, and a credible path to running large open-weight models on consumer GPUs once FP4 throughput catches up to FP8 on future GPU silicon.
Manifold-Constrained Hyper-Connections (mHC): Stopping Trillion-Parameter Models From Exploding
Residual connections are how transformers add layer outputs back to a running signal so gradients can flow during backprop. Hyper-Connections (HC), introduced in the Hyper-Connections paper , widened that residual stream by a factor of n_hc to give the model a complementary scaling axis. At trillion-parameter scale, HC cracks: the residual transformation matrix amplifies signals layer over layer, training crashes with loss spikes, and rolling back to a checkpoint costs millions of GPU-hours.
mHC, introduced in the standalone paper Xie et al. 2026 (arXiv:2512.24880) and folded into V4, constrains the residual mapping matrix B_l onto the Birkhoff polytope: the manifold of doubly stochastic matrices where every row and every column sums to 1. The constraint mathematically bounds the spectral norm at 1, which makes the residual transform non-expansive and guarantees signal stability across deep layer stacks. The paper states the mechanism plainly:
The core innovation of mHC is to constrain the residual mapping matrix B_l to the manifold of doubly stochastic matrices (the Birkhoff polytope) M, and thus enhance the stability of signal propagation across layers. This constraint ensures that the spectral norm of the mapping matrix is bounded by 1, so the residual transformation is non-expansive, which increases the numerical stability during both the forward pass and backpropagation.
DeepSeek-AI (DeepSeek V4 tech report, 2026)
The projection onto that manifold uses the Sinkhorn-Knopp algorithm: exponentiate the raw matrix, then iteratively row-normalize and column-normalize. DeepSeek runs t_max = 20 iterations per layer in production, with an n_hc expansion factor of 4. A 20-step inner loop per layer at trillion-parameter scale sounds catastrophic for runtime, but DeepSeek’s fused kernel, selective recomputation, and DualPipe overlap optimizations bring the total cost down: “Collectively, these optimizations constrain the wall-time overhead of mHC to only 6.7% of the overlapped 1F1B pipeline stage.” Cheap insurance against a crashed training run.
Muon Replaces AdamW for Most Parameters
AdamW has been the industry-default optimizer for large language model training for years: conservative, well-understood, slow to converge at the trillion-parameter frontier. DeepSeek replaced it with the Muon optimizer from Liu et al. 2025 for the majority of V4’s parameters, retaining AdamW only for the embedding module, the prediction head, the static biases and gating factors of mHC, and all RMSNorm weights.
Muon’s core trick is orthogonalizing the gradient update matrix using Newton-Schulz iterations. DeepSeek runs 10 iterations split into two phases: 8 steps with coefficients (3.4445, -4.7750, 2.0315) drive rapid convergence by pushing the singular values toward 1, then 2 final steps with coefficients (2, -1.5, 0.5) lock the singular values precisely at 1. The paper explains the choice straightforwardly:
We employ the Muon optimizer for the majority of modules in DeepSeek-V4 series due to its faster convergence and improved training stability.
DeepSeek-AI (DeepSeek V4 tech report, 2026)
The implementation detail that matters: Muon needs the full gradient matrix, which conflicts with ZeRO sharding . DeepSeek built a hybrid ZeRO bucket assignment that uses a knapsack algorithm for dense parameters and a flatten-pad-distribute scheme for MoE expert parameters, paired with stochastic-rounding BF16 reduction of MoE gradients across data-parallel ranks to halve communication volume.
Communication-Compute Overlap, TileLang, and Z3 Verification
At 1.6T parameters the bottleneck shifts from compute to data movement. Layers shard across many racks, and every forward and backward pass traverses the network. DeepSeek’s MoE Expert Parallelism scheme splits experts into waves and pipelines dispatch, GEMM, activation, and combine across them, so wave-1 GEMMs run while wave-2 dispatches are still in flight. The reported speedup over non-fused baselines is 1.50 to 1.73x for general inference and up to 1.96x for latency-sensitive RL rollouts. The CUDA mega-kernel is open-sourced as MegaMoE , part of the DeepGEMM repository.
The kernels themselves are written in TileLang , a domain-specific language for GPU kernels that DeepSeek co-developed and that ICLR 2026 accepted. TileLang handles host-codegen optimization (CPU-side validation overhead drops from “tens or hundreds of microseconds to less than one microsecond per invocation”) and integrates the Z3 SMT solver for formal integer analysis during compilation. Z3 mathematically verifies kernel correctness for layout inference, memory hazard detection, and bound analysis instead of relying on empirical testing alone:
We integrate the Z3 SMT solver into TileLang’s algebraic system, providing formal analysis capability for most integer expressions in tensor programs. Under reasonable resource limits, Z3 elevates overall optimization performance while restricting compilation time overhead to just a few seconds.
DeepSeek-AI (DeepSeek V4 tech report, 2026)
For training reproducibility, DeepSeek implements bitwise batch-invariant and deterministic kernels end-to-end. Attention uses a dual-kernel decoding strategy that produces bit-identical outputs whether a sequence runs on one SM or many. Matrix multiplication abandons cuBLAS in favor of DeepGEMM with deterministic split-k. Backward passes for sparse attention, MoE, and mHC each use buffered FP32 accumulation rather than atomicAdd to eliminate floating-point non-associativity. Closed labs almost never publish this layer of detail.
Curriculum Training, 33T Tokens, and Anticipatory Routing
V4 Pro trained on 33T tokens, V4 Flash on 32T. Both models use a curriculum that ramps sequence length from 4K through 16K and 64K to the full 1M window, while sparse attention is introduced at the 64K stage after a 1T-token dense-attention warmup. Batch size schedules climb from a small initial size to 75.5M tokens for Flash and 94.4M for Pro, and the peak Muon learning rate is 2.7e-4 (Flash) and 2.0e-4 (Pro), decayed cosine-style to 10x lower at the end.
The new stability trick is Anticipatory Routing. Rolling back to a checkpoint when loss spikes does not address the root cause. DeepSeek instead found that loss spikes correlate with outliers in MoE layers, and that the routing mechanism itself amplifies those outliers in a feedback loop. The fix is to decouple routing decisions from the current network state:
We found that decoupling the synchronous updates of the backbone network and the routing network significantly improves training stability. Consequently, at step t, we use the current network parameters for feature computation, but the routing indices are computed and applied using the historical network parameters. We “anticipatorily” compute and cache the routing indices to be used later at step t, which is why we name this approach Anticipatory Routing.
DeepSeek-AI (DeepSeek V4 tech report, 2026)
An automatic detector triggers Anticipatory Routing only when a loss spike is detected, runs it for a window, then hands control back to standard real-time routing. Total wall-clock overhead is bounded to roughly 20%, but it averts loss-spike rollbacks entirely. SwiGLU clamping, where the linear component is clamped to [-10, 10] and the gate component capped at 10, complements the routing fix by directly suppressing numerical outliers.
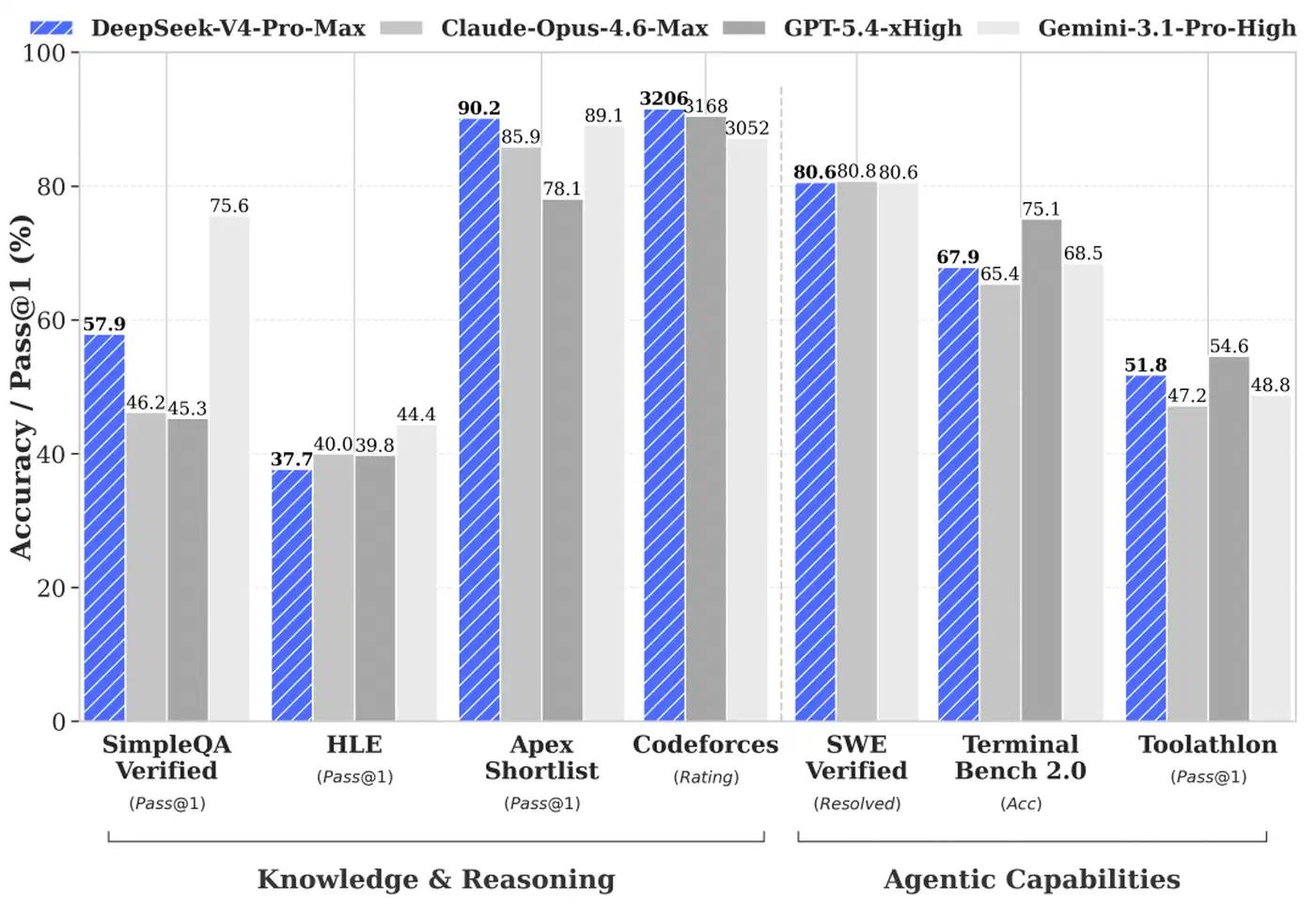
Benchmarks: How V4 Pro Max Compares With Frontier Closed Models
DeepSeek V4 Pro Max is the maximum-reasoning-effort mode of V4 Pro and is the configuration the paper benchmarks against frontier closed models. All numbers below are self-reported by DeepSeek’s internal evaluation framework, so independent reproduction on Artificial Analysis, LMSys Arena, and Aider Polyglot is worth waiting for before treating any of this as settled.
| Benchmark | V4 Pro Max | Opus 4.6 Max | GPT 5.4 xHigh | Gemini 3.1 Pro High |
|---|---|---|---|---|
| MMLU-Pro (EM) | 87.5 | - | - | - |
| GPQA Diamond (Pass@1) | 90.1 | - | - | - |
| LiveCodeBench (Pass@1-COT) | 93.5 | - | - | - |
| SimpleQA-Verified (Pass@1) | 57.9 | 46.2 | 45.3 | 75.6 |
| Codeforces (Rating) | 3206 | 3168 | 3052 | - |
| SWE Verified (Resolved) | 80.6 | 80.8 | 80.6 | - |
| Terminal Bench 2.0 | 67.9 | 75.1 | 68.5 | 65.4 |
| MRCR 1M (MMR) | 83.5 | - | 76.3 | - |
| HLE (Pass@1) | 37.7 | - | - | - |
Two results stand out. On Putnam-2025, evaluated under a hybrid formal-informal regime with substantial compute scaling, DeepSeek V4 reached a proof-perfect 120/120, matching the Axiom system and beating Aristotle (100/120) and Seed-1.5-Prover (110/120). On MRCR 1M, DeepSeek V4 Pro Max scored 83.5 MMR, beating Gemini 3.1 Pro at 76.3 at the absolute extreme of the 1M context window, although Claude Opus 4.6 still leads on this benchmark. On reasoning, the paper places V4 Pro Max above GPT-5.2 and Gemini-3.0-Pro on standard benchmarks but a half-generation behind GPT-5.4 and Gemini-3.1-Pro: “approximately 3 to 6 months” of catch-up, in the paper’s words.
For Chinese writing, DeepSeek V4 Pro hits a 62.7% win rate against Gemini 3.1 Pro on functional writing and 77.5% on creative writing quality, though Claude Opus 4.5 wins 52% to 45.9% on the most complex multi-turn prompts.
Limitations and Who Should Skip This
- DeepSeek V4 still trails frontier closed models on knowledge-intensive evaluations (MMLU-Pro, GPQA, HLE), with the paper acknowledging a roughly 3 to 6 month developmental lag against Gemini-3.1-Pro.
- The 1.6T total parameters mean self-hosting V4 Pro is impractical without multi-node infrastructure even at FP4 quantization. V4 Flash at 284B is the realistic on-prem target.
- Most benchmark numbers in the tech report are self-reported. Independent leaderboards (Artificial Analysis, LMSys, Aider Polyglot) had not posted full V4 results as of May 2026.
- Claude Opus 4.6 still beats V4 Pro Max on MRCR 1M retrieval and on Terminal Bench 2.0 agent tasks. For agentic coding workflows, the Claude Opus closed-model gap is real.
- The hybrid attention KV cache layout (state cache plus block cache, with separate SWA and CSA/HCA segments) is not yet supported by stock vLLM or SGLang releases without DeepSeek’s patches.
What This Means for Open-Weight AI
DeepSeek shipped the weights, the architecture paper, the MegaMoE kernel inside DeepGEMM, the TileLang DSL, the standalone mHC paper, and the Muon implementation details. Closed labs treat parallelism strategies, optimizer choices, and kernel-level tricks as trade secrets. DeepSeek published the recipe.
The open question is how much of frontier model capability is actually compute-bound versus idea-bound. V4 is the strongest data point yet that the gap can close with engineering, even when the compute side of the ledger is shorter by an order of magnitude. With MIT-licensed weights, every result here is reproducible and the published kernels are reusable in other training stacks today.
FAQ
How much VRAM do I need to self-host DeepSeek V4 Pro?
What is the difference between V4 Pro Max and V4 Pro?
<think> and </think> tokens in the chat template.Why does mHC use 20 Sinkhorn-Knopp iterations and not fewer?
How does the 1M context window actually work in practice?
Is V4 better than Claude Opus 4.6 or GPT 5.4?